大家好,我是Python进阶者。
前言
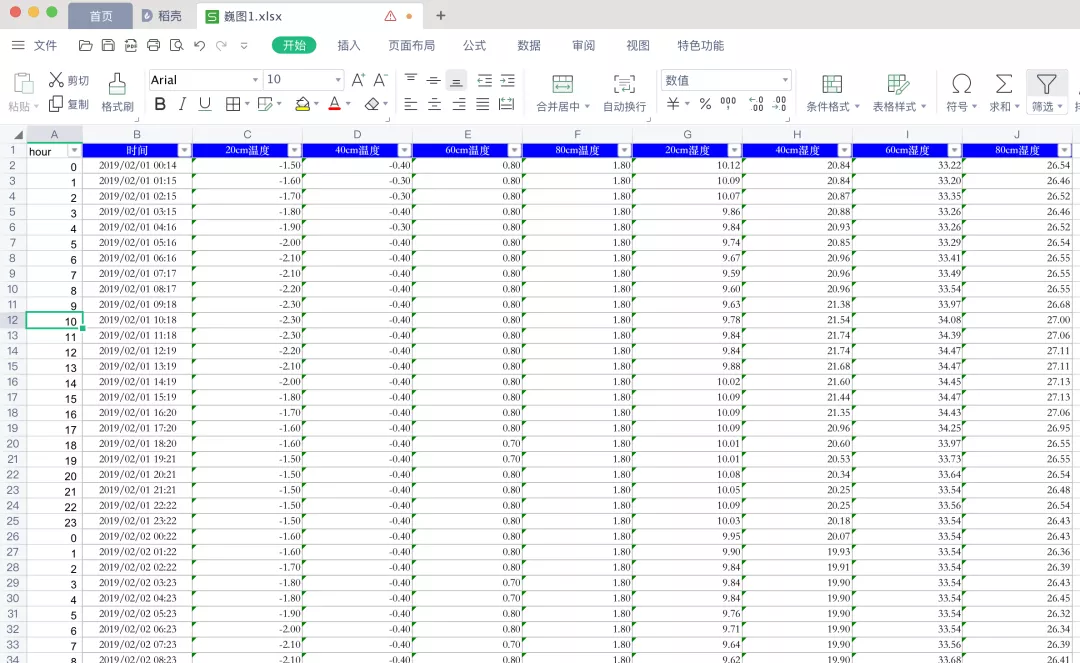
前几天有个叫【Lcc】的粉丝在Python交流群里问了一道关于从Excel文件中提取指定的数据并生成新的文件的问题,初步一看确实有点难,不过还是有思路的。她的目标就是想提取文件中A列单元格中数据为10的所有行,看到A列的表头是时间,10就代表着上午的10小时,也就是说她需要提取每一天中的上午10点钟的数据。这个数据在做研究的时候还是挺有用的,之后结合作图,就可以挖掘出部分潜在规律了,这个在此不做深究。
一、思路
这个问题看似简单,直接用Excel中的筛选就可以了。诚然,数据筛选,之后扩展行确实可以做到,针对一个或者两个或者10位数以下的Excel文件,我们尚且可以游刃有余,但是面对成百上千个这样的数据文件,怕就力不从心了,如果还是挨个进行处理,那就难受了,所以用Python来批量处理还是很奈斯的。下面一起来看看吧!
二、解决方法
其实这个问题和转载刘早起之前的那篇文章处理思路一模一样,Python办公自动化|批量提取Excel数据,感兴趣的话,可以戳链接看看,只不过稍微有些改变,把那个判断条件改为等于就可以了,下面直接上代码。关于代码的详细解析,可以参考上面提到的文章,这里不做赘述。
# coding: utf-8
from openpyxl import load_workbook, Workbook
# 数据所在的文件夹目录
path = 'C:/Users/pdcfi/Desktop/xiaoluo'
# 打开数据工作簿
workbook = load_workbook(path + '/' + '巍图1.xlsx')
# 打开工作表
sheet = workbook.active
buy_mount = sheet['A']
row_lst = []
for cell in buy_mount:
if isinstance(cell.value, int) and cell.value == 10:
print(cell.row)
row_lst.append(cell.row)
new_workbook = Workbook()
new_sheet = new_workbook.active
# 创建和原数据 一样的表头(第一行)
header = sheet[1]
header_lst = []
for cell in header:
header_lst.append(cell.value)
new_sheet.append(header_lst)
# 从旧表中根据行号提取符合条件的行,并遍历单元格获取值,以列表形式写入新表
for row in row_lst:
data_lst = []
for cell in sheet[row]:
data_lst.append(cell.value)
new_sheet.append(data_lst)
# 最后切记保存
new_workbook.save(path + '/' + 'xiaoluo_符合筛选条件的新表.xlsx')
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
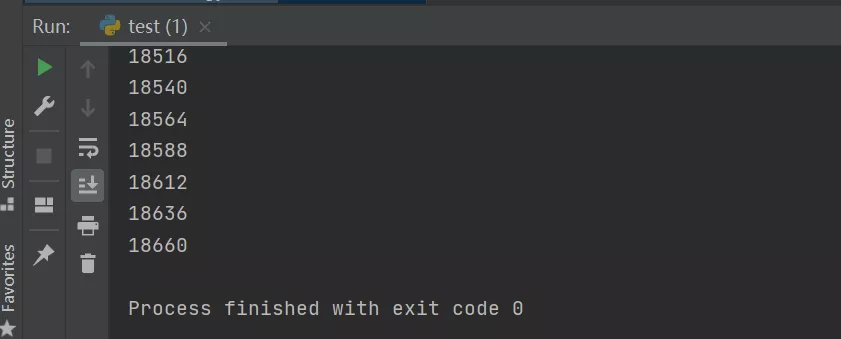
之后在本地查看结果,可以看到,符合条件的数据全部都被提取出来了。

2)注意
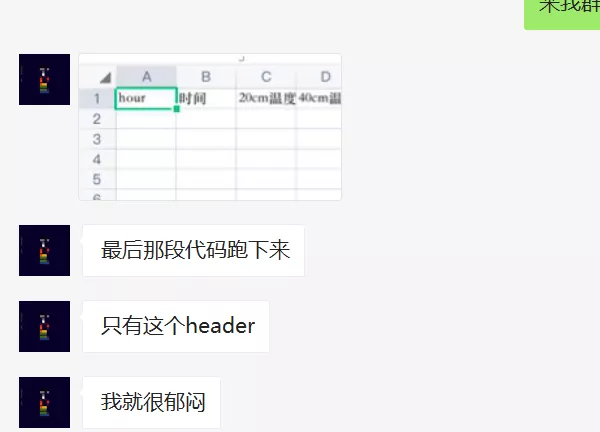
还记得上图中粉丝说自己提取到的数据为啥只有header,而没有数据么?其实这里有个坑,隐藏在她的原始数据中,请看下图。
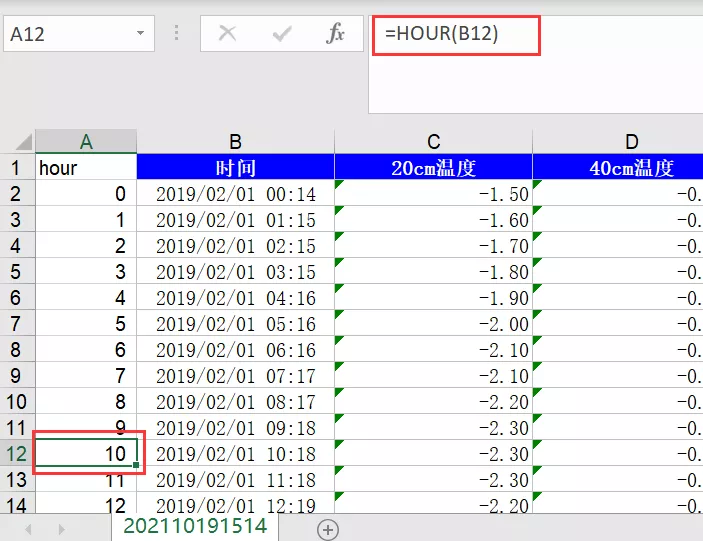
A列的数据是从B列取的,是引用,所有等到访问的时候,其实是获取不到的,所有导致我们去读取的时候,查找的cell为空,自然我们就无法提取到数据。
针对这样的情况,这里给出两个方案,其一是将A列,复制粘贴,粘贴类型为"值",然后重新保存excel进行读取就可以搞定了;其二是以B列作为索引,进行时间取值,然后创建新的一列,之后再做提取,实现难度稍微大一些,取时间的代码可以参考。
df_raw['时间'] = pd.to_datetime(df_raw['时间'], format='%Y-%m-%d').hour
- 1.
本文用的是第一种方法,其实第二种方法显得更加智能一些,难度稍微大一些,实现方法大家可以踊跃的尝试下。
三、总结
我是Python进阶者。本文基于粉丝提问如何从Excel文件中提取指定的数据并生成新的文件的问题,给出了两种解决方案。
针对这个问题,小编这里整理了两个思路,当然方法肯定远远不只是这两种!