在本年初的TiDB Hackathon上,我和一众队友尝试使用Flink为TiDB添加物化视图功能,并摘得了“最佳人气奖”。可以说,物化视图在这届比赛中可谓是一个热点。单单是结合Flink实现相关功能的队伍就有三四个。必须承认的是,在比赛结束时我们项目的完成度很低,虽然基本思路已经定型,最终呈现的结果却远没达到预期。经过半年多断断续续的修补,在今天终于可以发布一个 预览版本 给大家试用。这篇文章就是对我们思路和成果的一个介绍。
相比其他队伍,我们的主要目标是实现强一致的物化视图构建。也就是保证查询时的物化视图可以达到接近快照隔离(Snapshot Isolation)的隔离级别,而不是一般流处理系统的最终一致性(Eventual Consistency)。关于实现一致性的讨论在下文有详细介绍。
使用简介
尽管是一个实验性的项目,我们仍然探索了一些方便实用的特性,包括:
- TiFlinkApp
关于TiFlink实用的详细信息,请参考 README 。下面是快速启动一个任务的代码片段:
- TiFlinkApp.newBuilder()
- .setJdbcUrl("jdbc:mysql://root@localhost:4000/test") // Please make sure the user has correct permission
- .setQuery(
- "select id, "
- + "first_name, "
- + "last_name, "
- + "email, "
- + "(select count(*) from posts where author_id = authors.id) as posts "
- + "from authors")
- // .setColumnNames("a", "b", "c", "d") // Override column names inferred from the query
- // .setPrimaryKeys("a") // Specify the primary key columns, defaults to the first column
- // .setDefaultDatabase("test") // Default TiDB database to use, defaults to that specified by JDBC URL
- .setTargetTable("author_posts") // TiFlink will automatically create the table if not exist
- // .setTargetTable("test", "author_posts") // It is possible to sepecify the full table path
- .setParallelism(3) // Parallelism of the Flink Job
- .setCheckpointInterval(1000) // Checkpoint interval in milliseconds. This interval determines data refresh rate
- .setDropOldTable(true) // If TiFlink should drop old target table on start
- .setForceNewTable(true) // If to throw an error if the target table already exists
- .build()
- .start(); // Start the app
物化视图(流处理系统)的一致性
目前主流的物化视图(流处理)系统主要使用最终一致性。也就是说尽管最终结果会收敛到一致的状态,但在处理期间终端用户仍可能查询到一些不一致的结果。最终一致性在很多应用中被证明是足够的,那么更强的一致性是否真的需要呢?这里的一致性和Flink的Exact Once语义又有什么关系呢?有必要进行一些介绍。
ACID
ACID是数据库的一个基本的概念。一般来说,作为CDC日志来源的数据库已经保证了这四条要求。但是在使用CDC数据进行流式处理的时候,其中的某些约束却有可能被破坏。
最典型的情况是失去Atomic特性。这是因为在CDC 日志中,一个事务的修改可能覆盖多条记录,流处理系统如果以行为单位进行处理,就有可能破坏原子性。也就是说,在结果集上进行查询的用户看到的事务是不完整的。
一个典型的案例如下:
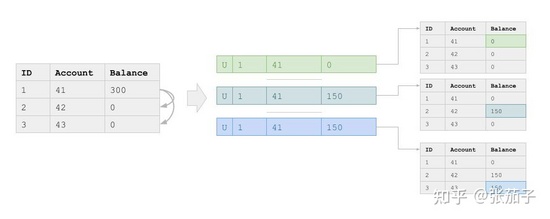
在上述案例中,我们有一个账户表,账户表之间会有转账操作,由于转账操作涉及多行修改,因此往往会产生多条记录。假设我们有如下一条SQL定义的物化视图,计算所有账户余额的总和:
- SELECT SUM(balance) FROM ACCOUNTS;
显然,如果我们只存在表内账户之间的转账,这个查询返回的结果应该恒为某一常数。但是由于目前一般的流处理系统不能处理事务的原子性,这条查询产生的结果却可能是不断波动的。实际上,在一个不断并发修改的源表上,其波动甚至可能是无界的。
尽管在最终一致的模型下,上述查询的结果在经过一段时间之后将会收敛到正确值,但没有原子性保证的物化视图仍然限制的应用场景:假设我想实现一个当上述查询结果偏差过大时进行报警的工具,我就有可能会接收到很多虚假报警。也就是说此时在数据库端并没有任何异常,数值的偏差只是来源于流处理系统内部。
在分布式系统中,还有另一种破坏原子性的情况,就是当一个事务修改产生的副作用分布在多个不同的节点处。如果在这时不使用2PC等方法进行分布式提交,则也会破坏原子性:部分节点(分区)上的修改先于其他节点生效,从而出现不一致。
线性一致性
不同于由单机数据库产生的CDC日志(如MySQL的Binlog),TiDB这类分布式数据库产生的日志会有线性一致性的问题。在我们的场景下,线性一致性的问题可以描述为:从用户的角度先后执行的一些操作,其产生的副作用(日志)由于消息系统传递的延迟,以不同的先后顺序被流处理系统处理。
假设我们有订单表(ORDERS)和付款信息表(PAYMENTS)两个表,用户必须先创建订单才能进行支付,因此下列查询的结果必然是正数:
- WITH order_amount AS (SELECT SUM(amount) AS total FROM ORDERS),
- WITH payment_amount AS (SELECT SUM(amount) AS total FROM PAYMENTS)
- SELECT order_amount.total - payment_amount.total
- FROM order_amount, payment_amount;
但是由于ORDERS表和PAYMENTS表在分别存储在不同的节点上,因此流处理系统消费他们的速度可能是不一致的。也就是说,流处理系统可能已经看到了支付信息的记录,但是其对应的订单信息还没到达。因此就可能观察到上述查询出现负数的结果。
在流处理系统中,有一个Watermark的概念可以用来同步不同表的数据的处理进度,但是它并不能避免上述线性一致性问题。这是因为Watermark只要求时间戳小于其的所有记录都已经到达,不要求时间戳大于其的记录都没有到达。也就是说,尽管ORDERS表和PAYMENTS表现在拥有相同的Watermark,后者仍然可能会有一些先到的记录已经生效。
由此可见,单纯依靠Watermark本身是无法处理线性一致性问题的,必须和源数据库的时间产生系统和消息系统配合。
更强一致性的需求
尽管最终一致性在很多场景下是够用的,但其依然存在很多问题:
- 误导用户:由于很多用户并不了解一致性相关的知识,或者对其存在一定的误解,导致其根据尚未收敛的查询结果做出了决策。这种情况在大部分关系型数据库都默认较强一致性的情况下是应该避免的
- 可观测性差:由于最终一致性并没有收敛时间的保证,再考虑到线性一致性问题的存在,很难对流处理系统的延迟、数据新鲜度、吞吐量等指标进行定义。比如说用户看到的JOIN的结果可能是表A当前的快照和表B十分钟前的快照联接的结果,此时应如何定义查询结果的延迟度呢?
- 限制了部分需求的实现:正如上文所提到的,由于不一致的内部状态,导致某些告警需求要么无法实现,要么需要延迟等待一段时间。否则用户就不得不接受较高的误报率
实际上,更强一致性的缺乏还导致了一些运维操作,特别是DDL类的操作难以利用之前计算好的结果。参考关系型数据库和NoSQL数据库的发展历史,我们相信目前主流的最终一致性只是受限于技术发展的权宜之计,随着相关理论和技术研究的进步,更强的一致性将会慢慢成为流处理系统的主流。
技术方案简介
这里详细介绍一下TiFlink在技术方案上的考虑,以及如何实现了强一致的物化视图(StreamSQL)维护。
TiKV和Flink
尽管这是一个TiDB Hackthon项目,因此必然会选择TiDB/TiKV相关的组件,但是在我看来TiKV作为物化视图系统的中间存储方案具备很多突出的优势:
- TiKV是一个比较成熟分布式KV存储,而分布式环境是下一代物化视图系统必须要支持的场景。利用TiKV配套的Java Client,我们可以方便的对其进行操作。同时TiDB本身作为一个HTAP系统,正好为物化视图这个需求提供了一个Playground
- TiKV提供了基于Percolator模型的事务支持和MVCC,这是TiFlink实现强一致流处理的基础。在下文中可以看到,TiFlink对TiKV的写入主要是以接连不断的事务的形式进行的
- TiKV原生提供了对CDC日志输出的支持。实际上TiCDC组件正是利用这一特性实现的CDC日志导出功能。在TiFlink中,为了实现批流一体并简化系统流程,我们选择直接调用TiKV的CDC GRPC接口,因此也放弃了TiCDC提供的一些特性
我们最初的想法本来是直接将计算功能集成进TiKV,选择Flink则是在比赛过程中进一步思考后得到的结论。选择Flink的主要优势有:
- Flink是目前市面上最成熟的Stateful流处理系统,其对处理任务的表达能力强,支持的语义丰富,特别是支持批流一体的StreamSQL实现,是我们可以专心于探索我们比较关注的功能,如强一致性等
- Flink比较完整地Watermark,而我们发现其基于Checkpoint实现的Exactly Once Delivery语义可以很方便地和TiKV结合来实现事务处理。实际上,Flink自己提供的一些支持Two Phase Commit的Sink就是结合Checkpoint来进行提交的
- Flink的流处理(特别是StreamSQL)本身就基于物化视图的理论,在比较新的版本开始提供的DynamicTable接口,就是为了方便将外部的Change Log引入系统。它已经提供了对INSERT、DELETE、UPDATE等多种CDC操作的支持
当然,选择TiKV+Flink这样的异构架构也会引入一些问题,比如SQL语法的不匹配,UDF无法共享等问题。在TiFlink中,我们以Flink的SQL系统和UDF为准,将其作为TiKV的一个外挂系统使用,但同时提供了方便的建表功能。
强一致的物化视图的实现思路
这一部分将介绍TiFlink如何在TiDB/TiKV的基础上实现一个比较强的一致性级别:延迟快照隔离(Stale Snapshot Isolation)。在这种隔离级别下,查询者总是查询到历史上一个一致的快照状态。在传统的快照隔离中,要求查询者在$T$时间能且只能观察到Commit时间小于$T$的所有事务。而延迟快照隔离只能保证观察到$T-\Delta t$之前所有已提交的事务。
在TiDB这样支持事务的分布式数据库上实现强一致的物化视图,最简单的思路就是使用一个接一个的事务来更新视图。事务在开始时读取到的是一个一致的快照,而使用分布式事务对物化视图进行更新,本身也是一个强一致的操作,且具有ACID的特性,因此得以保证一致性。
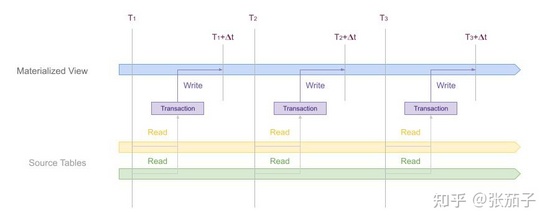
为了将Flink和这样的机制结合起来且实现增量维护,我们利用了TiKV本身已经提供的一些特性:
- TiKV使用Time Oracle为所有的操作分配时间戳,因此虽然是一个分布式系统,其产生的CDC日志中的事务的时间戳实际上是有序的
- TiKV的节点(Region)可以产生连续不断的增量日志(Change Log),这些日志包含了事务的各种原始信息并包含时间戳信息
- TiKV的增量日志会定期产生Resolved Timestamp,声明当前Region不再会产生时间戳更老的消息。因此很适合用来做Watermark
- TiKV提供了分布式事务,允许我们控制一批修改的可见性
因此TiFlink的基本实现思路就是:
- 利用流批一体的特性,以某全局时间戳对源表进行快照读取,此时可以获得所有源表的一个一致性视图
- 切换到增量日志消费,利用Flink的DynamicTable相关接口,实现物化视图的增量维护和输出
- 以一定的节奏Commit修改,使得所有的修改以原子的事务方式写入目标表,从而为物化视图提供一个又一个更新视图
以上几点的关键在于协调各个节点一起完成分布式事务,因此有必要介绍一下TiKV的分布式事务执行原理。
TiKV的分布式事务
TiKV的分布式事务基于著名的Percolator模型。Percolator模型本身要求存储层的KV Store有MVCC的支持和单行读写的原子性和乐观锁(OCC)。在此基础上它采用以下步骤完成一次事务:
- 指定一个事务主键(Primary Key)和一个开始时间戳并写入主键
- 其他行在Prewrite时以副键(Secondary Key)的形式写入,副键会指向主键并具有上述开始时间戳
- 在所有节点Prewrite完成后,可以提交事务,此时应先Commit主键,并给定一个Commit时间戳
- 主键Commit成功后事务实际上已经提交成功,但此时为了方便读取,可以多节点并发地对副键进行Commit并执行清理工作,之后写入的行都将变为可见
上述分布式事务之所以可行,是因为对主键的Commit是原子的,分布在不同节点的副键是否提交成功完全依赖于主键,因此其他的读取者在读到Prewrite后但还没Commit的行时,会去检查主键是否已Commit。读取者也会根据Commit时间戳判断某一行数据是否可见。Cleanup操作如果中途故障,在之后的读取者也可以代行。
为了实现快照隔离,Percolator要求写入者在写入时检查并发的Prewrite记录,保证他们的时间戳符合一定的要求才能提交事务。本质上是要求写入集重叠的事务不能同时提交。在我们的场景中假设物化视图只有一个写入者且事务是连续的,因此无需担心这点。
在了解了TiKV的分布式事务原理之后,要考虑的就是如何将其与Flink结合起来。在TiFlink里,我们利用Checkpoint的机制来实现全局一致的事务提交。
使用Flink进行分布式事务提交
从上面的介绍可以看出,TiKV的分布式事务提交可以抽象为一次2PC。Flink本身有提供实现2PC的Sink,然而并不能直接用在我们的场景下。原因是Percolator模型在提交时需要有全局一致的事务开始时间戳和提交时间戳。而且仅仅是在Sink端实现2PC是不足以实现强一致隔离级别的:我们还需要在Source端配合,使得每个事务恰好读入所需的增量日志。
幸运的是,Flink的2PC提交机制实际上是由Checkpoint驱动的:当Sink接收到Checkpoint请求时,会完成必要的任务以进行提交。受此启发,我们可以实现一对Source和Sink,让他们使用Checkpoint的ID共享Transaction的信息,并配合Checkpoint的过程完成2PC。而为了使不同节点可以对事务的信息(时间戳,主键)等达成一致,需要引入一个全局协调器。事务和全局协调器的接口定义如下:
- public interface Transaction {
- public enum Status {
- NEW,
- PREWRITE,
- COMMITTED,
- ABORTED;
- };
- long getCheckpointId();
- long getStartTs();
- default long getCommitTs();
- default byte[] getPrimaryKey();
- default Status getStatus();
- }
- public interface Coordinator extends AutoCloseable, Serializable {
- Transaction openTransaction(long checkpointId);
- Transaction prewriteTransaction(long checkpointId, long tableId);
- Transaction commitTransaction(long checkpointId);
- Transaction abortTransaction(long checkpointId);
- }
使用上述接口,各个Source和Sink节点可以使用CheckpointID开启事务或获得事务ID,协调器会负责分配主键并维护事务的状态。为了方便起见,事务Commit时对主键的提交操作也放在协调器中执行。协调器的实现有很多方法,目前TiFlink使用最简单的实现:在JobManager所在进程中启动一个GRPC服务。基于TiKV的PD(ETCD)或TiKV本身实现分布式的协调器也是可能的。
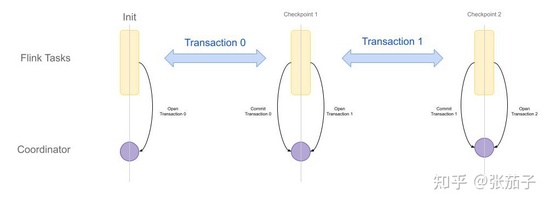
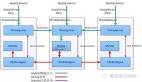
上图展示了在Flink中执行分布式事务和Checkpoint之间的协调关系。一次事务的具体过程如下:
- Source先从TiKV接收到增量日志,将他们按照时间戳Cache起来,等待事务的开始
- 当Checkpoint进程开始时,Source会先接收到信号。在Source端的Checkpoint与日志接收服务运行在不同的线程中
- Checkpoint线程先通过全局协调器获得当前事务的信息(或开启一个新事务),分布式情况下一个CheckpointID对应的事务只会开启一次
- 得到事务的开始时间戳后,Source节点开始将Cache中小于此时间戳的已提交修改Emit到下游计算节点进行消费。此时Source节点也会Emit一些Watermark
- 当所有Source节点完成上述操作后,Checkpoint在Source节点成功完成,此后会向后继续传播,根据Flink的机制,Checkpoint在每个节点都会保证其到达之前的所有Event都已被消费
- 当Checkpoint到达Sink时,之前传播到Sink的Event都已经被Prewrite过了,此时可以开始事务的提交过程。Sink在内部状态中持久化事务的信息,以便于错误时恢复,在所有Sink节点完成此操作后,会在回调中调用协调器的Commit方法从而提交事务
- 提交事务后,Sink会启动线程进行Secondary Key的清理工作,同时开启一个新的事务
注意到,在第一个Checkpoint开始前,Sink可能已经开始接收到写入的数据了,而此时它还没有事务的信息。为了解决这一问题,TiFlink在任务开始时会直接启动一个初始事务,其对应的CheckpointID是0,用于提交最初的一些写入。这样的话,在 CheckpointID=1 的Checkpoint完成时,实际上提交的是这个0事务。事务和Checkpoint以这样的一种错位的方式协调执行。
下图展示了包含协调器在内的整个TiFlink任务的架构:
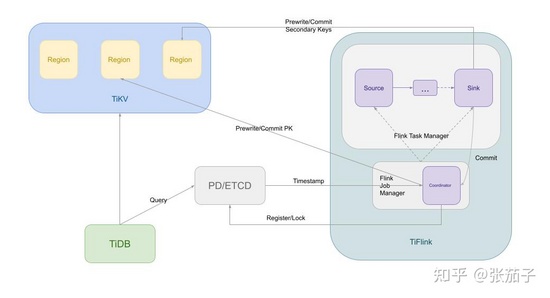
基于以上的系统设计,我们就得到了一个在TiKV上实现延迟快照隔离的物化视图。
其他设计考虑
众所周知,KSQL是Flink之外另一个流行的流处理系统,它直接与Kafka消息队列系统结合,用户无需部署两套处理系统,因此受到一些用户的青睐。很多用户也使用KSQL实现类似物化视图这样的需求。然而在我看来,这种强耦合于消息队列的流处理系统并不适合物化视图的使用场景。
KSQL可以说是Log Oriented数据处理系统的的代表,在这种系统中,数据的本源在于日志信息,所有的表都是为了方便查询而消费日志信息从而构建出来的视图。这种系统具有模型简单、容易实现、可以长时间保存日志记录等优点。
与之相对是Table Oriented数据处理系统,MySQL、TiDB/TiKV都属于这一类系统。这一类系统的所有修改操作都作用于表数据结构,虽然期间也会有日志生成,但往往对表数据结构和日志的修改是一起协调进行的。这里日志的主要是为持久化和事务服务,往往不会留存太长时间。相比于Log Oriented数据处理系统,这类系统对写入和事务的处理都更为复杂一点,然而却拥有更强可扩展性的要求。
归根结底,这是因为Log Oriented系统中的数据是以日志的形式存储,因此在扩展时往往需要进行成本较高的Rehash,也更难实现再平衡。而Table Oriented的系统,数据主要以表的形式存储,因此可以以某些列进行有序排列,从而方便在一致性Hash的支持下实现Range的切分、合并和再平衡。
个人认为,在批流一体的物化视图场景下,长时间保存日志并无太大的意义(因为总是可以从源表的快照恢复数据)。相反,随着业务的发展不断扩展数据处理任务和视图是一件比较重要的事。从这个角度来看Table Oriented系统似乎更适合作为物化视图需求的存储承载介质。
当然,在实时消费增量Log时发生的分区合并或分裂是一个比较难处理的问题。TiKV在这种情况下会抛出一个GRPC错误。TiFlink目前使用的是比较简单的静态映射方法处理任务和分区之间的关系,在未来可以考虑更为合理的解决方案。
总结
本文介绍了使用Flink在TiKV上实现强一致的物化视图的基本原理。以上原理已经基本上在TiFlink系统中实现,欢迎各位读者试用。以上所有的讨论都基于Flink的最终一致模型的保证,即:流计算的结果只与消费的Event和他们在自己流中的顺序有关,与他们到达系统的顺序以及不同流之间的相对顺序无关。
目前的TiFlink系统还有很多值得提高的点,如:
- 支持非Integer型主键和联合主键
- 更好的TiKV Region到Flink任务的映射
- 更好的Fault Tolerance和任务中断时TiKV事务的清理工作
- 完善的单元测试
如果各位读者对TiFlink感兴趣的话,欢迎试用并提出反馈意见,如果能够贡献代码帮助完善这个系统那就再好不过了。
关于物化视图系统一致性的思考是我今年最主要的收获之一。实际上,最初我们并没有重视这一方面,而是在不断地交流当中才认识到这是一个有价值且很有挑战性的问题。通过TiFlink的实现,可以说是基本上验证了上述方法实现延迟快照一致性的可行性。当然,由于个人的能力水平有限,如果存在什么纰漏,也欢迎各位提出讨论。
最后,如果我们假设上述延迟快照一致性的论述是正确的,那么实现真正的快照隔离的方法也就呼之欲出。不知道各位读者能否想到呢?