经过训练以预测句子中下一个单词的基于机器学习的语言模型变得越来越强大、普遍和有用,从而导致问答、翻译等应用程序的突破性改进。但随着语言模型的不断发展,新的和意想不到的风险可能会暴露出来,这就要求研究界积极努力开发新的方法来缓解潜在的问题。
其中一种风险是模型可能会从训练数据中泄露细节。虽然这可能是所有大型语言模型都关心的问题,但如果要公开使用基于私有数据训练的模型,则可能会出现其他问题。由于这些数据集可能很大(数百 GB)并且来自各种来源,因此它们有时可能包含敏感数据,包括个人身份信息 (PII)——姓名、电话号码、地址等,即使是根据公共数据进行训练的. 这增加了使用此类数据训练的模型可以在其输出中反映其中一些私人细节的可能性。因此,重要的是要识别并最大限度地降低此类泄漏的风险,并制定策略以解决未来模型的问题。
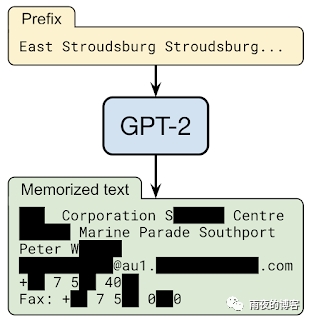
在与OpenAI、Apple、斯坦福大学、伯克利分校和东北大学合作的“从大型语言模型中提取训练数据”中,我们证明,只要能够查询预训练的语言模型,就可以提取特定的片段模型记忆的训练数据。因此,训练数据提取攻击是对最先进的大型语言模型的现实威胁。这项研究代表了早期的关键步骤,旨在让研究人员了解此类漏洞,以便他们可以采取措施减轻这些弱点。
语言模型攻击的伦理
训练数据提取攻击在应用于公众可用但训练中使用的数据集不可用的模型时最有可能造成伤害。然而,由于在这样的数据集上进行这项研究可能会产生有害的后果,我们改为对GPT-2进行概念验证训练数据提取攻击,GPT-2是一种由 OpenAI 开发的大型公开可用语言模型,仅使用公共数据进行训练。虽然这项工作特别关注 GPT-2,但结果适用于理解大型语言模型上可能存在的隐私威胁。
与其他与隐私和安全相关的研究一样,在实际执行此类攻击之前考虑此类攻击的道德规范很重要。为了最大限度地降低这项工作的潜在风险,这项工作中的训练数据提取攻击是使用公开可用的数据开发的。此外,GPT-2 模型本身在 2019 年由 OpenAI 公开,用于训练 GPT-2 的训练数据是从公共互联网收集的,任何遵循GPT中记录的数据收集过程的人都可以下载-2 纸。
此外,根据负责任的计算机安全披露规范,我们会跟踪提取了 PII 的个人,并在发布对这些数据的引用之前获得了他们的许可。此外,在这项工作的所有出版物中,我们已经编辑了任何可能识别个人身份的个人识别信息。我们还在 GPT-2 的分析中与 OpenAI 密切合作。
训练数据提取攻击
根据设计,语言模型使得生成大量输出数据变得非常容易。通过用随机短语为模型播种,该模型可以生成数百万个延续,即完成句子的可能短语。大多数情况下,这些延续将是合理文本的良性字符串。例如,当被要求预测字符串“ Mary had a little… ”的连续性时,语言模型将有很高的置信度认为下一个标记是“ lamb ”这个词。但是,如果某个特定的训练文档碰巧多次重复字符串“ Mary had a little wombat ”,模型可能会改为预测该短语。
训练数据提取攻击的目标是筛选来自语言模型的数百万个输出序列,并预测记住哪些文本。为了实现这一点,我们的方法利用了这样一个事实,即模型往往对直接从训练数据中捕获的结果更有信心。这些成员推理攻击使我们能够通过检查模型对特定序列的置信度来预测结果是否用于训练数据。
这项工作的主要技术贡献是开发了一种高精度推断成员资格的方法,以及以鼓励输出记忆内容的方式从模型中采样的技术。我们测试了许多不同的采样策略,其中最成功的一种生成以各种输入短语为条件的文本。然后我们比较两种不同语言模型的输出。当一个模型对序列有很高的置信度,而另一个(同样准确的)模型对序列的置信度较低时,很可能第一个模型已经记住了数据。
结果
在 GPT-2 语言模型的 1800 个候选序列中,我们从公共训练数据中提取了 600 多个记忆,总数受限于需要手动验证。记住的示例涵盖了广泛的内容,包括新闻标题、日志消息、JavaScript 代码、PII 等。尽管这些示例在训练数据集中很少出现,但它们中的许多示例都被记住了。例如,对于我们提取的许多 PII 样本,仅在数据集中的单个文档中找到。但是,在大多数情况下,原始文档包含 PII 的多个实例,因此模型仍将其作为高似然文本进行学习。
最后,我们还发现语言模型越大,它就越容易记住训练数据。例如,在一项实验中,我们发现 15 亿个参数的 GPT-2 XL 模型比 1.24 亿个参数的 GPT-2 Small 模型记忆的信息多 10 倍。鉴于研究界已经训练了 10 到 100 倍大的模型,这意味着随着时间的推移,需要做更多的工作来监控和缓解越来越大的语言模型中的这个问题。
经验教训
虽然我们专门演示了对 GPT-2 的这些攻击,但它们显示了所有大型生成语言模型中的潜在缺陷。这些攻击是可能的,这一事实对使用这些类型模型的机器学习研究的未来产生了重要影响。
幸运的是,有几种方法可以缓解这个问题。最直接的解决方案是确保模型不会在任何可能有问题的数据上进行训练。但这在实践中很难做到。
差分隐私 的使用允许对数据集进行训练,而无需透露单个训练示例的任何细节,是训练具有隐私的机器学习模型的最有原则的技术之一。在 TensorFlow 中,这可以通过使用tensorflow/privacy 模块(或类似的 PyTorch 或 JAX)来实现,该模块是现有优化器的直接替代品。即使这样也会有限制,并且不会阻止对重复次数足够多的内容的记忆。如果这是不可能的,我们建议至少测量发生了多少记忆,以便采取适当的行动。
语言模型继续展示出巨大的实用性和灵活性——然而,与所有创新一样,它们也可能带来风险。负责任地发展它们意味着主动识别这些风险并开发减轻它们的方法。我们希望这项突出大语言建模当前弱点的努力将提高更广泛的机器学习社区对这一挑战的认识,并激励研究人员继续开发有效的技术来训练模型,减少记忆。