随着持续部署(Continously Deployment)在项目中的使用,之前定期或者固定时间的发布节奏变为了随时高频率的发布。这就要求每次发布都应该是零停机部署(Zero Downtime Deployment),否则将会引入bug。k8s中有一套完整的机制保证我们的应用能够实现零停机部署,本文将重点分析其中的优雅退出部分。
本文需要对k8s的架构和核心组件的职责有一定的了解,如不了解可参考 Kubernetes Components。
发现问题
对于Kubernetes Deployment的每次部署过程,都是新版本的Pod创建、老版本的Pod删除的过程。
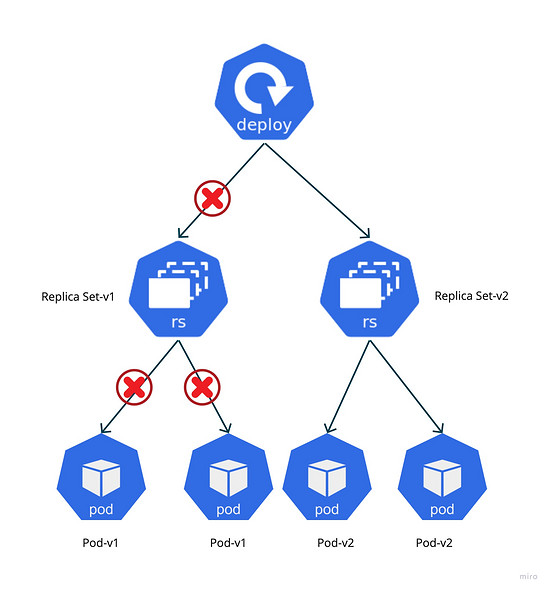
在这个过程中如果不使用优雅退出,则会引发两个问题:
- 问题1:可能会出现Pod未将正在处理的请求处理完成的情况下被删除,如果该请求不是幂等性的,则会导致状态不一致的bug。
- 问题2:可能会出现Pod已经被删除,Kubernetes仍然将流量导向该Pod,从而出现用户请求处理失败,带来比较差的用户体验。
分析问题
在Kubernetes Pod 的删除过程中,同时会存在两条并行的时间线,如下图所示,其中一条时间线是网络规则的更新过程,另一条时间线是Pod的删除过程。
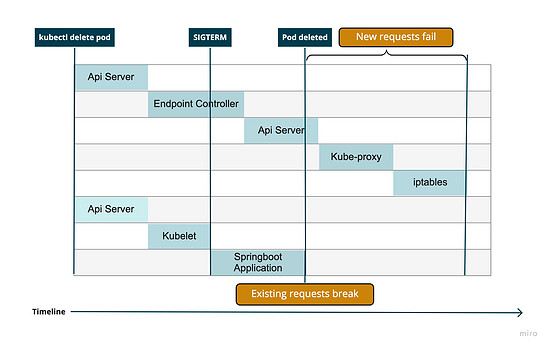
当用户执行 kubectl delete pod 命令时,
网络规则生效流程:
- Kube-apiserver会收到Pod删除的请求,在Etcd中更新Pod的状态为Terminating;
- Endpoint Controller将该Pod的ip从Endpoint对象中删除;
- Kube-proxy根据Endpoint对象的改变更新iptables规则,不再将流量路由到被删除的Pod。
Pod删除流程:
- Kube-apiserver 会收到Pod删除的请求,在Etcd中更新Pod的状态为Terminating;
- Kubelet在节点上清理容器的相关资源,例如存储,网络;
- Kubelet发送SIGTERM进程给容器,如果容器中的进程未做任何配置,则容器立即退出;
- 如果容器未在默认的30秒时间内退出,Kubelet发送SIGKILL给容器,强制让容器退出。
从Pod的删除过程可以知道,如果不对容器内的进程进行任何配置,容器会立即退出,会导致问题1出现。
由于网络规则的更新和Pod的删除是并行的,所以并不能保证网络规则的更新时间一定会早于Pod的删除时间,所以,有可能出现问题2。
解决问题
如果要解决以上两个问题,我们需要做如下配置
-
设置容器中进程的优雅退出;
-
增加preStopHook;
-
修改terminationGracePeriodSeconds。
配置后的时间线如下图所示:
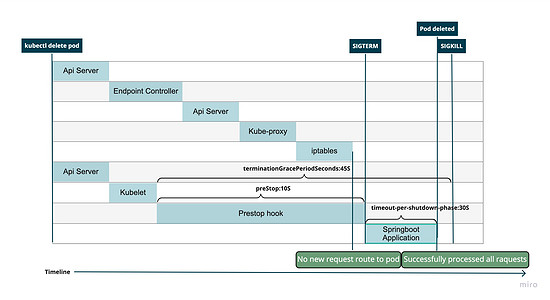
设置容器中进程的优雅退出
在我们项目中,使用的是Springboot,只需要在Springboot的配置文件中增加配置
- server:
- shutdown: graceful
- spring:
- lifecycle:
- timeout-per-shutdown-phase: 30s
进行该配置后,Springboot会保证在接收到SIGTERM之后不会再接受新的请求[^1], 并在超时时间内处理完所有正在处理的请求,如果不能处理完成,也会打印出相应的信息并强制退出。超时时间的具体值应该参考系统中最大允许的请求时长,所以理论上所有的请求都应该在30s内处理完,对于没有在30s内处理完成的请求,我们可以通过监控日志然后发Alert的方式,根据实际情况去处理。通过增加此配置,可以解决问题1。对于使用其它的语言和框架的项目,应该也存在类似的配置。
增加preStopHook
针对问题2,需保证网络规则更新后,也就是说新的流量不再路由到要删除的Pod后,再开始Pod的删除。所以需要在 Kubernetes 的Yaml文件中增加 preStopHook[^3],让Kubelet接收到Pod删除事件后等待一段时间,给Kube-proxy足够的时间更新iptables网络规则后,再开始删除Pod。
- lifecycle:
- preStop:
- exec:
- command: ["sh", "-c", "sleep 10"] # set prestop hook
这里在我们项目中设置的10s是参照Springboot官网的配置[^2]。
修改terminationGracePeriodSeconds
参照之前分析的Pod删除的流程,Kubernetes会给容器最大的删除时长是30秒[^3],如果我们在Spring中优雅退出的超时时长和在Kubernetes中的preStopHook时长大于30s,则可能会出现Springboot还未处理完所有的请求Kubernetes已经开始强制删除容器。所以如果这个时长大于30秒,我们需要修改 terminationGracePeriodSeconds使其大于Springboot的优雅退出超时时间和preStopHook之和
- terminationGracePeriodSeconds: 45
最终Kubernetes中的Yaml文件如下所示:
- apiVersion: apps/v1
- kind: Deployment
- metadata:
- name: graceful-shutdown-test-exit-graceful-30s
- spec:
- replicas: 2
- selector:
- matchLabels:
- app: graceful-shutdown-test-exit-graceful-30s
- template:
- metadata:
- labels:
- app: graceful-shutdown-test-exit-graceful-30s
- spec:
- containers:
- - name: graeceful-shutdonw-test
- image: graceful-shutdown-test-exit-graceful-30s:latest
- ports:
- - containerPort: 8080
- lifecycle:
- preStop:
- exec:
- command: ["sh", "-c", "sleep 10"] # set prestop hook
- terminationGracePeriodSeconds: 45 # terminationGracePeriodSeconds
可以看出,通过设置Springboot的优雅退出,保证了正在处理的请求能够处理完成,通过设置preStopHook,保证了Pod删除和网络规则更新的时序关系。通过配置terminationGracePeriodSeconds,给了容器中进程足够的时间处理所有的请求。综合以上三个步骤,可以解决之前发现的两个问题。
总结
本文通过结合Kubernetes的优雅退出和Springboot的优雅退出机制,保证在随时高频率部署的情况下,服务也可以正确处理所有的请求,减少了bug的出现,提升了用户的体验。