













【51CTO.com快译】引言
如今,机器学习(ML)正在广泛地影响着商业、工程、以及研究等领域。通常,机器学习水平的进步,与软件和自动化的深入迭代有着密切的关系。只要人类的某项活动,需要依赖计算机去进行重复性和判断性的处理,我们就可以通过机器学习来执行与实现。当然,面对各种不确切的待解决问题,我们需要通过定义搜索空间、以及具体的学习算法,来训练计算机去自行判定与解决。
目前,机器学习已经凭借着有效的深度学习,进入了2.0的时代。它们不但可以更好地预测蛋白模型的数据拟合,而且能够在围棋、Dota II、星际争霸II等方面击败专业的人类玩家,以及创建各种十分连贯的文本和语音交互式响应。您可以通过链接,进一步了解机器学习对于不同行业的影响。当然,这些也都离不开各种被称为AutoML的开源工具、以及将ML进行实际应用的优秀实践。
什么是AutoML?
作为一大类技术和工具,AutoML可以被用于各种自动化的搜索与学习场景中。例如,我们将贝叶斯优化应用于统计学习算法的超参数(hyperparameter),或是将深度学习模型运用于神经架构的搜索。这些多样化的生态系统,目前已被编录到了AutoML.ai中。其中,最著名的AutoML软件包之一便是:Auto-SciKit-Learn(或称Auto-Sklearn)。它荣获了2014年至2016年的ChaLearn AutoML挑战赛的获胜者。
Auto-Sklearn是由德国的自动化机器学习研究小组所开发。作为一个Python包,Auto-Sklearn的构建密切遵循了SciKit-Learn的使用模式,这也是它得名为“Auto-SciKit-Learn”的原因。
除了Auto-Sklearn,Freiburg-Hannover的AutoML小组还开发了Auto-PyTorch库。在下面的简单示例中,我们将使用这两个代码库,作为进入AutoML的切入点。
AutoML的演示
首先,我们来设置所需要的软件包和依赖项。在此,我们使用Python 3的virtualenv,来管理演示项目的虚拟环境。当然,您也可以使用Anaconda(译者注:一种开源的Python发行版本)和pip,它们的工作方式都是类似的。
下面是在Ubuntu等基于Unix的系统上,设置运行环境的各种命令。如果您使用的是Windows,则可以从Anaconda提示符中通过输入命令,来设置环境。虽然Auto-Sklearn的文档建议用户,从它们的requirements.txt依赖文件处开始安装,但是就本例中的代码而言,并不需要如此。
- # create and activate a new virtual environment virtualenv automl --python=python3 source automl/bin/activate
- # install auto-sklearn pip install auto-sklearn
值得注意的是,如果您对两个AutoML库使用相同的环境,那么可能会发生冲突。因此我们需要为Auto-PyTorch创建第二个环境。而且该环境中的Python应不低于3.7版本。
- deactivate virtualenv autopt –-python=python3.7 source autopt/bin/activate # install auto-pytorch from the github repo git clone https://github.com/automl/Auto-PyTorch.git cd Auto-PyTorch pip install -e . pip install numpy==1.20.0 pip install ipython
我们在运行上述pip install -e,及其后面的两个install语句时,可能会碰到如下奇怪错误。经研究,我们可以通过将NumPy版本升级到1.20.0,予以修复。
- ValueError: numpy.ndarray size changed, may indicate binary incompatibility. Expected 88 from C header, got 80 from PyObject
如果您想为该项目做出贡献,或想查看最新的运行代码,请查阅如下开发分支。
- # (optional) git checkout development # make sure to switch back to the primary branch for the tutorial git checkout master
由于本示例的其余代码均使用Python来编写,因此请您启用Python提示符、Jupyter笔记本或文本编辑器。
本示例将包含使用标准的SciKit-Learn、Auto-Sklearn和Auto-PyTorch分类器(classifier)的基本分类演示。我们将针对每个场景,使用SciKit-Learn中的单一内置数据集。而每个演示都会通过共享代码的方式,来导入通用的依赖项,并加载和拆分对应的数据集。
- import time import sklearn import sklearn.datasets
- #** load and split data ** data, target = sklearn.datasets.load_iris(return_X_y=True)
- # split n = int(data.shape[0] * 0.8)
- train_x = data[:n] train_y = target[:n] test_x = data[n:] test_y = target[n:]
上面有关设置数据集的代码,将被用于本示例中的每个演示模块上。
为了节省时间,我们使用了小型的“iris”数据集(其中包括:150个样本、4个特征和3个标签类别)。您完全可以在阅读完本示例后,去试用更为复杂的数据集。
sklearn.datasets的其他分类数据集,则包括:糖尿病(load_diabetes)数据集和数字数据集(load_digits)。其中,糖尿病数据集带有569个样本,每个样本具有30个特征和2个标签类别;而数字数据集则带有1797个样本,每个样本具有64个特征(对应着8x8的图像),以及10个标签类别。
在开始使用sklearn的AutoML分类器之前,让我们通过默认的设置,从vanilla sklearn中训练各种标准化的分类器。虽然我们有许多可供选择的方式,但是我们在此会沿用k最近邻(k-nearest neighbors)分类器、支持向量机(support vector machine)分类器、以及多层感知器(multilayer perceptron)。
- # import classifiers from sklearn.svm import SVC from sklearn.neural_network import MLPClassifier from sklearn.neighbors import KNeighborsClassifier
- # instantiate with default parameters knn = KNeighborsClassifier() mlp = MLPClassifier() svm = SVC()
SciKit-Learn通过使用友好的拟合/预测(fit/predict)API,使得训练模型的过程变得轻而易举。同时,Auto-Sklearn和Auto-PyTorch两个软件包也保留了相同的API,这使得三者中的任一训练模型,不但相似,而且易用。
- t0 = time.time() knn.fit(train_x, train_y) mlp.fit(train_x, train_y) svm.fit(train_x, train_y) t1 = time.time()
同样,各种模型的评估也比较简单。SciKit-Learn分类模型提供一种预测方法,可被用于接收输入数据,预测标签,进而通过将其传递给sklearn.metrics.accuracy_score,来计算准确度。
下面的代码可使用k最近邻、支持向量机,以及在最后一个代码段中训练的多层感知器分类器,来计算保留测试集的各种预测和预测精度。
- knn_predict = knn.predict(test_x) train_knn_predict = knn.predict(train_x)
- svm_predict = svm.predict(test_x) train_svm_predict = svm.predict(train_x)
- mlp_predict = mlp.predict(test_x) train_mlp_predict = mlp.predict(train_x)
- knn_accuracy = sklearn.metrics.accuracy_score(test_y, knn_predict) train_knn_accuracy = sklearn.metrics.accuracy_score(train_y,train_knn_predict)
- svm_accuracy = sklearn.metrics.accuracy_score(test_y, svm_predict) train_svm_accuracy = sklearn.metrics.accuracy_score(train_y,train_svm_predict)
- mlp_accuracy = sklearn.metrics.accuracy_score(test_y, mlp_predict) train_mlp_accuracy = sklearn.metrics.accuracy_score(train_y,train_mlp_predict)
- print(f"svm, knn, mlp test accuracy: {svm_accuracy:.4f}," \ f"{knn_accuracy:.4}, {mlp_accuracy:.4}") print(f"svm, knn, mlp train accuracy: {train_svm_accuracy:.4f}," \ f"{train_knn_accuracy:.4}, {train_mlp_accuracy:.4}") print(f"time to fit: {t1-t0}")

iris数据集上的Sklearn分类器
这些模型对于iris训练数据集虽然十分有效,但是它们在训练集和测试集之间仍存在这显著的差距。
下面,让我们使用来自autosklearn.classification的AutoSKlearnClassifier类,对多种类型的机器学习模型,执行超参数的搜索,并保留其中最适合的集合。如下代码段所示,在引入通用import,并设置训练和测试数据集的拆分之后,我们需要导入并实例化AutoML分类器。
- import autosklearn from autosklearn.classification import AutoSklearnClassifier as ASC
- classifier = ASC() classifier.time_left_for_this_task = 300
- t0 = time.time() classifier.fit(train_x, train_y) t1 = time.time()
- autosk_predict = classifier.predict(test_x) train_autosk_predict = classifier.predict(train_x)
- autosk_accuracy = sklearn.metrics.accuracy_score( \ test_y, autosk_predict \ ) train_autosk_accuracy = sklearn.metrics.accuracy_score( \ Train_y,train_autosk_predict \ )
- print(f"test accuracy {autosk_2_accuracy:.4f}") print(f"train accuracy {train_autosk_2_accuracy:.4f}") print(f"time to fit: {t1-t0}")
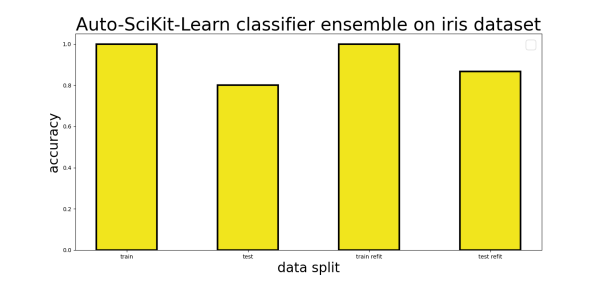
iris数据集上的Auto-Sklearn分类器集成
如果您不去设置time_left_for_this_task的默认值(3600秒,即一小时),那么带有AutoSklearnClassifier的fit方法,运行起来非常耗时。显然,这对于简单的iris数据集来说,是不可接受的。为此,该软件包的配套文档有提到,在初始化分类器对象时,时间限制应当被设置为输入参数。
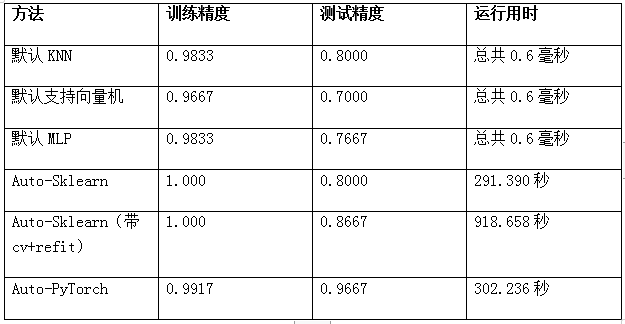
当然,您也可以在启用了交叉验证的情况下,去运行fit方法。为此,您需要使用refit方法、最佳模型、以及超参数,在整个训练数据集上进行再次训练。而在具体实践中,我们发现,与默认设置相比,在使用交叉验证和refit时,测试集的准确率会从80%略升至86.67%(请参见下表)。
值得注意的是,在使用了predict方法去拟合AutoSklearnClassifier对象之后,我们的推理过程,会使用在AutoML超参数搜索期间,找到的最佳模型集合。
最后,让我们来讨论另一个适合深度学习的AutoML包:Auto-PyTorch。与Auto-Sklearn类似,Auto-PyTorch非常容易上手。在运行如下代码段之前,请切换到Auto-PyTorch环境,以确保有合适的依赖项可用。
- import autoPyTorch from autoPyTorch import AutoNetClassification as ANC
- model = ANC(max_runtime=300, min_budget=30, max_budget=90, cuda=False)
- t0 = time.time() model.fit(train_x, train_y, validation_split=0.1) t1 = time.time()
- auto_predict = model.predict(test_x) train_auto_predict = model.predict(train_x)
- auto_accuracy = sklearn.metrics.accuracy_score(test_y, auto_predict) train_auto_accuracy = sklearn.metrics.accuracy_score(train_y, train_auto_predict)
- print(f"auto-pytorch test accuracy {auto_accuracy:.4}") print(f"auto-pytorch train accuracy {train_auto_accuracy:.4}")
在导入常用的imports,并拆分了数据之后,您可以看到:
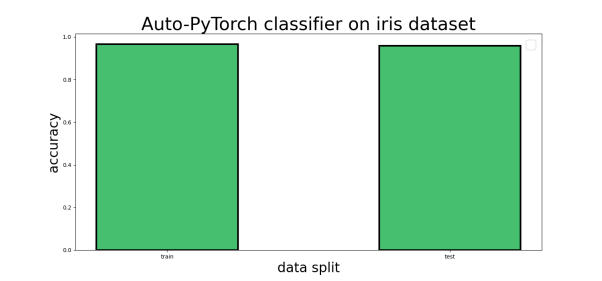
iris数据集上的Auto-PyTorch分类器
由上述结果可知,Auto-PyTorch在拟合iris数据集方面十分高效,产生训练和测试的准确度可达90秒。这比我们之前训练的自动化SciKit-Learn分类器,以及具有默认参数的标准化sklearn分类器,都要好许多。
小结
总的说来,AutoML的价值主要源于超参数搜索的自动化方面。AutoML额外的抽象层和自动化超参数搜索,会提高经典的数据科学、以及机器学习工作流的实用性、性能和效率。只要使用得当,AutoML工具不仅能够提高应用项目的性能,而且可以降低超参数的冗长,让架构搜索更具成本效益。
目前,诸如Auto-Sklearn、Auto-PyTorch、Auto-WEKA等AutoML软件包,可以成为任何机器学习或数据科学工具的有力补充。其中,Auto-PyTorch已经获得了Apache 2.0的许可证,而Auto-Sklearn也可以使用BSD 3-Clause的许可证。当然,为了让这两个软件包能够正常工作,我们需要将NumPy升级到1.20.0,以及其他各种小修小补。
原文标题:AutoML: Using Auto-Sklearn and Auto-PyTorch,作者:Kevin Vu
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】


















