如今写代码已经成为各行各业的必备技能,学会写代码可以让计算机代替我们做一些重复的工作,极大提升工作效率。
但一个真正能帮你写代码的 AI 程序离我们还有多远?
5 月 5 日,IBM 向极少数媒体和学术界发布了 Project CodeNet,在当时并未引起过多关注。
CodeNet 完美继承了 ImageNet 的思想。ImageNet 是一个大规模的图像及其描述数据集,为 CV 的模型发展和标准化提供了巨大的帮助,也是深度学习计算机视觉进步的核心, 并且图像可免费用于非商业用途。
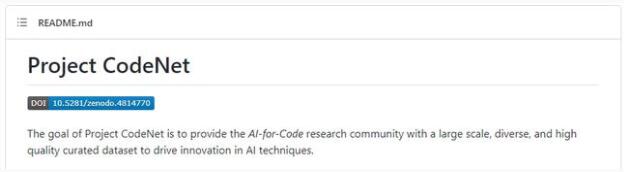
CodeNet 的目标是为人工智能写代码提供一个标准的数据库,它包含超过 1400 万个代码样本,涵盖 50 种编程语言,能够解决 4000 个编码问题。该数据集还包含许多附加数据,例如软件运行所需的内存量和运行代码的日志输出。
IBM 表示,Project CodeNet 是同类中最大、最具差异的数据集,它解决了当今编码中的三个主要用例:代码搜索(自动将一种代码翻译成另一种代码,包括像 COBOL 这样的遗留语言);代码相似性(识别不同代码之间的重叠和相似性);还有代码约束(根据开发人员的特定需求和参数定制约束)。
然而有安全研究人员认为 CodeNet 和类似项目最重要的影响不是优化代码,而是增加了自然语言编码(Natural Language Coding, NLC)的可能性。
近年来,OpenAI 和 Google 等公司一直在快速改进自然语言处理(NLP)技术。这些是机器学习驱动的程序,旨在更好地理解和模仿自然人类语言并在不同语言之间进行翻译。训练机器学习系统需要访问包含以所需人类语言编写的文本的大型数据集。
但写代码是一项很难学习的技能,更不用说掌握了,经验丰富的编码员应该精通多种编程语言。相比之下,NLC 利用 NLP 技术和诸如 CodeNet 之类的庞大数据库,能够利用英语来进行编程,最终使用任何其他自然语言都可以进行编码。
它可以使诸如设计网站之类的任务变得简单,只需输入一句话,然后就会出现一个符合要求的网站,这要求生成的代码都是可以运行的。
例如“制作带有飞机图像的红色背景,中间是公司的 logo,下方有一个与我联系的按钮。“
很明显,如此科幻的想法除了 IBM 以外还有很多人在做。
GPT-3 是 OpenAI 的一个 NLP 模型,在多项文本生成任务都遥遥领先,目前也已经被用于生成代码,输入就是预期的网站或者应用程序的自然语言描述,输出可运行的代码。
但是,在 IBM 的消息发布后不久,微软宣布已获得 GPT-3 的独家授权。
除了 GPT-3 外,微软还于 2018 年收购了互联网上最大的开源代码集合网站 GitHub。并且还开发了一个人工智能代码助手 GitHub Copilot,可以在 VS code 等 IDE 辅助开发,能够简化开发过程,但它是付费的。
虽然 Copilot 离 NLC 的目标还有很大距离,但它已经是向前迈了一大步了。
不过后续的测试来看,Copilot 除了抄袭开源代码和注释外,并不能创造代码,还会把其他用户的漏洞代码扩散开。

Copilot 是朝着 NLC 迈出的一大步,但它还远远没有实现 AI 写代码的功能。
虽然 NLC 还没有完全可行,但目前的研究方向正在迅速走向一个不需要长时间训练也能编程的未来,并且影响是巨大的。
首先,更多的研究和开发人员会产生更多的成果。有人认为潜在创新者的数量越多,创新率越高。
如果每个人都能写代码,那编程带来的创新潜力就会更大。
此外,计算物理学和统计社会学等学科越来越依赖于定制的计算机程序来处理数据,简化编写这类程序所需的技能要求,将提高计算机科学以外专业领域的研究人员部署新方法、做出新发现的能力。
然而,NLC 所需的人工智能的开发和部署资源相当昂贵,小公司根本无法支撑这种应用的开发和运行,所以最终很可能被微软、谷歌或 IBM 等主流巨头公司垄断。该服务可以收费提供,或者像大多数社交媒体服务一样免费提供。
并且我们有理由相信,由于机器学习需要大数据的支持,这些技术将由平台公司主导。从理论上讲,像 Copilot 这样的程序在引入新数据时会变得更好,也就是说使用的用户越多,效果越好,这种特性也使得新的竞争对手更难入场,即使他们有更强大或更良心的产品。
除非有强力的反垄断措施,否则大型资本主义企业集团似乎将成为下一次编码革命的把关人。