今天,机器学习(ML)模型得到了大规模的使用,而且影响力也越来越大。然而,当它们被用于现实世界的领域时,往往表现出意想不到的行为。Google AI发文探讨不规范(Underspecification)是如何给机器学习带来挑战的。
如今,机器学习(ML)模型得到了比以往任何时候都更广泛的使用,并且它的影响力也变得越来越大。
然而,把它们放在现实领域中使用时,问题可不小,甚至经常会出现一些意想不到的行为。
例如,当分析一个计算机视觉(CV)模型的bad case的时候,研究人员有时会发现模型确实掌握了大部分对特征的理解能力,但对一些人类根本不会注意的、不相关的特征表现出惊人的敏感性。
再比如,一个自然语言处理(NLP)模型,让它学习文本吧,它也确实在学,只不过有时会依赖文本没有直接指示的人口统计相关性作为依据,更麻烦的是,这种错误还不太好预测。
其实,有些失败的原因,是众所周知的:例如,在不精确的数据上训练了ML模型,或者训练模型来解决结构上与应用领域不匹配的预测问题。
然而,即使处理了这些已知的问题,模型行为在部署中仍然是不一致的,甚至在训练运行之间也是不同的。
影响ML模型信度的罪魁:不规范
谷歌团队在「Journal of Machine Learning Research」上发表了一篇论文「不规范对现代机器学习的可信度提出了挑战」。

https://arxiv.org/pdf/2011.03395.pdf
文章中,研究人员表明:在现代机器学习系统中,一个特别容易造成故障的问题是不规范。
而且,在各种各样的实际机器学习(ML)系统中都经常会出现不规范,所以,谷歌对此提出了一些缓解策略。
什么是不规范?
不规范背后的意思是,虽然机器学习模型在保留的数据上进行过验证,但这种验证通常不足以保证模型在新环境中使用时,依然具有明确定义的行为。
ML系统之所以成功,很大程度上是因为它们在保留数据集上,对模型进行了验证,靠这样的方式来确保模型的高性能。
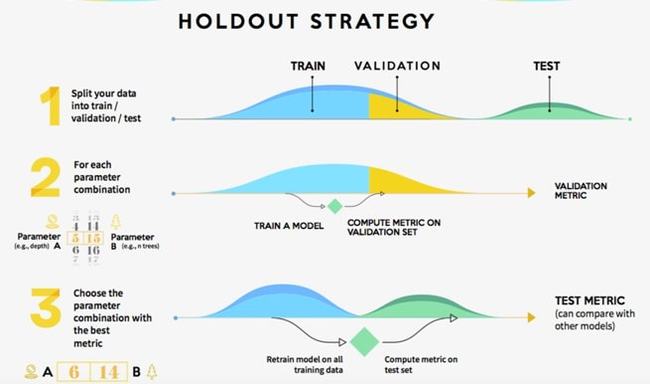
模型验证流程
然而,对于固定的数据集和模型架构,通常有许多不同的方法,可以使训练好的模型获得高验证性能。
但是在标准的预测任务中,编码不同解决方案的模型通常被视为等价的,因为它们的持续预测性能大致相等。
但是,如果以超出标准预测性能的标准来衡量这些模型时,它们之间的区别就会变得很明显,这就是要考验这些模型对不相关的输入扰动的公平性或鲁棒性。
举个例子,在标准验证中表现同样出色的模型中,一些模型可能在社会群体和人种之间表现出比其他模型更大的性能差异,或者更加依赖不相关的信息。

轻微扰动就可以让深度学习网络完全失灵
那么,当这些模型用于现实场景时,这些差异就会转化为预测行为上的真正差异。
不规范会导致研究人员在构建ML模型时想到的需求和ML管道(即模型的设计和实现)实际执行的需求之间的差距。
一个重要后果就是,ML管道原则上可以返回一个满足研究需求的模型,可是,这样一来,在实践中,这个模型也就只能满足对保留数据的准确预测,而对超出这些数据分布的数据,它却无能为力。
如何识别应用中的不规范?
这项工作研究了在现实应用中,使用机器学习模型时,不规范的具体含义。
谷歌给出的策略是使用几乎相同的机器学习(ML)管道来构建模型集,只对其施加对非常小的改变,这种改变之小,即使是对他们同时进行标准验证,性能也不会有实际影响。这种策略的重点是关注模型初始化训练和确定数据排序的随机种子。
ML Pipeline示意图
如果这些小变化会对模型的重要属性带来实质性影响,那么,就说明ML管道没有完全指出模型在真实世界会出现的行为。而研究人员在实验的每个领域中,都发现了这些微小的变化会导致模型的行为在现实世界的使用中出现实质性变化。
计算机视觉中的不规范
举一个例子,你可以想想计算机视觉中不规范与鲁棒性的关系。
计算机视觉中的一个主要挑战是,深度学习模型在人类认为没什么挑战性的分布变化下,经常会变得脆弱。
众所周知,在ImageNet基准测试中,表现良好的图像分类模型在ImageNet-C等基准测试中表现不佳,只不过是因为这些测试将常见的图像损坏(如像素化或运动模糊)应用于标准ImageNet测试集。所以,在实验中,标准管道没有规定出模型对这些破坏的敏感度。

ImageNet-C数据集样例
按照上面的策略,使用相同的管道和相同的数据生成50个ResNet-50图像分类模型。这些模型之间的唯一区别是训练中使用的随机种子。
当在标准的ImageNet验证集上进行评估时,这些模型实际上获得了相同的性能。然而,当模型在ImageNet-C(即在损坏的数据上)中的不同测试集上进行评估时,模型的测试性能变化比在标准的ImageNet上验证大几个数量级。
就算是在大得多的数据集上进行预训练的大规模模型,像在JFT-300M的3亿图像数据集上预先训练的BiT-L模型,这种不规范持续存在。对于这些模型,在训练的微调阶段改变随机种子会产生类似的变化。
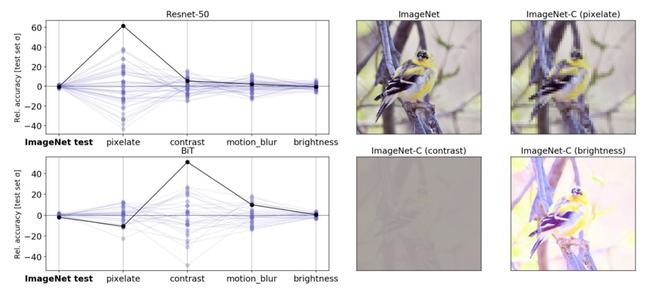
左图:在严重损坏的ImageNet-C数据上,相同的随机初始化的ResNet-50模型之间的精度变化。线条表示集合中每个模型在使用未损坏测试数据和损坏数据(像素化、对比度、运动模糊和亮度改变)的分类任务中的性能。给定值是相对于总体平均值的精度偏差,用在「干净的」ImageNet测试集上的精度标准偏差来衡量。黑色实线突出显示了任意选择的模型的性能,以显示一个测试的性能如何不能很好地指示其他测试的性能。
右图:标准ImageNet测试集中的示例图像,其中包含ImageNet-C基准测试的损坏版本。
另外,在专门为医学成像构建的专用计算机视觉模型中,这个问题也同样存在。其中深度学习模型显示出巨大的前景。
这里以两个应用方向为例,一个是眼科方向,用于从视网膜眼底图像检测糖尿病视网膜病变,另一个是皮肤病方向,从皮肤的照片判断患者的皮肤病情况。
研究人员对实际重要的维度上对这些pipeline生成的模型进行了压力测试。
对于眼科方向,研究人员测试了以不同随机种子训练的模型,在训练期间未遇见的新相机拍摄的图像时的执行结果。
对于皮肤科方向,测试思路大致相似,但针对的是皮肤类型不同的患者。
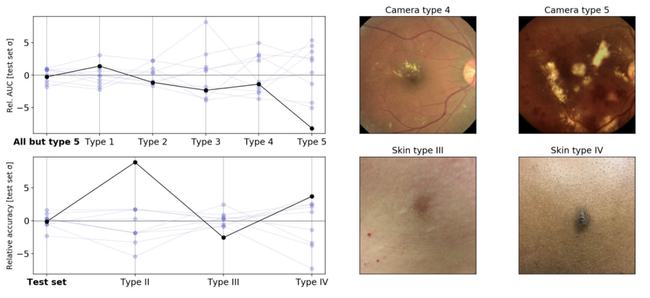
左上:在来自不同相机类型的图像上评估时,使用不同随机种子训练的糖尿病视网膜病变分类模型之间的AUC变化。左下:在不同的估计皮肤类型上评估时,使用不同随机种子训练的皮肤状况分类模型之间的准确性差异(由皮肤科医生训练的外行根据回顾性照片进行近似,可能会出现标记错误)。右图:来自原始测试集(左)和压力测试集(右)的示例图像。
结果显示,标准验证确实不足以完全体现训练模型在这些任务上的性能。比如在眼科方向的测试中,训练中使用的随机种子导致模型在面对新相机拍出的图片时,出现了比标准验证集更大的变量波动。
这些结果再次表明,单独的标准保持测试不足以确保医疗应用中模型的可靠性,需要对用于医疗领域模型的测试和验证协议进行扩展。在医学文献中,这些验证被称为「外部验证」。
除了医学领域外,分类不规范导致的问题在其他应用领域也同样存在。比如:
-
在NLP任务中,分类不规范会影响由BERT模型衍生出的句子。
-
在急性肾损伤预测任务重,分类不规范会导致对操作信号与生理信号的更多依赖。
-
在多基因风险评分 (PRS)任务中,分类不规范会影响 PRS 模型的性能。
结论
解决不规范问题是颇具挑战性的,它需要对超出标准预测性能的模型进行完整的规范和测试。要做到这一点,需要充分了解模型使用环境,了解如何收集训练数据,而且在可用数据不足时,需要结合领域内的专业知识。
而上述几点恰恰在当今的机器学习研究中经常被低估。长期以来,对于这些领域的投入是不足的。
要解决这个问题,首先需要为机器学习实用模型指定新的压力测试协议,对现有的测试方式进行扩展。在将新的测试标准编入可衡量的指标之后,通过数据增强、预训练和因果结构等算法策略,可能有助于改进这些模型的性能。
但同样应该注意的是,理想的压力测试和改进过程通常需要迭代,因为机器学习系统需求和使用它们的世界都在不断变化。