1. INTRODUCTION
在信息安全领域中,机器学习方法在流量分析中得到了广泛的应用。在应用机器学习方法时,许多方面决定着模型的表现,如特征提取,模型选择以及超参数调整。在本文中,作者提出了一种自动化应用机器学习机器实现流量分析目标的通用方法。这种方法依赖于对网络流量的统一表示,通过将不同流量分析任务中的特征表示为统一的形式,结合自动机器学习方法,可以实现对网络流量的自动化分析,而不依赖于大量的背景知识和人力成本。
本文的主要贡献在于:
-
为自动化机器学习提供了一种新的方向。提出一种统一的网络数据包表示方法nPrint。
-
将nPrint与自动机器学习工具相结合,提出nPrintML,实现了自动化流量分析。
-
使用nPrintML对8个不同的流量分析任务进行案例分析,实验的结果表明nPrintML可以更好地获取网络流量的特征信息,nPrintML获取的机器学习模型在性能上比传统特征工程得到的机器学习模型更加优越。
2. DATA REPRESENTATION
在应用机器学习方法时,对数据进行编码是非常重要的一环。为了实现上述提出的目标,数据编码需要满足以下要求:
-
Complete:由于nPrint实现的是一种统一数据编码,而不依赖于专家知识,所以需要提取数据包包头的所有信息。
-
Constant size per problem:对于机器学习模型,数据的输入需要保持一致。
-
Inherently normalized:机器学习模型在归一化后的数据上表现较好。
-
Aligned:不同数据包头的同一部分在编码后应该位于同样的位置。
Building a Standard Data Representation
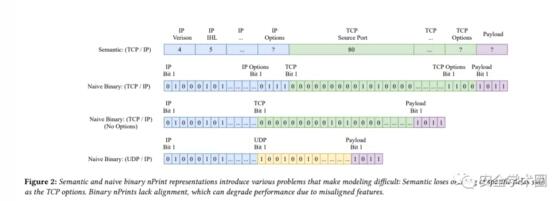
在通用的网络流量表示方法中,主要有语义表示法和非齐二进制表示法,如图:
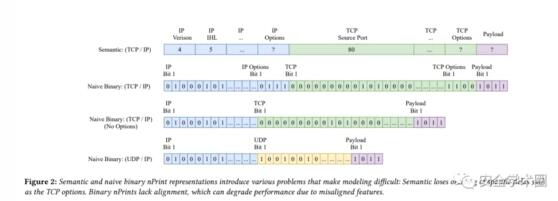
这些方法都无法很好地满足上述需求。为了解决这一问题,作者基于两种方法的思想,将两种方法进行混合,提出nPrint:
3. NPRINTML
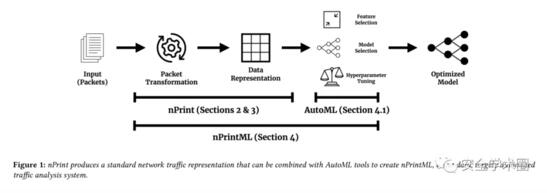
作者将nPrint与自动机器学习方法相结合,提出nPrintML,实现了机器学习自动化的流程,nPrintML的全部流程如下:
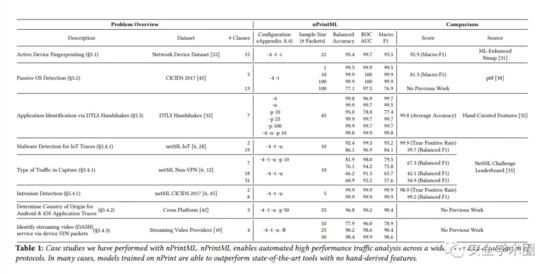
4. CASE STUDIES
使用nPrintML,作者对8个流量分析场景进行实例分析,实验结果表明:nPrintML可以应用于不同场景,获得的模型较传统方法得到的模型性能更好:完整的实验结果如下: