













干我们这行免不了要阅读大量资料,但这个行业又存在大量细分的领域,我们的时间是有限的,现代人能投入读书的时间更是少之又少,一个问题是我们到底应该深入阅读还是广泛阅读?
最近读到 Shopify 某个开发团队前负责人 Simon Eskildsen 的采访[1]。Simon Eskildsen 只是一个高中生,却在 gap year 加入创业期的 Shopify 并跟随公司一同成长为技术管理者。没有任何学位的他表示,自己是靠着大量阅读来学习计算机和管理的知识。Simon Eskildsen 在采访中提到自己努力成为T 型人才:在一个领域深入,但在多个领域有广博的知识面。
之前的文章中,我们聊过分布式计算、存储、协调等主题,唯独网络方面没有谈过。在《SRE:Google运维解密》中有一句令我影响深刻的话:“UNIX 系统内部细节和1~3层网络知识是Google最看重的两类额外的技术能力。”
本身我的网络知识也比较薄弱,恰好最近工作设计一些网络架构相关的知识,于是从10月开始我停了下来,开始阅读一些现代数据中心网络架构的知识。读者可以和我一起思考,如果新的数据中心网络架构让你来设计,你会怎么做?
这在 O'REILLY 的新书《Cloud Native Data Center Networking》(中文《云原生数据中心网络》)中有解答。我本来读的原版,可是没法理解书中一些英文网络词汇。最近中文版出版,正好找来对照着读一下,并记此笔记。
为什么需要一个新的网络架构
如果应用一层不变,那我们就没有必要进行讨论了。我们谈云原生数据中心网络,那这个架构就是要为现代云原生应用而设计的。所以,现代云原生应用有什么特点?
书中提到,“应用-网络”架构的演进经历了如下图的四个阶段。
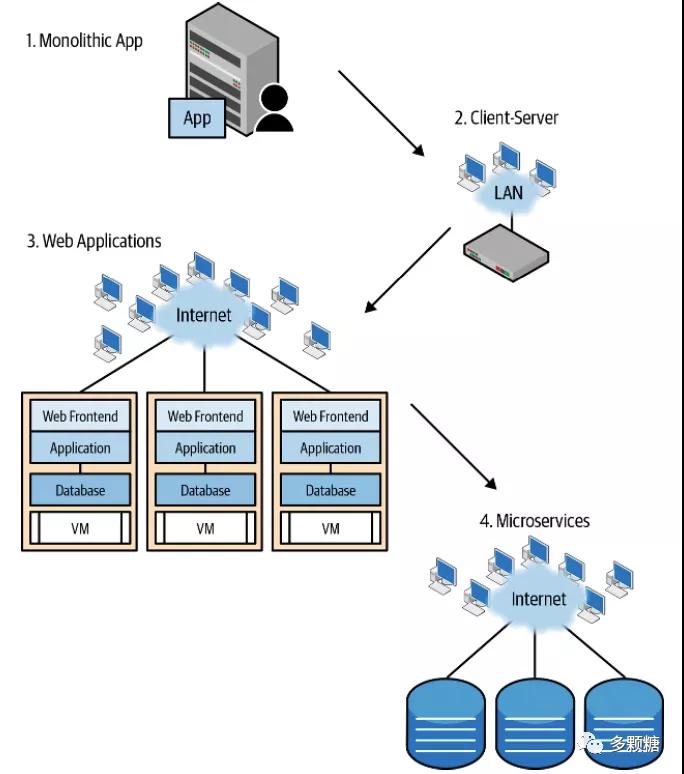
1.单体应用
- 运行在大型机上
- 网络流量小,协议是私有的
2.客户端-服务器(C/S)架构
- 工作站和 PC 兴起
- LAN 开始崛起,网络流量增加,以太网、Token Ring 和 FDDI 是最流行的连接,速度最高为 100Mbps。最后,以太网和 TCP/IP 赢了
3.Web 应用
- 随着计算能力不断提高,CPU 性能过剩,应用开始运行在虚拟机中,Windows 成为主流,Linux还不够成熟
- 千兆以太网成为企业网络互联标准
4.微服务
- Google 分布式系统带来历史性转变,南北向(客户端和服务器之间)流量主导转变成东西向(服务器之间)流量主导。Linux 成熟,云的兴起,进入微服务和容器时代
- 万兆网成为主流,网络速度不断提高
可见,分布式应用发生巨变,网络被打了个措手不及。传统网络为什么“跟不上节奏”?
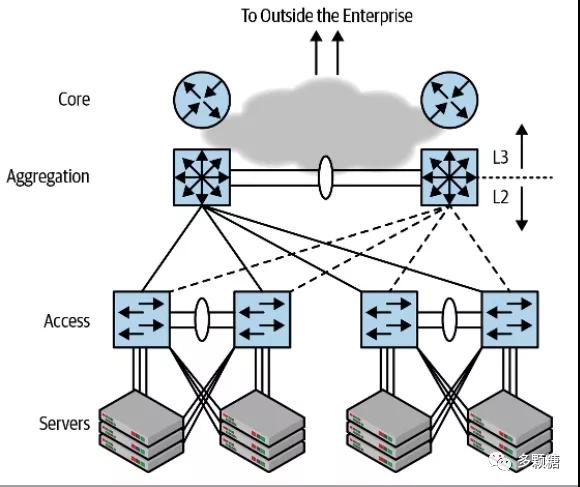
上图是传统网络,这种网络设计被称为“接入-汇聚-核心(access-aggregation-core)”架构。计算机连接到接入交换机,之上是一对分布式的汇聚交换机,汇聚交换机连接到核心网络,从而使接入层连接到外网。
“接入-汇聚-核心”网络严重依赖于桥接(Bridging)技术,原因有三:
- 数据转发芯片的出现,这种硬件技术最初仅支持桥接
- 企业专有的网络软件栈,除 IP 协议外还有别的协议
- 交换网络零配置的承诺,路由网络相对桥接网络来说很难配置,而人为配置错误不是导致网络故障的第一大原因,就是第二大原因
路由和桥接的区别:桥接工作在 OSI 网络模型第二层即链路层,交换机或网桥根据 MAC 地址来交换数据,链路层交换的是数据帧(frame)。路由工作在 OSI 第三层即网络层,路由器根据 IP 地址来找到目标地址,网络层交换的是数据包。
尽管传统网络取得很大成功,但桥接网络依然有以下限制:
- 广播风暴和生成树协议(STP)的影响
- 泛洪带来负担
- IP 层的冗余设计,为了使汇聚交换机高可用,需要支持两台交换机使用同一个IP地址,但同一时间只有一台路由器支持,为此又发明了 FHRP 协议来支持。
在转发网络中,每个数据包都携带两个 MAC 地址:源地址和目标地址。网桥会在自身的 MAC 地址表中查找目标 MAC 地址。如果不知道,它将数据包发送到除接收数据包的接口以外的所有其他接口。当网桥在自身的 MAC 地址表中找不到待转发数据包的目的 MAC 地址,而向所有端口发送该数据包的行为称为泛洪(flooding)。
“接入-汇聚-核心”很适合客户端-服务器应用架构这种南北向流量为主的模式,如今服务器-服务器架构越来越多,应用规模显著变大,“接入-汇聚-核心”存在以下问题:
1.不可扩展性
- 泛洪(Flooding)不可避免
- VLAN 最多为 4096 个的限制
- ARP 的负担,汇聚交换机需要应答大量ARP,导致CPU过高
- 交换机和STP的局限。理论上增加汇聚交换机能够提升东西向带宽,但是STP不支持两个以上的汇聚交换机
2.复杂性。桥接网络需要很多协议支持:STP、FHRP、链路失效侦测、供应商私有协议(如 VTP)
3.失效域(Failure Domain)。容易发生粗粒度的失效,比如:单个链路的失效造成带宽减半
4.不可预测性。许多组件会导致网络变得不可预测,增加故障定位难度
缺乏敏捷。云计算领域,不停地有租户使用资源或销毁资源,而 VLAN 需要网络中每个节点都正确配置了 VLAN 信息才能正常工作,添加或移除 VLAN 是一个费时费力的过程。
桥接技术的支持者没有放弃,针对这些问题提出了许多解决方案,但在当代企业数据中心少有使用。
云原生数据中心基础设施想建立一个可大规模扩展的网络架构,Clos 就是这个架构。
Clos 拓扑
Clos 拓扑结构以其发明者 Charles Clos 命名,如下图所示,该拓扑也称为 leaf-spine 拓扑(或 spine-leaf 架构)。
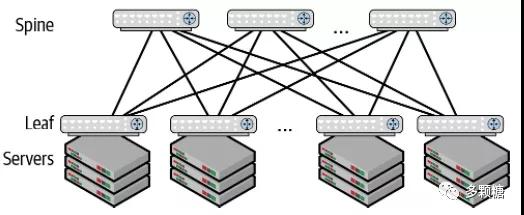
上图中:
- spine 交换机。目的只有一个:连接不同的 leaf 交换机,计算节点永远不会连接到 spine 交换机
- leaf 交换机。服务器通过 leaf 交换机连接到网络,leaf 之间不直连,而是通过 spine 交换机互相连接
Clos 拓扑在任何两台服务器之间都有两条以上的路径,产生了一个高容量网络支持东西向流量。对比传统网络,Clos 架构还有着很好的水平扩展性:
- 增加 leaf 交换机和服务器来扩展系统容量
- 增加 spine 交换机扩展带宽
而“接入-汇聚-核心”只能换成性能更强的汇聚交换机来进行垂直扩展。
深入探讨 Clos 架构
1.Clos 架构还有以下特性:
2.leaf、spine 可以使用同类、较小的交换机来构建网络
路由作为基本的互连模式
Clos 不使用STP,只在单个机架内直接支持桥接,跨机架桥接使用更现代的网络虚拟化解决方案(例如VXLAN)
3.Clos 收敛比
1:1 收敛比的网络也称为非阻塞网络,即上行链路带宽等于下行链路带宽。如果 spine 和 leaf 都是 n 口交换机,1:1 收敛比的 Clos 拓扑可连接的最大服务器数量为 n^2/2
4.链路速率
如果交换机链路使用比服务器链路更高的速率,则可以用更少的 spine 交换机来支持相同的收敛比
5.一些现实的限制
受到制冷、机柜、散热、服务器摆放等限制,以上理论并不能原封不动落实到数据中心,单个机柜一般是20或40台服务器。导致spine端口数量较多而leaf端口数量较少,设备厂商一般会提供不同的spine和leaf交换机
6.细粒度失效域
- 如果有两个以上的 spine 交换机,单个链路故障不会带来灾难
- leaf 到 spine 的一条链路故障,其余部分仍可以继续使用全部带宽,故障影响范围尽可能小
- 系统性的控制平面故障可能会影响整个网络,但不会出现”接入-汇聚-核心“网络中系统性故障(如广播风暴)
扩展 Clos 架构
如果你想要构建一个支持数万或数十万台服务器的超大数据中心,还要拓展出三层 Clos 拓扑,如下图所示,有两种扩展方法:
- 虚拟机箱模型(Facebook),对应上图(b)
- pod 模型(Microsoft、Amazon),对应上图(c)
拓展后的三层 Clos 拓扑最上层交换机称为“超级 spine 交换机”。
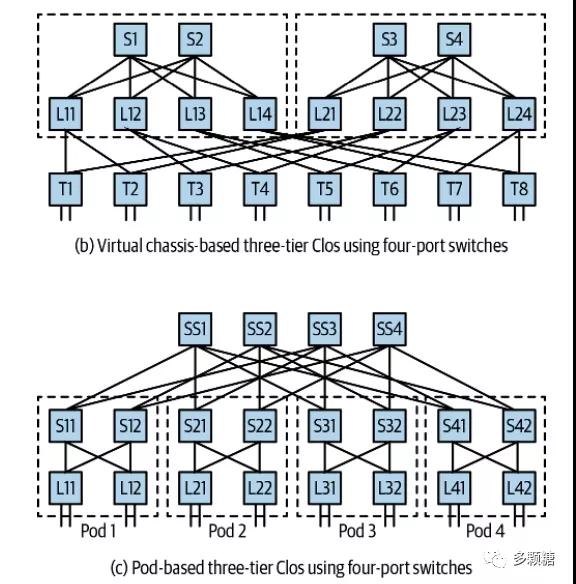
两种模型的优缺点对比:
- 考虑应用与网络模型匹配:
- 虚拟机箱模型均为5跳,适合运行单个应用,故 Facebook 采用此模型;
- pod模型同一pod平均3跳,而到其他pod为5跳,适合提供云服务,故Microsoft 和 Amazon 采用模型;
- 考虑数据中心扩建,对于给定的容量两种模型所需交换机数量相同,但:
- 虚拟机箱模型上两层交换机数量必须满足收敛比,还要提供足够的 leaf 交换机
- pod 模型如果开始流量都在 pod 内部,可以先只部署较少的超级 spine 交换机
Clos 拓扑的影响和优秀实践
Clos 拓扑结构带来如下影响:
- 重新思考故障和排错。交换机固定且单一,故障类型简单,可以直接替换故障交换机
- 布线。Clos 拓扑需要管理大量线缆,可以使用线缆验证技术:PTM 或 Ansible 来验证线缆
- 固定样式的交换机可以简化库存管理
- 由于存在大量交换机,不再可能手动配置网络,网络自动化必不可少
Clos 拓扑的一些优秀实践:
- 保持 spine-leaf 单链路,不要使用多个链路增加带宽,而是添加更多 spine 或 leaf 来增加带宽(例如:多个链路可能会导致 BGP 出错)

- spine 交换机只用于连接 leaf 节点,额外的工作会使spine交换机收到超过预定流量份额的流量(保持简单是优势而不是劣势)
- spine 和 leaf 使用同样的盒式交换机,不要使用端口更多的框式交换机作为spine节点,原因:1、不好扩展成3层Clos;2、资产管理变得复杂;3、故障原因更复杂。
书中提到,LinkedIn 和 Dropbox 就后悔使用不一致的交换机。
本文转载自微信公众号「多颗糖」,可以通过以下二维码关注。转载本文请联系多颗糖公众号。














