












本文转载自微信公众号「大数据左右手」,作者左右。转载本文请联系大数据左右手公众号。
了解背压
什么是背压
在流式处理系统中,如果出现下游消费的速度跟不上上游生产数据的速度,就种现象就叫做背压(backpressure,有人叫反压,不纠结,本篇叫背压)。本篇主要以Flink作为流式计算框架来简单背压机制,为了更好理解,只做简单分享。
背压产生的原因
下游消费的速度跟不上上游生产数据的速度,可能出现的原因如下:
(1)节点有性能瓶颈,可能是该节点所在的机器有网络、磁盘等等故障,机器的网络延迟和磁盘不足、频繁GC、数据热点等原因。
(2)数据源生产数据的速度过快,计算框架处理不及时。比如消息中间件kafka,生产者生产数据过快,下游flink消费计算不及时。
(3)flink算子间并行度不同,下游算子相比上游算子过小。
背压导致的影响
首先,背压不会直接导致系统的崩盘,只是处在一个不健康的运行状态。
(1)背压会导致流处理作业数据延迟的增加。
(2)影响到Checkpoint,导致失败,导致状态数据保存不了,如果上游是kafka数据源,在一致性的要求下,可能会导致offset的提交不上。
原理: 由于Flink的Checkpoint机制需要进行Barrier对齐,如果此时某个Task出现了背压,Barrier流动的速度就会变慢,导致Checkpoint整体时间变长,如果背压很严重,还有可能导致Checkpoint超时失败。
(3)影响state的大小,还是因为checkpoint barrier对齐要求。导致state变大。
原理:接受到较快的输入管道的barrier后,它后面数据会被缓存起来但不处理,直到较慢的输入管道的barrier也到达。这些被缓存的数据会被放到state 里面,导致state变大。
如何查找定位背压
(1)在web页面发现fink的checkpoint生成超时, 失败。
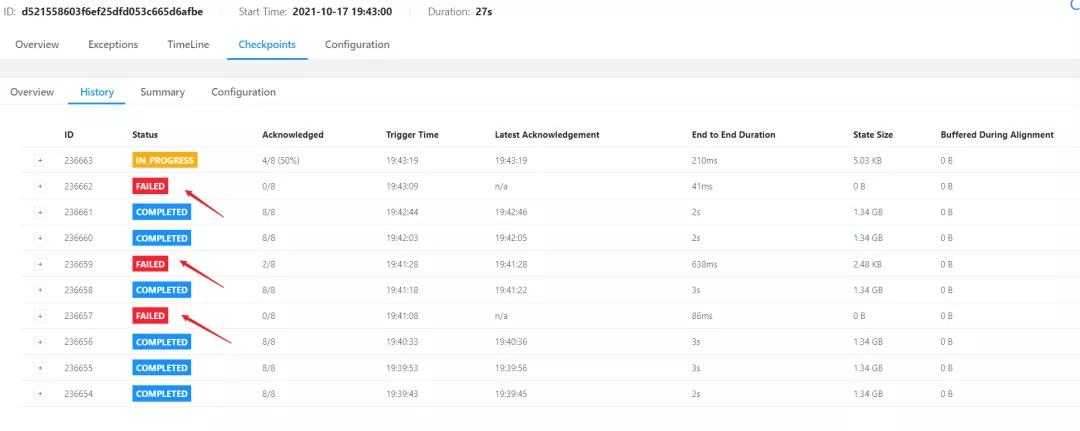
(2)查看jobmanager日志
2021-10-17 19:43:19,235 org.apache.flink.runtime.checkpoint.CheckpointCoordinator
-Checkpoint 236663 of job d521558603f6ef25dfd053c665d6afbe expired before completing
- 1.
- 2.
- 3.
- 4.
(3)在BackPressure界面直接可以看到。背压状态可以大致锁定背压可能存在的算子,但具体背压是由于当前Task自身处理速度慢还是由于下游Task处理慢导致的,需要通过metric监控进一步判断。
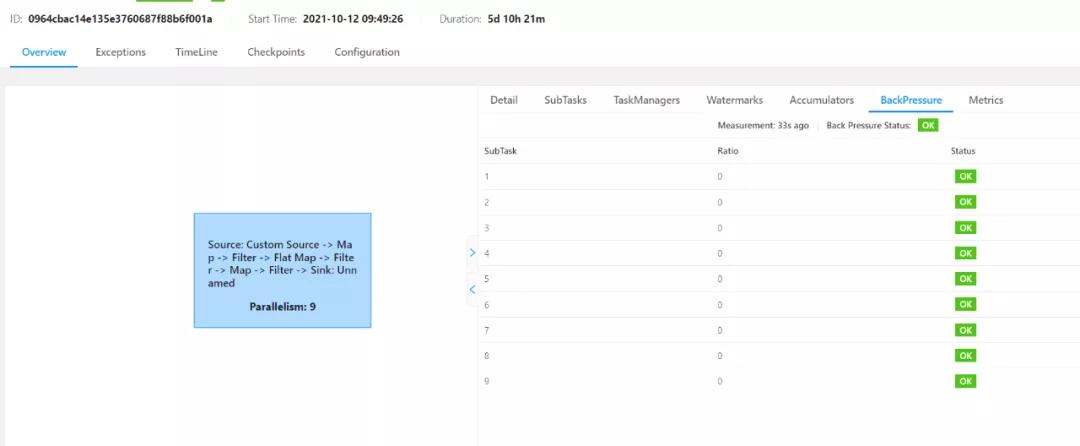
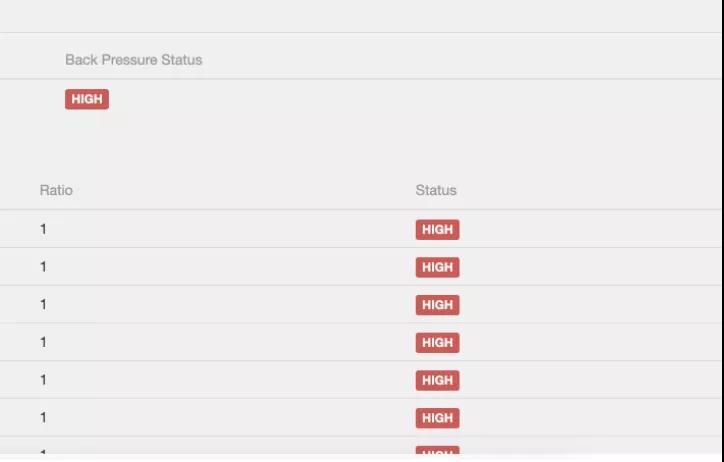
原理:BackPressure界面会周期性的对Task线程栈信息采样,通过线程被阻塞在请求Buffer的频率来判断节点是否处于背压状态。计算缓冲区阻塞线程数与总线程数的比值 rate。其中,rate < 0.1 为 OK,0.1 <= rate <= 0.5 为 LOW,rate > 0.5 为 HIGH。
(4)Metrics 监控背压。缓冲区的数据处理不过来,barrier流动慢,导致checkpoint生成时间长, 出现超时的现象。input 和 output缓冲区都占满。
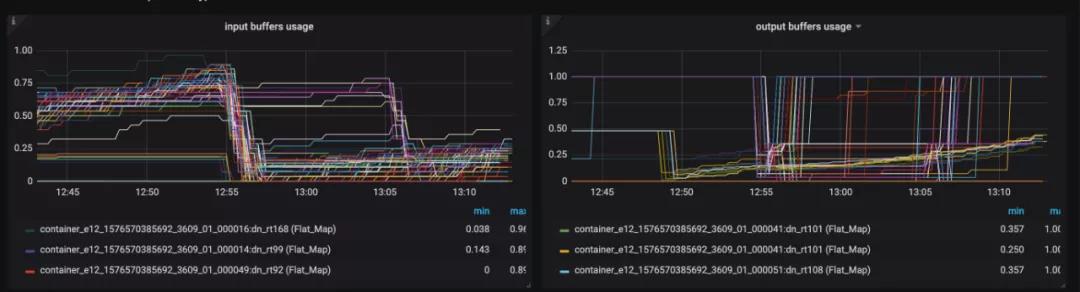
outPoolUsage 与 inPoolUsage
| 指标 | 描述 |
|---|---|
| outPoolUsage | 发送端Buffer的使用率 |
| inPoolUsage | 接收端Buffer的使用率 |
指标可能出现以下情况:
(1)outPoolUsage与inPoolUsage 都低,代表当前Subtask正常。
(2)outPoolUsage与inPoolUsage 都高,代表当前Subtask下游背压。
(3)outPoolUsage 高,通常是被下游 Task 所影响。
(4)inPoolUsage高,则表明它有可能是背压的根源。因为通常背压会传导至其上游,导致上游某些 Subtask 的 outPoolUsage 为高。
inputFloatingBuffersUsage 与 inputExclusiveBuffersUsage
| 指标 | 描述 |
|---|---|
| inputFloatingBuffersUsage | 每个 Operator 实例对应一个FloatingBuffers,inputFloatingBuffersUsage 表示 Operator 对应的FloatingBuffers 使用率。 |
| inputExclusiveBuffersUsage | 每个 Operator实例的每个远程输入 通道(RemoteInputChannel)都有自己的一组独占缓冲区(ExclusiveBuffer),inputExclusiveBuffersUsage表示 ExclusiveBuffer 的使用率。 |
指标可能出现以下情况:
(1)floatingBuffersUsage高,则表明背压正在传导至上游。
(2)floatingBuffersUsage 高、exclusiveBuffersUsage 低,则表明了背压可能存在倾斜。
背压的原理
基于 Credit-based Flow Control的背压机制
Credit 的反馈策略,保证每次上游发送的数据都是下游 InputChannel 可以承受的数据量。具体原理是这样的:
(1)上游 SubTask 给下游 SubTask 发送数据时,会把 Buffer 中要发送的数据和上游 ResultSubPartition堆积的数据量 Backlog size 发给下游,下游接收到上游发来的 Backlog size 后,会向上游反馈现在的 Credit值,Credit 值表示目前下游可以接收上游的 Buffer 量,1 个Buffer 等价于 1 个 Credit。上游接收到下游反馈的Credit 值后,上游下次最多只会发送 Credit 个数据到下游,保障不会有数据积压在 Socket 这一层。
(2)当下游 SubTask 反压比较严重时,可能就会向上游反馈 Channel Credit = 0,此时上游就知道下游目前对应的InputChannel 没有可用空间了,所以就不向下游发送数据了。
(3)上游会定期向下游发送探测信号,检测下游返回的 Credit 是否大于 0,当下游返回的 Credit 大于 0 表示下游有可用的Buffer 空间,上游就可以开始向下游发送数据了。
图集流程上面流程
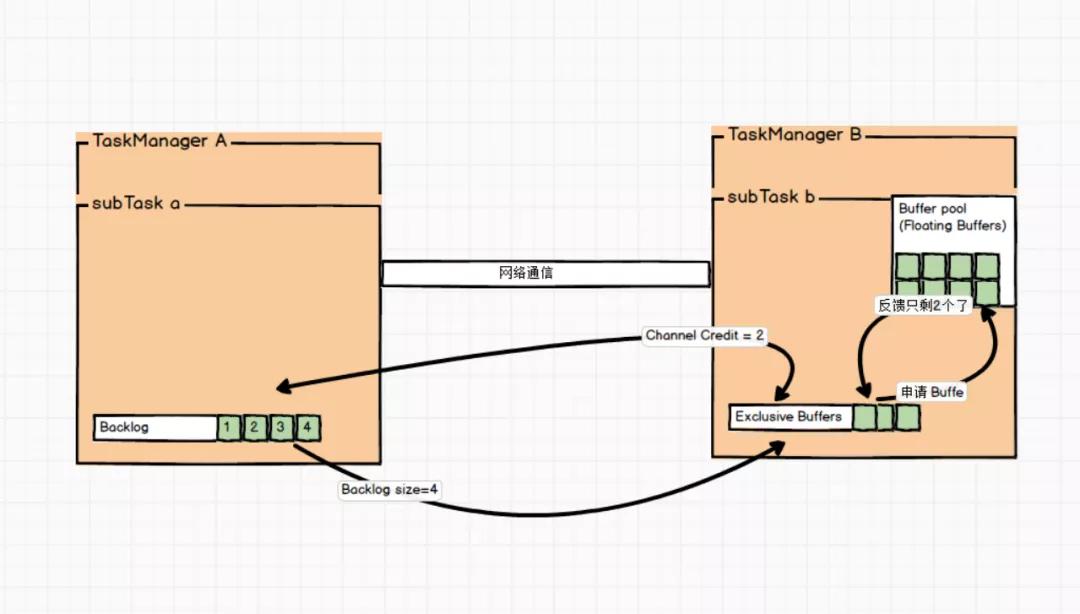
(1)上游 SubTask a 发送完数据后,还有 4 个 Buffer 被积压,那么会把发送数据和 Backlog size = 4 一块发送给下游 SubTask b。
(2)下游接受到数据后,知道上游积压了 4 个Buffer,于是向 Buffer Pool 申请 Buffer,由于容量有限,下游 InputChannel 目前仅有 2 个 Buffer 空间。
(3)SubTask b 会向上游 SubTask a 反馈 Channel Credit = 2。然后上游下一次最多只给下游发送 2 个 Buffer 的数据,这样每次上游发送的数据都是下游 InputChannel 的 Buffer 可以承受的数据量。
建议
参考官网【https://flink.apache.org/2019/07/23/flink-network-stack-2.html】
自行了解老版本TCP-based 背压机制,这里不再阐述。
解决背压
Flink不需要一个特殊的机制来处理背压,因为Flink中的数据传输相当于已经提供了应对背压的机制。所以只有从代码上与资源上去做一些调整。
(1)背压部分原因可能是由于数据倾斜造成的,我们可以通过 Web UI 各个 SubTask 的 指标值来确认。Checkpoint detail 里不同 SubTask 的 State size 也是一个分析数据倾斜的有用指标。解决方式把数据分组的 key 预聚合来消除数据倾斜。
(2)代码的执行效率问题,阻塞或者性能问题。
(3)TaskManager 的内存大小导致背压。





















