本文转载自微信公众号「数仓与大数据」,作者otw30。转载本文请联系数仓与大数据公众号。
0x00 前言
在之前的文章,我们规划了数仓架构,制定了数仓规范,然后在架构和规范的指导下设计了存储模型、构建了 ETL 系统。
数仓模型解决了数据存储问题,ETL 解决了数据同步集成计算问题,而调度解决的是自动化问题。
我们通过配置调度去周期性定时触发执行各种任务或流程(同步、集成、计算、校验、测试等)并监控他们的运行情况,及时、保质、自动化的满足各种数据使用需求。
最后调度还有一个附加的用途,对于新接手的维护项目,我们想要快速了解其数据流转,线上运行的调度任务就是最好的切入点了。
0x01 我接触过的调度场景
场景一、数据开发
这是一个非常热门的招聘岗位。
在之前主要是指数据库开发,大概的工作内容是基于关系型数据库(Oracle、DB2、SQL Server 等)通过写 SQL/存储过程等来实现业务需求。
大数据时代的数据开发,即大数据开发,主要是使用大数据组件实现业务需求,可以是离线计算 Hive/Spark 等,也可以是 Spark Streaming/Flink/Kafka 等。
在数据仓库场景,有叫数仓开发/ETL 开发,当然也有很多直接叫数据开发的。大数据时代很少有叫 ETL 开发了,直接就是数据仓库工程师/大数据开发工程师。
好了,不管叫法怎么变,我们都可以称自己为数据工程师,我们的工作职责就是使用各种技术去实现业务需求,业务需求多了又都需要周期性的跑数据,这时候就需要配置调度了。
场景二、对账系统
做为一个企业,跟客户/供应商之间肯定有不少业务往来,而且很多都是通过各自的信息化系统实现的。比如通过支付宝购买电影票,每月固定日期支付宝跟影院都要进行对账。我们可以创建各种各样的对账任务,然后配置调度去周期性的拉取双方的购票数据进行比对。
场景三、DMP 人群包自动化生成
这个是我之前做过的一个系统,业务人员通过页面框选人群,系统后台自动化离线计算,人群包生成后返回通知。为防止同一时间点启动过多的计算任务,所有任务统一提交到调度中心,调度中心会根据计算资源负载来决定是执行任务还是等待。对于周期性的人群包生成需求,我们还可以配置定时任务。
场景四、Yarn 任务调度
在大数据集群,Yarn 是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度。当计算任务到来时候,如果空闲资源足够则立即执行,否则就阻塞等待。
0x02 常见的调度实现方案
方案一、借助操作系统或数据库
这种方式的优势在于不需要专门安装配置、非常稳定、使用方便。在一些规模较小的系统非常建议使用。

这是 linux 系统自带的调度,最小调度频率是分钟级别,直接触发执行指定的 Shell,在脚本内实现任务依赖、记录日志等操作。
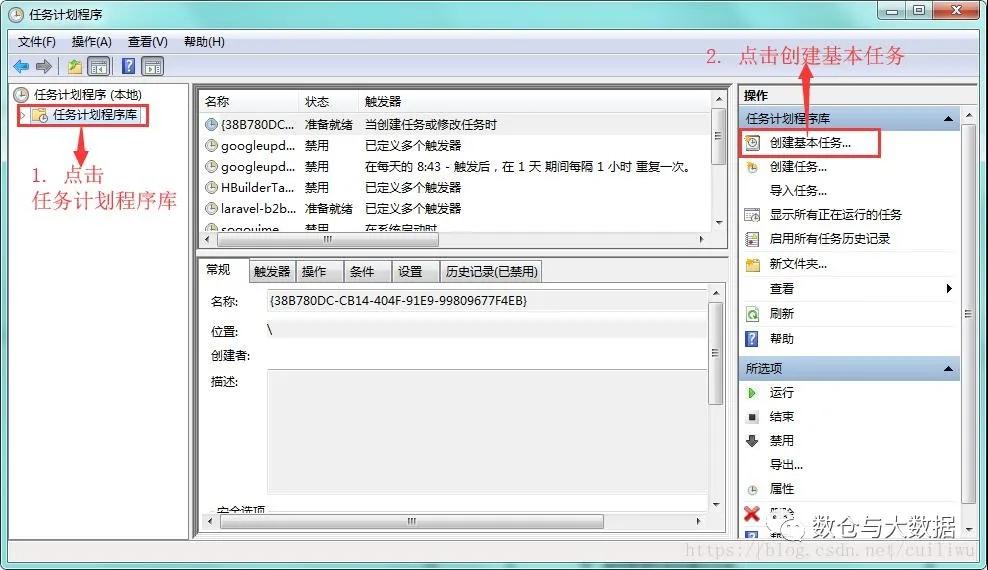
这是 windows 系统自带的调度,最小调度频率也是分钟级别,直接触发执行指定的 bat 脚本,在脚本内实现任务依赖、记录日志等操作,同时该操作 windows 会提供一套可视化页面来配置查看运行调度任务以及调用日志。
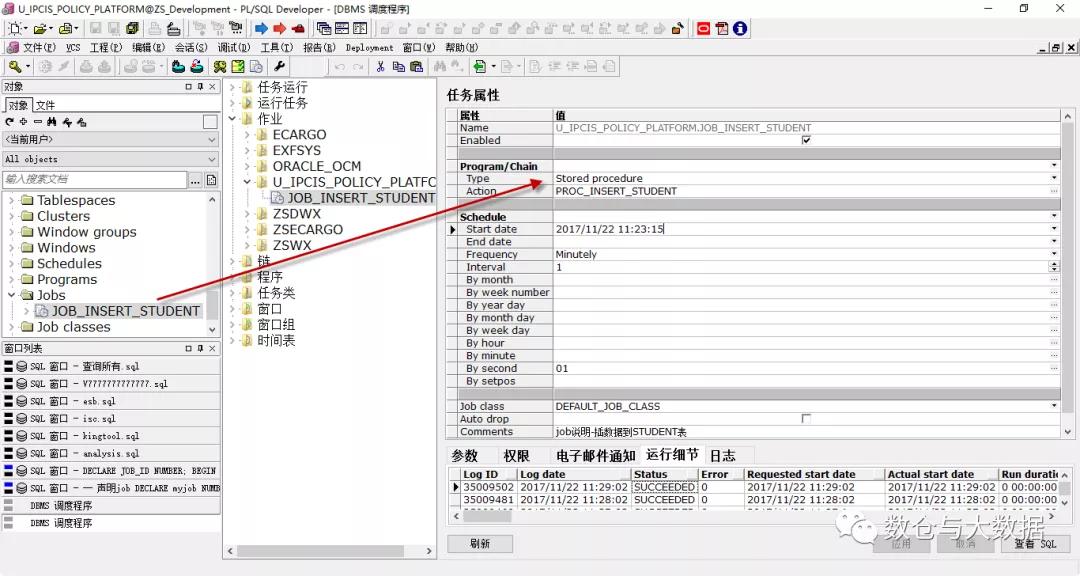
上边截图是 Oracle 数据库自带的调度。Oracle 数据库调度分两个版本,在 Oracle 10g 之前功能还很简单,只能调用自己的存储过程。10g 以后还可以调度 shell/bat 脚本,并且配置更方便了。
配置好的调度,其调用日志以及调度计划,会在一张 Oracle 元数据表中记录起来。事实上,Oracle 服务自身也有一个自带的调度程序用来维护数据库自身。
方案二、自主开发
调度这个事情使用场景特别广泛,但是每个场景或者每家公司使用的功能有多又少,比如有的只需要能稳定的定时调度即可,有的还需要实现跨服务器调度、监控告警、流程依赖控制、可视化配置等等。
可能是感觉市面上可选的工具都不足以满足个性化的需求,不少公司会选择自主研发,利用多线程和定时器,或者基于一些底层开源工具进行深度封装。我们之前做对账系统就是 java 封装的 quartz。
这里有篇介绍底层调度工具的文章。需要自主研发的朋友,可以看看 "JavaBoy" 怎么说:
分布式定时任务调度系统技术选型
方案三、选用调度工具
借助操作系统或数据库这种方式稳定性最高,但只适合单一计算场景并且调度任务不是很多的场景。
- 如果所有计算都在同一数据库内就可以使用数据库本身的调度。
- 如果所有计算调用都能够集中到同一台服务器内完成,我们就可以用操作系统自带的调度。
自主研发的方式适用于个性化程度很高、调度性能并发要求不太高、或者功能相对少且自身有研发能力的场景。
虽然调度本身不是一个特别难实现的事情,很多公司可能都有过这种经历。但是想把它做到极致,具备稳定、易用、功能完备、高性能、高并发、高适应性等各方面都不错的程度,还是很难的。能用和好用/通用之间要走的路还有很多。海豚调度这两年能够迅速得到市场认可,但可能大家不知道的是,易观将其开源之前内部研发迭代了至少五年了,照样其开源后仍有一部分人觉得不好用呢。
下边这篇是博哥总结的常见大数据调度系统的介绍,大家可以看一下:
大数据调度系统选得好,下班回家早;调度用得对,半夜安心睡
0x03 调度的功能需求介绍
基础功能
定时调用:根据每个任务配置的执行时间点启动任务,可以是一次性的也可以是周期性的。
参数传递:复杂的 ETL 任务,可能会有一级任务、二级任务、三级任务等等,必须设置一些参数来支持过期重跑、补数等场景。而且最好设置成外部的参数可以覆盖内部的(这跟程序开发的逻辑正好相反),防止开发/测试人员设置的子任务参数上线时候忘记删除造成不必要的问题。
跨服务器调用:很多 ETL 工具也都具备定时调度和参数传递的功能,但跨服务器调用就是调度工具所特有的了。拥有跨服务器调用能力后,可以真正的将整个数据流转串联起来,比如我们的数据集成同步任务、数仓内的主体 ETL 任务、对外推送任务,三者经常是分开部署的。
任务编排:正常的任务编排应该在 ETL 系统里完成,但涉及到跨集群任务依赖的场景,就必须使用调度工具了。
扩展功能
满足了以上四点基础功能后,基本就能满足日常的调度需求了。
如果还想更进一步,可以考虑实现如下功能:
可视化配置:所有调度功能配置都通过系统页面添加和展示。
权限管理:每个人都分配独立账号,任务创建时候可以分配只读或可执行权限给指定的角色。
自动错误重试:这里的重试,是针对某些网络、服务宕机或者计算资源不足等问题造成的错误,可以通过自动重试处理。
任务执行情况日志记录:每一步任务都会记录运行日志,比如开始时间、结束时间以及ETL程序打印的日志,方便事后检查。
告警通知:任务失败后,根据告警规则触发告警。任务完成后不管成功还是失败都可以将执行情况告诉指定的人。通知的作用有 2 点:第一,确保任务真的执行了;第二,可以在通知消息体内发送必要的业务数据如运营日报。
任务暂停:该功能我看海豚调度也有实现,可能是在任务开发/测试时候能用到吧。
并行补数:这在计算资源充足的情况下还是很好用的,但要切记:对于前后日期间有依赖的任务不能使用此功能,比如影片的累计票房计算。
个性化功能
比如我们之前的调度工具,即做了调度的事情,也做了 ETL 的事情。因为我们还实现了这几个功能:数据源连接、SQL 编辑器、字段映射等等。
0x04 调度的并发稳定性要求
对于少量的任务,只需要满足功能性需求,然后简单易用即可,但当任务数量多到一定程度,就不得不考虑高并发和稳定性这些需求了。
调度系统不同于计算引擎,不需要考虑算力问题,只需要按时启动任务,并监控任务的执行情况即可,但当瞬时在线任务过多时候,在线任务的维护以及后续新启动任务的处理,是设计的重点,我们需要优化程序尽可能的提高瞬时在线任务的个数,同时当后续有新启动任务的时候考虑放入等待队列中,以此保证调度的稳定性。
稳定性的另一处保障机制,就是 master 和 worker 的 HA 设计了,当调度节点真的挂掉的时候可以启动新的节点来自动恢复任务。
最后,如果想进一步了解调度系统的设计,包括架构和功能实现的话,可以关注下 DolpinScheduler ,网上资料很多,熟悉 Java 的朋友也可以下载源码看看,相比于 Flink/Spark 等大数据组件,海豚调度的代码还是相对简单些的。
对 DolpinScheduler 感兴趣的,可以点击阅读原文直达中文社区,文档写的还是很全面的。