













大家好,我是强哥。一个热爱暴走、读书、写作的人!
推荐算法从业者肯定知道,在企业级推荐系统中,一般将推荐算法业务流程拆分为召回和排序两个阶段(有些公司还将排序分为粗排和精排,我们这里不加区分了,见下面图)。为什么这么做呢?这样做有什么好处吗?将推荐算法流程分为召回和排序两个阶段,好处是非常多的,本文我们就从多个角度来解释这么做的价值主要体现在哪里。
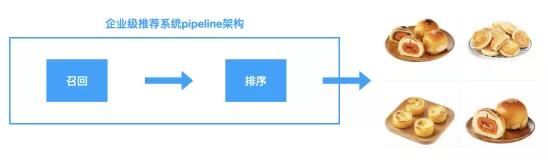
在讲解之前,简单说一个召回和排序这两个阶段分别解决的问题,方便大家更好地理解下面的讲述。召回就是采用比较多的方法和策略从物品库中将用户可能喜欢的物品挑选出来,一般召回的是几十到几百个物品。排序阶段是将不同召回算法获得的结果采用一个统一的模型进行重新打分排序,将得分最高的几十个作为最终的物品推荐给用户。通过召回,我们事先就从海量的全物品库中过滤出了少量的用户可能喜欢的物品了,这大大减少了排序阶段需要处理的物品数量。
讲解完了召回和排序两个阶段的作用,下面我们从4个维度来说明企业级推荐算法流程为什么拆解为召回和排序两个阶段。
1. 推荐算法流程解耦合
我们知道推荐系统是一个偏工程的计算机与机器学习的交叉学科,那么软件工程的一些思路和做法也是适合推荐系统的。将推荐算法流程拆分为召回和排序两个阶段,那么推荐算法就分解为两个相对独立的子系统了。我们可以分别对每个子系统进行迭代、优化、升级,出了问题也方便我们去分析、定位、排查、修复、优化。总之,拆分为两个系统,更易于进行系统开发与维护。软件工程的思路就是分而治之的思路,这个做法是跟软件工程的思路一脉相承的。
2. 有利于团队的分工协作
将推荐算法流程拆分为召回、排序两个阶段,这对于规模比较大的算法团队,也方便进行更精细化的任务安排和人员职能分派。让不同的人聚焦在某一个小的领域,这样更容易让员工在这个方向上做到极致。毕竟召回、排序的思路、方法、策略还有有差异的,让不同的人分工做不同的模块,更聚焦。
3. 可实现性上的考虑
随着深度学习技术的发展,我们知道深度学习技术等复杂推荐模型可以达到比传统模型好得多的推荐效果。因此,大家肯定愿意去尝试更复杂的模型。但是复杂的模型在特征预处理、推断时间花费、推荐服务延迟等方面相对传统简单的模型有更高的要求。这里举个推断时间花费的例子,在一个用户规模和物品规模都非常大的应用场景中(比如抖音、淘宝等),用一个复杂的深度学习模型去对每个用户物品组合进行打分是非常耗时的,也是不现实的。如果召回阶段事先筛选出了少量的用户可能喜欢的物品,那么排序阶段的工作量就小了很多了。
另外,目前信息流推荐是推荐系统的标配技术了,在实时推荐场景下,对时效性的要求就更高了。推荐算法进行拆解对于近实时完成推荐推断过程是非常关键、必不可少的。
4. 提升推荐精准度上的考虑
将推荐算法流程拆分为召回和排序两个阶段。那么每个阶段可以解决本阶段的核心问题。最终可以更好地提升推荐的精准度。下面分别加以说明。
推荐系统召回阶段的主要目标是将用户可能喜欢的物品筛选出来,目的是不要漏掉用户可能会喜欢的物品。一般召回阶段可以采用很多的方法进行召回,比如基于内容标签的召回、基于用户画像的召回、基于用户最近行为的召回、基于热门的召回、基于地域(或者位置)的召回、基于特殊事件的召回、基于时间的召回、基于协同过滤的召回等等(参考下图)。不同召回算法考虑的是用户兴趣点的某个方面,那么用多种召回算法就可以更好地覆盖用户更多样化的兴趣点,最终将用户所有喜欢的物品筛选出来,避免遗漏掉重要的兴趣点。
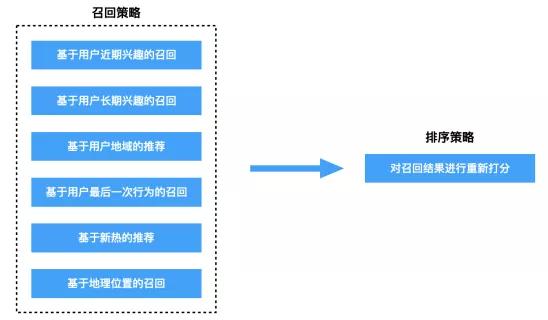
排序阶段只对少量的、召回阶段筛选出的物品进行打分,因而可以选择效果好的、复杂的算法模型(比如深度学习模型等)。在这一阶段我们可以将精力聚焦在模型的效果上。
如果用统计误差的思路来看召回、排序这个拆解过程,那么每个召回算法相当于一次随机变量的抽样(抽样的是用户的兴趣这个随机变量),由于自身方法的原因,每个召回算法是有一定误差的,不同的召回算法的误差方向是不一样的 。那么当我们在排序阶段将所有召回算法的结果汇聚起来时,各个召回算法的误差是可能相互抵消的,最终可以获得更精准的推荐结果。
推荐系统将算法流程分解为召回排序两个阶段,这个做法也可以用集成学习的思路解释:通过多个模型的集成,获得整体更优的效果。召回阶段就是利用了多个模型,可能每个模型刻画的是用户兴趣的某个方面,它不太准,但是没关系,只要找准了用户的某个兴趣点就够了。我们在排序阶段会将这些召回算法的结果整合起来,获得最终的最有利于描述用户兴趣的结果。
上面我们从4个角度来说明了为什么企业级推荐系统的推荐算法流程要拆解为召回、排序两个阶段。希望通过本文的学习,读者可以更好地理解这种设计的哲学,同时,也希望读者可以更加深入地理解推荐算法流程。














