本文转载自微信公众号「运维开发故事」,作者Double_冬&华子。转载本文请联系运维开发故事公众号。
1.背景
边缘计算平台,旨在将边缘端靠近数据源的计算单元纳入到中心云,实现集中管理,将云服务部署其上,及时响应终端请求。然而,成千上万的边缘节点散布于各地,例如银行网点、车载节点、加油站等基于一些边缘设备管理场景,服务器分散在不同城市,无法统一管理,为了优化集群部署以及统一管理,特探索边缘计算场景方案。
2.边缘计算挑战
边缘计算框架在 Kubernetes 系统里,需要解决下面的问题:
- 网络断连时,节点异常或重启时,内存数据丢失,业务容器无法恢复;
- 网络长时间断连,云端控制器对业务容器进行驱逐;
- 长时间断连后网络恢复时,边缘和云端数据的一致性保障。
- 网络不稳定下,K8S client ListWatch机制下为保证数据一致性,在每次重连时都需要同步ReList一次,较大规模的边缘节点数量加以较不稳定的网络,将造成巨大的网络开销和API Server的cpu负担,特别是不可靠的远距离跨公网场景。
3.方案选型
- KubeEdge
- Superedge
- Openyurt
- k3s
3.1. KubeEdge
3.1.1 架构简介
KubeEdge是首个基于Kubernetes扩展的,提供云边协同能力的开放式智能边缘平台,也是CNCF在智能边缘领域的首个正式项目。KubeEdge重点要解决的问题是:
- 云边协同
- 资源异构
- 大规模
- 轻量化
- 一致的设备管理和接入体验
KubeEdge的架构如下所示:
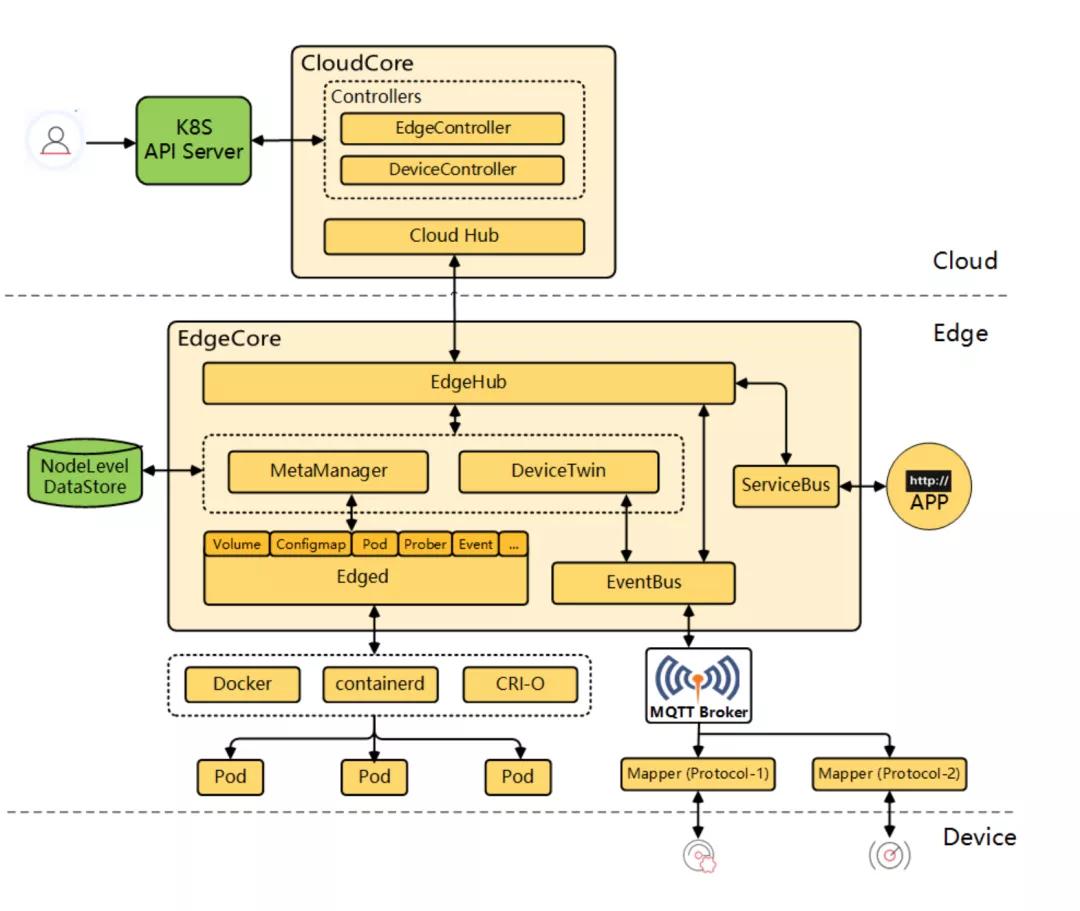
KubeEdge架构上清晰地分为三层,分别是:云端、边缘和设备层。
云端
KubeEdge的云端进程包含以下2个组件:
- cloudhub部署在云端,接收edgehub同步到云端的信息;
- edgecontroller部署在云端,用于控制Kubernetes API Server与边缘的节点、应用和配置的状态同步。
Kubernetes maser运行在云端,用户可以直接通过kubectl命令行在云端管理边缘节点、设备和应用,使用习惯与Kubernetes原生的完全一致,无需重新适应。
边缘
KubeEdge的边缘进程包含以下5个组件:
- edged是个重新开发的轻量化Kubelet,实现Pod,Volume,Node等Kubernetes资源对象的生命周期管理;
- metamanager负责本地元数据的持久化,是边缘节点自治能力的关键;
- edgehub是多路复用的消息通道,提供可靠和高效的云边信息同步;
- devicetwin用于抽象物理设备并在云端生成一个设备状态的映射;
- eventbus订阅来自于MQTT Broker的设备数据。
网络
KubeEdge 边云网络访问依赖EdgeMesh:
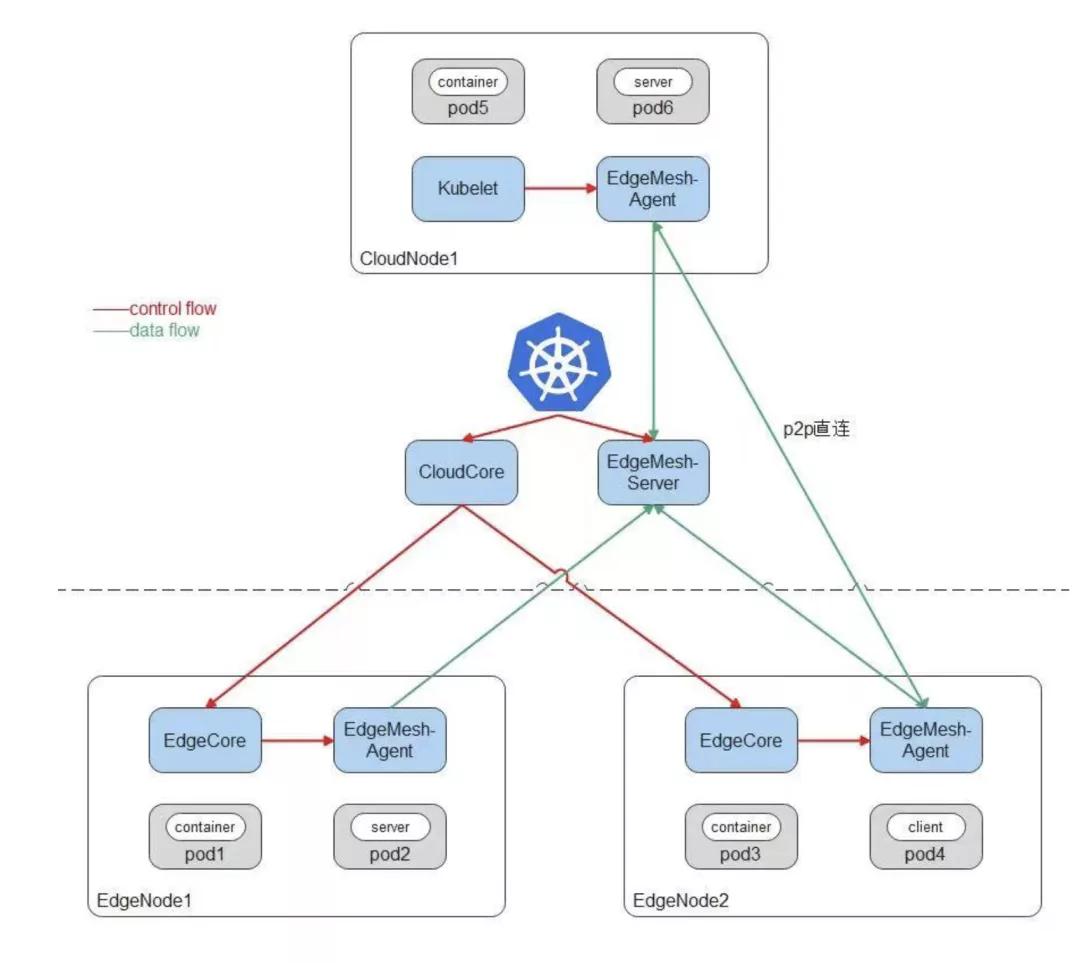
云端是标准的Kubernetes集群,可以使用任意CNI网络插件,比如Flannel、Calico;可以部署任意Kubernetes原生组件,比如Kubelet、KubeProxy;同时云端部署KubeEdge云上组件CloudCore,边缘节点上运行KubeEdge边缘组件EdgeCore,完成边缘节点向云上集群的注册。
EdgeMesh包含两个组件:EdgeMesh-Server和每个节点上的EdgeMesh-Agent。
EdgeMesh-Server工作原理:
- EdgeMesh-Server运行在云上节点,具有一个公网IP,监听来自EdgeMesh-Agent的连接请求,并协助EdgeMesh-Agent之间完成UDP打洞,建立P2P连接;
- 在EdgeMesh-Agent之间打洞失败的情况下,负责中继EdgeMesh-Agent之间的流量,保证100%的流量中转成功率。
EdgeMesh-Agent工作原理:
- EdgeMesh-Agent的DNS模块,是内置的轻量级DNS Server,完成Service域名到ClusterIP的转换。
- EdgeMesh-Agent的Proxy模块,负责集群的Service服务发现与ClusterIP的流量劫持。
- EdgeMesh-Agent的Tunnel模块,在启动时,会建立与EdgeMesh-Server的长连接,在两个边缘节点上的应用需要通信时,会通过EdgeMesh-Server进行UDP打洞,尝试建立P2P连接,一旦连接建立成功,后续两个边缘节点上的流量不需要经过EdgeMesh-Server的中转,进而降低网络时延。
3.1.2 实践
根据官方文档《Deploying using Keadm | KubeEdge》进行部署测试
| 类型 | ip | 系统版本 | 架构 | 集群版本 | 端口开放 |
|---|---|---|---|---|---|
| 云端 | 47.108.201.47 | Ubuntu 18.04.5 LTS | amd64 | k8s-v1.19.8 + kubeedge-v1.8.1 | 开放端口 10000-10005 |
| 边缘 | 172.31.0.153 | Ubuntu 18.04.5 LTS | arm64 | kubeedge-v1.8.1 |
实践结论:
根据官方文档部署,边缘节点可以正常加入集群,可以正常部署服务至边缘节点,部署edgemesh测试服务访问,边缘可以通过svc访问云端服务,但是云端无法通过svc访问边缘,边缘节点服务之间无法通过svc进行访问。
3.2. Superedge
3.2.1 架构简介
SuperEdge是腾讯推出的Kubernetes-native边缘计算管理框架。相比openyurt以及kubeedge,SuperEdge除了具备Kubernetes零侵入以及边缘自治特性,还支持独有的分布式健康检查以及边缘服务访问控制等高级特性,极大地消减了云边网络不稳定对服务的影响。
整体架构:
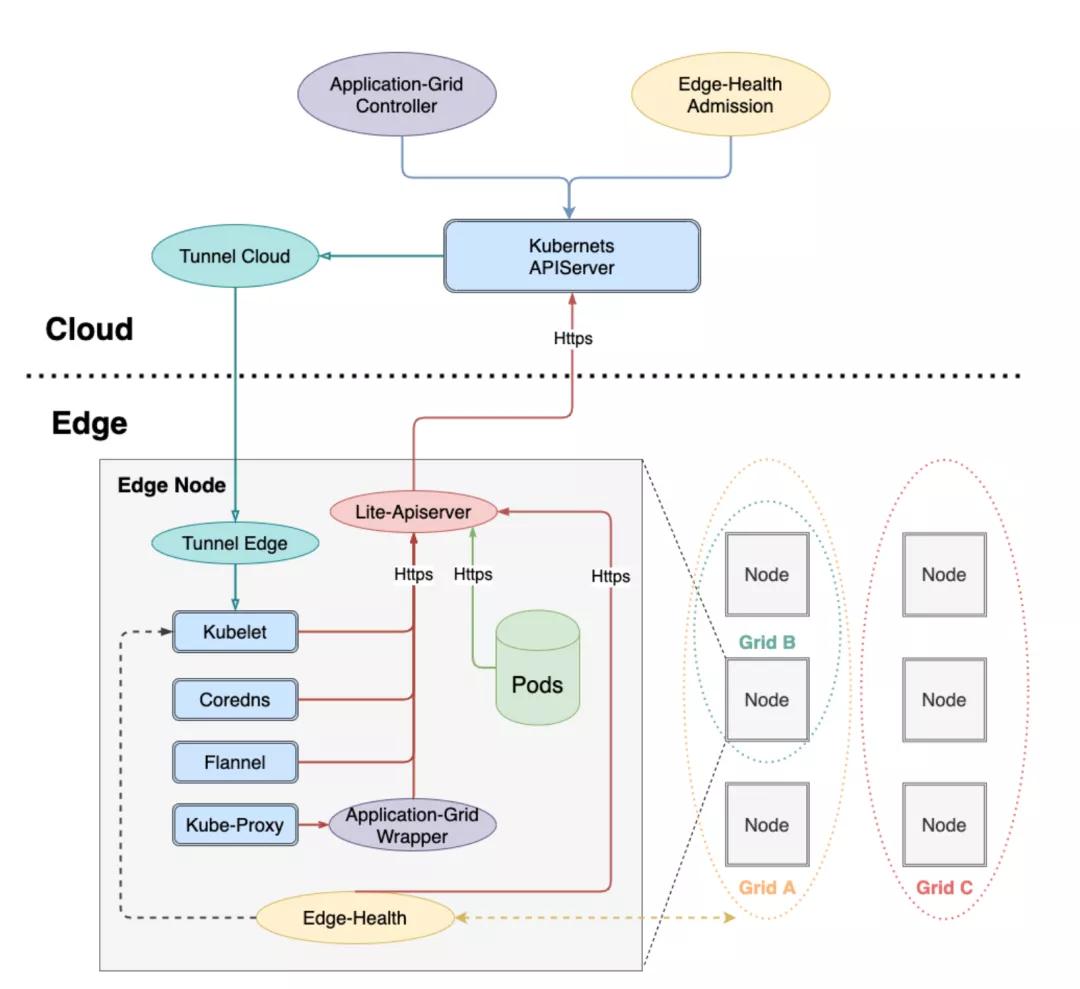
组件功能总结如下:
云端组件
云端除了边缘集群部署的原生Kubernetes master组件(cloud-kube-APIServer,cloud-kube-controller以及cloud-kube-scheduler)外,主要管控组件还包括:
- tunnel-cloud:负责维持与边缘节点tunnel-edge的网络隧道,目前支持TCP/HTTP/HTTPS协议。
- application-grid controller:服务访问控制ServiceGroup对应的Kubernetes Controller,负责管理DeploymentGrids以及ServiceGrids CRDs,并由这两种CR生成对应的Kubernetes deployment以及service,同时自研实现服务拓扑感知,使得服务闭环访问。
- edge-admission:通过边端节点分布式健康检查的状态报告决定节点是否健康,并协助cloud-kube-controller执行相关处理动作(打taint)。
边缘组件
边端除了原生Kubernetes worker节点需要部署的kubelet,kube-proxy外,还添加了如下边缘计算组件:
- lite-apiserver:边缘自治的核心组件,是cloud-kube-apiserver的代理服务,缓存了边缘节点组件对APIServer的某些请求,当遇到这些请求而且与cloud-kube-apiserver网络存在问题的时候会直接返回给client端。
- edge-health:边端分布式健康检查服务,负责执行具体的监控和探测操作,并进行投票选举判断节点是否健康。
- tunnel-edge:负责建立与云端边缘集群tunnel-cloud的网络隧道,并接受API请求,转发给边缘节点组件(kubelet)。
- application-grid wrapper:与application-grid controller结合完成ServiceGrid内的闭环服务访问(服务拓扑感知)。
3.2.2 实践
根据官方文档《superedge/README_CN.md at main · superedge/superedge (github.com)》部署测试
| 类型 | ip | 系统版本 | 架构 | 集群版本 | 端口开放 |
|---|---|---|---|---|---|
| 云端 | 47.108.201.47 | Ubuntu 18.04.5 LTS | amd64 | k8s-v1.19.8 + kubeedge-v1.8.1 | 开放端口 10000-10005 |
| 边缘 | 172.31.0.153 | Ubuntu 18.04.5 LTS | arm64 | kubeedge-v1.8.1 |
实践结论:
根据官方文档部署,边缘节点可以正常加入集群,但是无法部署服务至边缘节点,提了issue未回复,其他测试未再进行
3.3. Openyurt
3.3.1. 架构简介
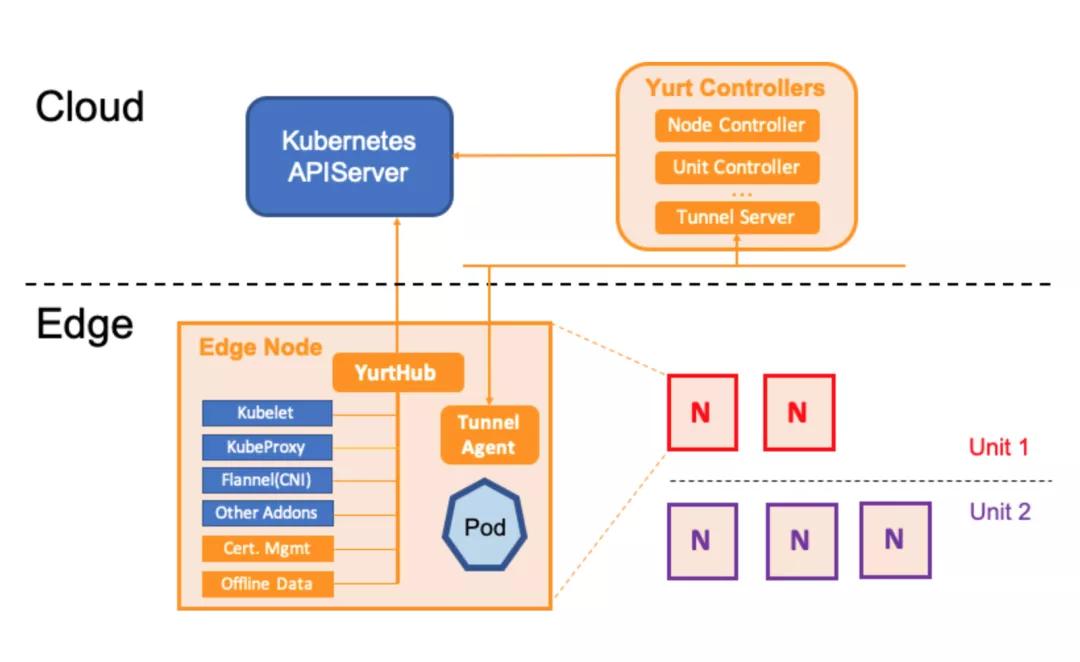
OpenYurt的架构设计比较简洁,采用的是无侵入式对Kubernetes进行增强。在云端(K8s Master)上增加Yurt Controller Manager, Yurt App Manager以及Tunnel Server组件。而在边缘端(K8s Worker)上增加了YurtHub和Tunnel Agent组件。从架构上看主要增加了如下能力来适配边缘场景:
- YurtHub: 代理各个边缘组件到K8s Master的通信请求,同时把请求返回的元数据持久化在节点磁盘。当云边网络不稳定时,则利用本地磁盘数据来用于边缘业务的生命周期管控。同时云端的Yurt Controller Manager会管控边缘业务Pod的驱逐策略。
- Tunnel Server/Tunnel Agent: 每个边缘节点上的Tunnel Agent将主动与云端Tunnel Server建立双向认证的加密的gRPC连接,同时云端将通过此连接访问到边缘节点及其资源。
- Yurt App Manager:引入的两个CRD资源: NodePool 和 UnitedDeployment. 前者为位于同一区域的节点提供批量管理方法。后者定义了一种新的边缘应用模型以节点池维度来管理工作负载。
3.3.2 实践
只根据官方文档了解其架构,未进行部署测试。
3.4. K3s
3.4.1 架构简介
K3S是CNCF官方认证的Kubernetes发行版,开源时间较KubeEdge稍晚。K3S专为在资源有限的环境中运行Kubernetes的研发和运维人员设计,目的是为了在x86、ARM64和ARMv7D架构的边缘节点上运行小型的Kubernetes集群。K3S的整体架构如下所示:
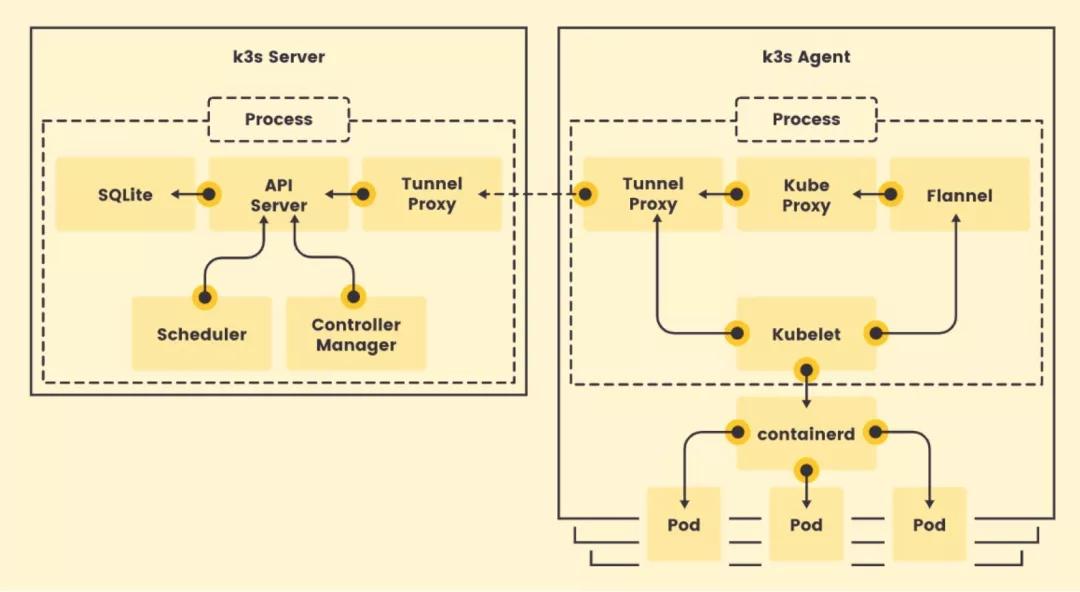
事实上,K3S就是基于一个特定版本Kubernetes(例如:1.13)直接做了代码修改。K3S分Server和Agent,Server就是Kubernetes管理面组件 + SQLite和Tunnel Proxy,Agent即Kubernetes的数据面 + Tunnel Proxy。
为了减少运行Kubernetes所需的资源,K3S对原生Kubernetes代码做了以下几个方面的修改:
- 删除旧的、非必须的代码。K3S不包括任何非默认的、Alpha或者过时的Kubernetes功能。除此之外,K3S还删除了所有非默认的Admission Controller,in-tree的cloud provider和存储插件;
- 整合打包进程。为了节省内存,K3S将原本以多进程方式运行的Kubernetes管理面和数据面的多个进程分别合并成一个来运行;
- 使用containderd替换Docker,显著减少运行时占用空间;
- 引入SQLite代替etcd作为管理面数据存储,并用SQLite实现了list/watch接口,即Tunnel Proxy;
- 加了一个简单的安装程序。K3S的所有组件(包括Server和Agent)都运行在边缘,因此不涉及云边协同。如果K3S要落到生产,在K3S之上应该还有一个集群管理方案负责跨集群的应用管理、监控、告警、日志、安全和策略等。
3.4.2 实践
官方文档:https://docs.rancher.cn/docs/k3s/installation/install-options/_index
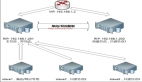
运维架构图
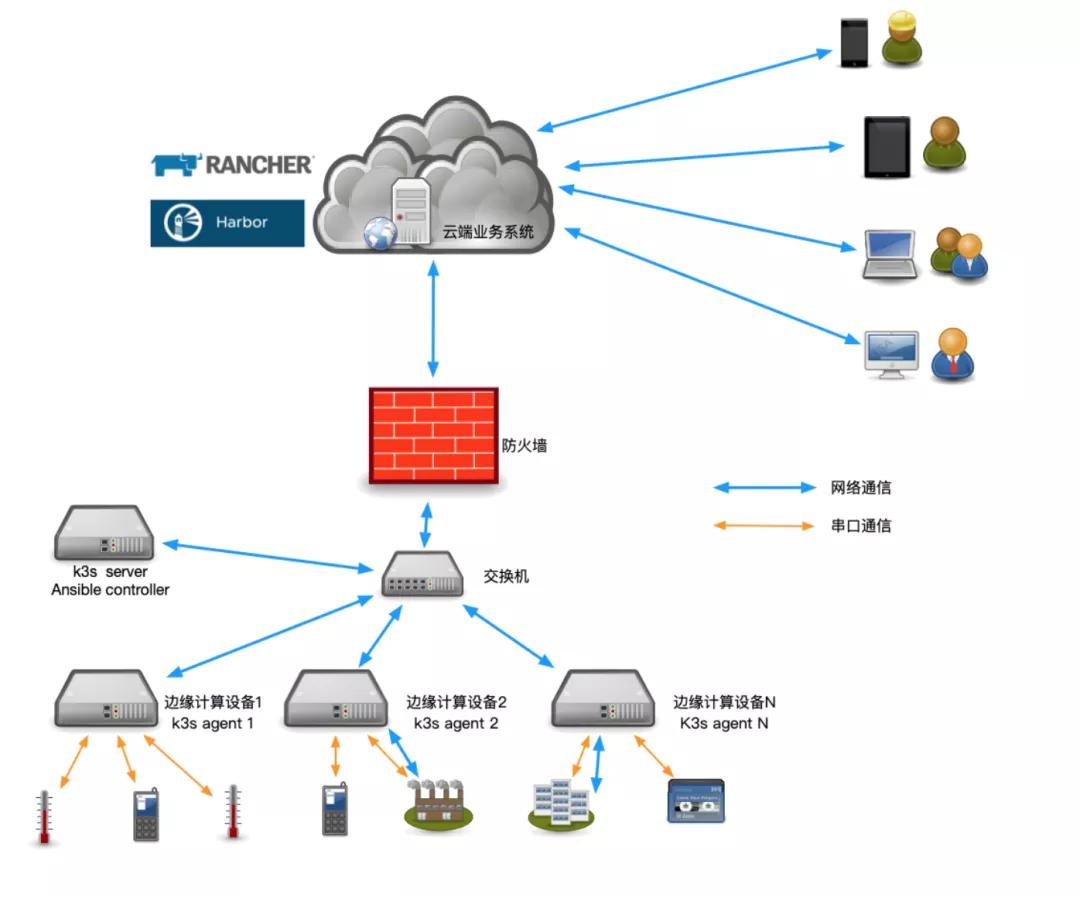
节点信息
k3s server—192.168.15.252
k3s agent—192.168.15.251
注意点:server一定要有免密登录agent权限!!!
总体思路
K3S部署Kubernetes集群,创建集群的https证书,Helm部署rancher,通过rancher的UI界面手动导入Kubernetes集群,使用Kubernetes集群。
使用脚本安装 Docker
- 安装GPG证书
- curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
- #写入软件源信息
- sudo add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
- sudo apt-get -y update
- #安装Docker-CE
- sudo apt-get -y install docker-ce
Kubernetes部署
在rancher中文文档中推荐了一种更轻量的Kubernetes集群搭建方式:K3S,安装过程非常简单,只需要服务器能够访问互联网,执行相应的命令就可以了。
k3s server主机执行命令,执行完成后获取master主机的K3S_TOKEN用于agent节点安装(默认路径:/var/lib/rancher/k3s/server/node-token)。
- curl -sfL http://rancher-mirror.cnrancher.com/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn INSTALL_K3S_EXEC="--docker" sh -s - server
k3s agent主机执行命令,加入K3S集群。
- curl -sfL http://rancher-mirror.cnrancher.com/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn INSTALL_K3S_EXEC="--docker" K3S_URL=https://192.168.15.252:6443 K3S_TOKEN=K10bb35019b1669197e06f97b6c14bb3b3c7c7076cd20afe1f550d6793d02b9eed8::server:9599c8b3ffbbd38b7721207183cd6a62 sh -
http://rancher-mirror.cnrancher.com/k3s/k3s-install.sh是国内的加速地址,可以正常执行。
执行完毕后,在server服务器上验证是否安装K3S集群成功。

4. 对比
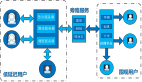
上述四种开源方案,其中KubeEdge、SuperEdge、OpenYurt,遵循如下部署模型:
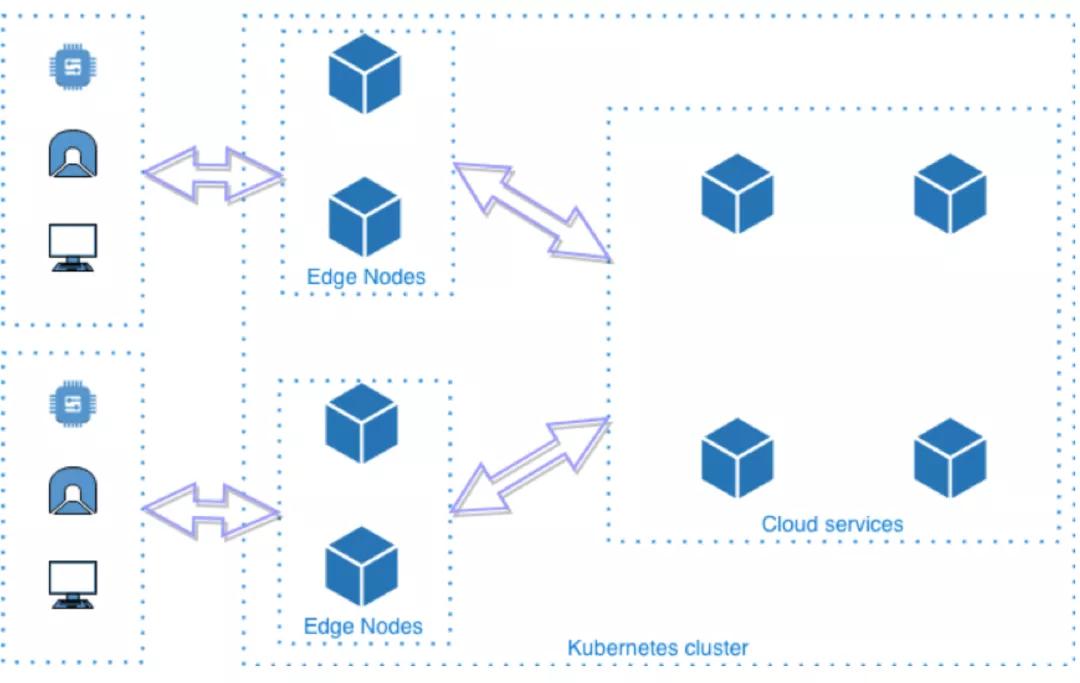
是一种完全去中心化的部署模式,管理面部署在云端,边缘节点无需太多资源就能运行Kubernetes的agent,云边通过消息协同。从Kubernetes的角度看,边缘节点 + 云端才是一个完整的Kubernetes集群。这种部署模型能够同时满足“设备边缘”和“基础设施边缘”场景的部署要求。
所以先基于这三种方案对比如下:
| 项目 | 华为KubeEdge | 阿里OpenYurt | 腾讯SuperEdge |
|---|---|---|---|
| 是否CNCF项目 | 是(孵化项目) | 是(沙箱项目) | 否 |
| 开源时间 | 2018.11 | 2020.5 | 2020.12 |
| 侵入式修改Kubernetes | 是 | 否 | 否 |
| 和Kubernetes无缝转换 | 无 | 有 | 未知 |
| 边缘自治能力 | 有(无边缘健康检测能力) | 有(无边缘健康检测能力) | 有(安全及流量消耗待优化) |
| 边缘单元化 | 不支持 | 支持 | 支持(只支持Deployment) |
| 是否轻量化 | 是(节点维度待确认) | 否 | 否 |
| 原生运维监控能力 | 部分支持 | 全量支持 | 全量支持(证书管理及连接管理待优化) |
| 云原生生态兼容 | 部分兼容 | 完整兼容 | 完整兼容 |
| 系统稳定性挑战 | 大(接入设备数量过多) | 大(大规模节点并且云边长时间断网恢复) | 大(大规模节点并且云边长时间断网恢复) |
| 设备管理能力 | 有(有管控流量和业务流量耦合问题) | 无 | 无 |
初步结论:
对比这三种方案,KubeEdge和OpenYurt/SuperEdge的架构设计差异比较大,相比而言OpenYurt/SuperEdge的架构设计更优雅一些。而OpenYurt和SuperEdge架构设计相似,SuperEdge的开源时间晚于OpenYurt,项目成熟度稍差。但是根据业界已经落地的生产方案,KubeEdge使用度及成熟度较高,同时OpenYurt/SuperEdge 开源时间较晚,还未进入CNCF孵化项目,同时结合实践过程中的测试情况,考虑KubeEdge。
接下来,再针对KubeEdge和K3s进行对比:
K3S的部署模型如下所示:
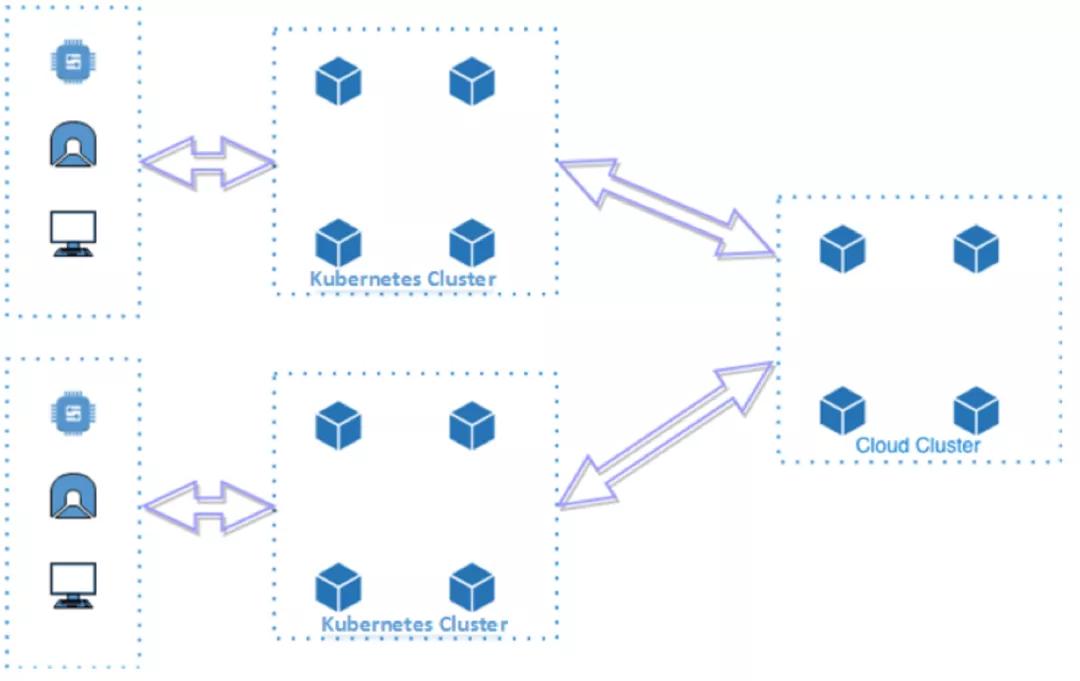
K3S会在边缘运行完整的Kubernetes集群,这意味着K3S并不是一个去中心化的部署模型,每个边缘都需要额外部署Kubernetes管理面,因此该部署模型只适合资源充足的“基础设施边缘”场景,并不适用于资源较少的“设备边缘”的场景;同时集群之间网络需要打通;为了管理边缘Kubernetes集群还需要在上面叠加一层多集群管理组件。
相关对比如下:
| 项目 | KubeEdge | K3s |
|---|---|---|
| 是否CNCF项目 | 是 | 是 |
| 开源时间 | 2018.11 | 2019.2 |
| 架构 | 云管边 | 边缘托管 |
| 边缘自治能力 | 支持 | 暂无 |
| 云边协同 | 支持 | 依赖多集群管理 |
| 原生运维监控能力 | 部分支持 | 支持 |
| 与原生K8s关系 | k8s+addons | 裁剪k8s |
| iot设备管理能力 | 支持 | octopus |
5. 总体结论
KubeEdge的一大亮点是云边协同,KubeEdge 通过 Kubernetes 标准 API 在云端管理边缘节点、设备和工作负载的增删改查。边缘节点的系统升级和应用程序更新都可以直接从云端下发,提升边缘的运维效率。但是云边协同访问需要借助EdgeMesh组件,其中包含server端和agent端,劫持了dns访问流量,进行转发,增加了网络复杂度,同时实际测试过程中发现边缘端服务之间无法通过svc进行访问。而k3s虽然不涉及到云边协同能力,但是针对加油站业务场景,可以将业务进行拆分为中心端和边缘端,中心侧业务复杂下发解码任务等,边缘侧只负责解码分析产生事件,并进行展示,也可以做到另一个层面的云边协同,相比于KubeEdge云边协同的访问方案来讲,不用部署额外组件,减少了网络复杂度,出问题也好排查。
KubeEdge的另一大亮点是边缘节点离线自治,KubeEdge 通过消息总线和元数据本地存储实现了节ku点的离线自治。用户期望的控制面配置和设备实时状态更新都通过消息同步到本地存储,这样节点在离线情况下即使重启也不会丢失管理元数据,并保持对本节点设备和应用的管理能力。而K3s在边缘节点是一套完整集群,所以及时和中心端网络断联,也同样并不影响当前业务的运行。
从轻量化的角度来看,k3s二进制文件大小50M,edgecore80M。资源消耗,由于k3s在边缘端是一套完整集群,所以资源消耗对比KubeEdge要高,但是针对加油站场景,边缘服务器内存配置较高,所以这一块也能接受。
从运维角度来看,k3s维护跟原生k8s类似,不增加额外组件,唯一难点是多集群管理,这一块可以调研rancher及其他多集群管理方案,同时golive2.0也支持一个部署同时部署至多集群。而KubeEdge如果要接入多个加油站,需要namespace隔离,部署涉及到加污点,容忍,同时需要支持一个部署包同时部署多个namespace,而且KubeEdge为了云边访问,额外加入EdgeMesh组件,转发流量,增加了网络复杂度,遇到问题,不易排查。
所以综合对比来看,建议选用k3s。