宋老师的SMT测试很有意思,但是编译内核涉及的因素太多了,包括访问文件系统等耗时受到存储器性能的影响,难以估算,因此很难评判SMT对性能的提升如何。
为了探究SMT对计算密集型workload的效果,我自己写了一个简单的测试程序。
使用pthread开多个线程,每个线程分别计算斐波那契数列第N号元素的值。每个线程计算斐波那契数列时除线程的元数据外只分配两个unsigned long变量,由此避免过高的内存开销。
workload的详细代码和测试脚本在[https://github.com/HongweiQin/smt_test]
毫无疑问,这是一个计算密集型负载,我在自己的笔记本上运行,配置如下(省略了一些不重要的项目):
- $ lscpu
- Architecture: x86_64
- CPU(s): 12
- On-line CPU(s) list: 0-11
- Thread(s) per core: 2
- Core(s) per socket: 6
- Socket(s): 1
- NUMA node(s): 1
- Vendor ID: GenuineIntel
- Model name: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
- L1d cache: 192 KiB
- L1i cache: 192 KiB
- L2 cache: 1.5 MiB
- L3 cache: 12 MiB
可以看到笔记本有一个Intel i7的处理器,6核12线程。经查,CPU0和CPU6共用一个Core,CPU1和CPU7共用一个Core,以此类推。
以下的测试(Test 1-5)中,每个线程分别计算斐波那契数列第40亿号元素的数值。
Test1:采用默认配置,开12线程进行测试。测试结果为总耗时45.003s。
- qhw@qhw-laptop:~/develop/smt_test$ time ./smt_test -f 4000000000
- threads_num=12, fibonacci_max=4000000000, should_set_affinity=0, should_inline=1, alloc_granularity=32
- real0m45.003s
- user7m12.953s
- sys0m0.485s
Test2:把smt关掉,同样的测试方法(12线程)。总耗时为25.733s。
- qhw@qhw-laptop:~/develop/smt_test$ cat turnoff_smt.sh
- #!/bin/bash
- echo "turn off smt"
- sudo sh -c 'echo off > /sys/devices/system/cpu/smt/control'
- qhw@qhw-laptop:~/develop/smt_test$ ./turnoff_smt.sh
- turn off smt
- qhw@qhw-laptop:~/develop/smt_test$ time ./smt_test -f 4000000000
- threads_num=12, fibonacci_max=4000000000, should_set_affinity=0, should_inline=1, alloc_granularity=32
- real0m25.733s
- user2m23.525s
- sys0m0.116s
对,你没看错。同样的workload,如果关掉smt,总耗时还变少了。Intel诚不欺我!
Test3:再次允许smt,但是将程序限制在三个物理Core上运行,则总耗时为34.896s。
- qhw@qhw-laptop:~/develop/smt_test$ ./turnon_smt.sh
- turn on smt
- qhw@qhw-laptop:~/develop/smt_test$ time taskset -c 0-2,6-8 ./smt_test -f 4000000000
- threads_num=12, fibonacci_max=4000000000, should_set_affinity=0, should_inline=1, alloc_granularity=32
- real0m34.896s
- user3m17.033s
- sys0m0.028s
Test3相比于Test1用了更少的Core,反而更快了。
为什么在Test2和3会出现这样违反直觉的结果?
猜想:Cache一致性在作怪!

图1
测试程序的main函数会分配一个含有T(T=nr_threads)个元素的`struct thread_info`类型的数组,并分别将每个元素作为参数传递给每个计算线程使用。`struct thread_info`定义如下:
- struct thread_info {
- pthread_t thread_id;
- int thread_num;
- unsigned long res[2];
- };
结构体中的res数组用于计算斐波那契数列,因此会被工作线程频繁地写。
注意到,sizeof(struct thread_info)为32,而我的CPU的cacheline大小为64B!这意味着什么?
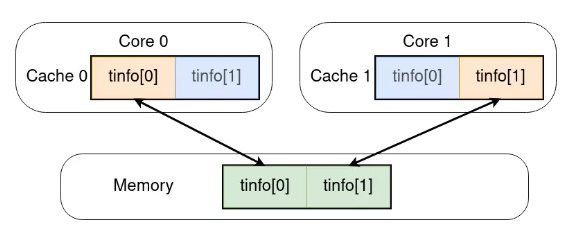
图2
如图所示,如果Thread 0在Core 0上运行,则它会频繁写tinfo[0],Thread 1在Core 1上运行,则它会频繁写tinfo[1]。
这意味着,当Thread 0写tinfo[0]时,它其实是写入了Core 0上L1 Cache的Cacheline。同样的,当Thread 1写tinfo[1]时,它其实是写入了Core 1上L1 Cache的Cacheline。此时,由于Core 1上的Cacheline并非最新,因此CPU需要首先将Core 0中的Cacheline写入多核共享的L3 Cache甚至是内存中,然后再将其读入Core 1的L1 Cache中,最后再将Thread 1的数据写入。此时,由于Cache 0中的数据并非最新,Cacheline会被无效化。由此可见,如果程序一直这样运行下去,这一组数据需要在Cache 0和1之间反复跳跃,占用较多时间。
这个猜想同样可以解释为什么使用较少的CPU可以加速程序运行。原因是当使用较少的CPU时,多线程不得不分时共用CPU,如果Thread 0和Thread 1分时共用了同一个CPU,则不需要频繁将Cache无效化,程序运行时间也就缩短了。
验证猜想:增加内存分配粒度!
对程序进行修改后,可以使用`-g alloc_granularity`参数设定tinfo结构体的分配粒度。使用4KB为粒度进行分配,再次进行测试:
Test4:12线程,开启SMT,分配粒度为4096。总耗时为13.193s,性能相比于Test1的45.003s有了质的提升!
- qhw@qhw-laptop:~/develop/smt_test$ time ./smt_test -f 4000000000 -g 4096
- threads_num=12, fibonacci_max=4000000000, should_set_affinity=0, should_inline=1, alloc_granularity=4096
- real0m13.193s
- user2m31.091s
- sys0m0.217s
Test5:在Test4的基础上限制只能使用3个物理Core。总耗时为24.841s,基本上是Test4的两倍。这说明在这个测试下,多核性能还是线性可扩展的。
- qhw@qhw-laptop:~/develop/smt_test$ time taskset -c 0-2,6-8 ./smt_test -f 4000000000 -g 4096
- threads_num=12, fibonacci_max=4000000000, should_set_affinity=0, should_inline=1, alloc_granularity=4096
- real0m24.841s
- user2m26.253s
- sys0m0.032s
超线程SMT究竟可以快多少?
表格和结论:
| 测试名 | 硬件配置 | 运行时间(s) |
| Test6 | “真”6核 | 38.562 |
| Test7 | “假”6核 | 58.843 |
| Test8 | “真”3核 | 73.175 |
测试使用的是6个工作线程。为了减少误差,增加一点运行时间,每个线程计算斐波那契数列第200亿项的值。
对比Test6和7,可以看到SMT的提升大概在52.6%左右。
测试记录:
Test6:别名“真”6核,使用6个关闭了SMT的物理核进行计算。总耗时为38.562s。
Test7:别名“假”6核,使用3个开启了SMT的物理核进行计算。总耗时为58.843s。
Test8:别名“真”3核,使用3个关闭了SMT的物理核进行计算。总耗时为1m13.175s。
- qhw@qhw-laptop:~/develop/smt_test$ cat test.sh
- #!/bin/bash
- fibonacci=20000000000
- sudo printf ""
- ./turnoff_smt.sh
- time ./smt_test -f $fibonacci -g 4096 -t 6
- ./turnon_smt.sh
- time taskset -c 0-2,6-8 ./smt_test -f $fibonacci -g 4096 -t 6
- ./turnoff_smt.sh
- time taskset -c 0-2,6-8 ./smt_test -f $fibonacci -g 4096 -t 6
- ./turnon_smt.sh
- qhw@qhw-laptop:~/develop/smt_test$ ./test.sh
- turn off smt
- threads_num=6, fibonacci_max=20000000000, should_set_affinity=0, should_inline=1, alloc_granularity=4096
- real0m38.562s
- user3m50.786s
- sys0m0.000s
- turn on smt
- threads_num=6, fibonacci_max=20000000000, should_set_affinity=0, should_inline=1, alloc_granularity=4096
- real0m58.843s
- user5m53.018s
- sys0m0.005s
- turn off smt
- threads_num=6, fibonacci_max=20000000000, should_set_affinity=0, should_inline=1, alloc_granularity=4096
- real1m13.175s
- user3m39.486s
- sys0m0.008s
- turn on smt