












python编译器在执行时,给它指定要执行的源码文件,或者说直接输入源码字符串就可以驱动脚本的执行流程,其基本框架如下:
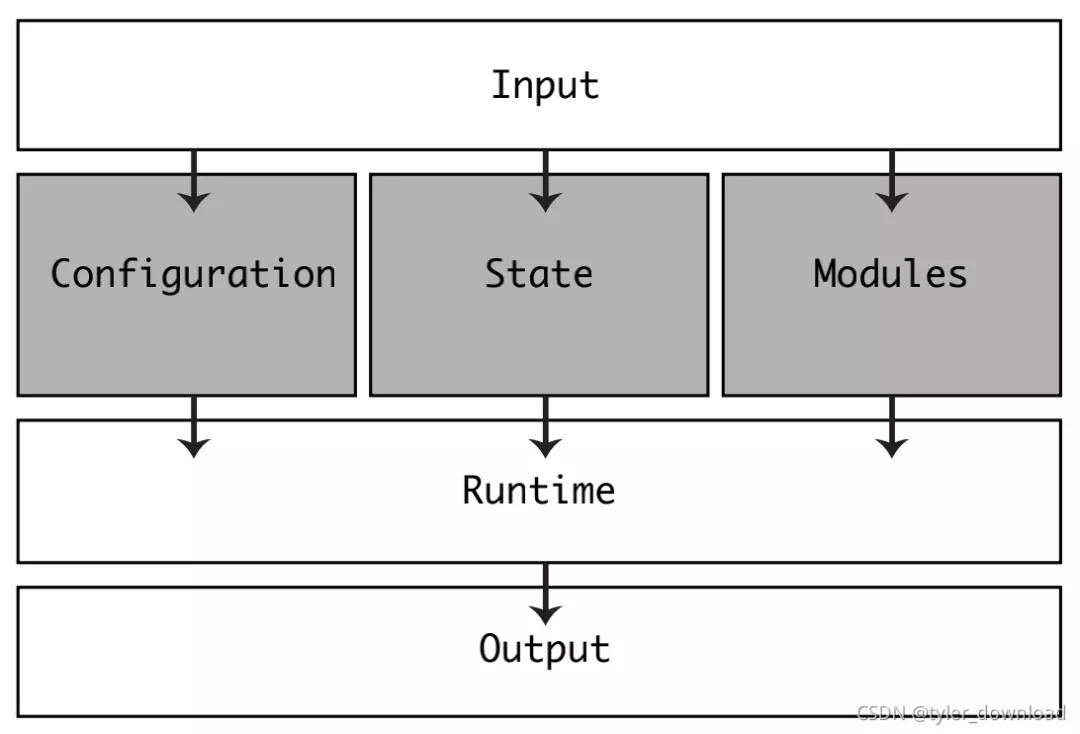
input层是python编译器用于获取源码的输入方式,事实上Python能够有多种方式将源码信息传递给编译器,例如:
1,执行python -c 然后接着python代码字符串。
2,python -m 然后跟着要执行的模块名
3,python 然后跟着脚本文件的路径
4,通过管道连接方式执行,例如 cat [file] | python
Python解释器不关心代码如何输入,只要它能获取源码内容即可,因此它专门设立了一个输入层来处理源码的读入。一旦获得源码内容后,解释器需要做三个动作,第一个是设置编译选项,如果你用过g++, gcc这类编译器,你一定了解执行时要有很多设置开关或选项,图中的configuration模块就负责这些选项的设置,State用来存储脚本中设定的各种变量,Module通过解读脚本后生成的一种便于脚本执行的数据结构。
以下我们会描述一些代码和数据结构,我们大概知道即可,不需要掌握或完全理解。我们看看解释器在运行脚本前进行相关配置的代码,相关代码在python目录下的initconfig.h和initconfig.c中。打开initconfig.c,然后搜索PyPreConfig结构体对象,然后按住ctrl并点击它就可以打开它的定义,它有些字段需要注意:
1,int allocator , 该字段对应内存分配器类型,它其实是个枚举值,用来选取不同的内存分配器。
2,int isolatd, 设置隔离模式,应该对应python虚拟执行环境,在该环境里进行pip安装或是环境变量配置不会对全局环境产生影响。
3,int utf8_mode , 设置utf-8模式
在initconfig.c中搜索PyConfig,这个结构体用于运行时配置,例如设置解释器在执行脚本时是出于调试模式还是优化模式,它还记录了一些涉及到运行时的环境变量配置。接下来我们在解释器源码中设置断点对其执行进行调试体验,操作如下图所示:
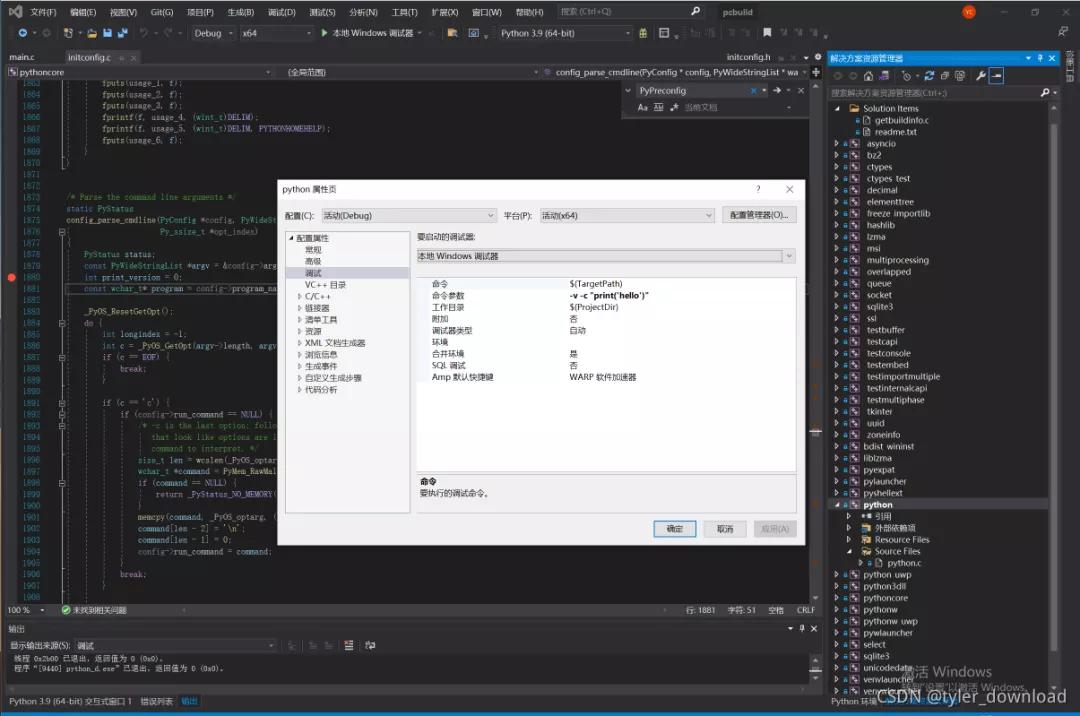
首先在python模块右键,选中属性,点击调试,在命令参数中输入python -v -c “print(‘hello world’)”,然后在函数config_parse_cmdline中设置断点,该函数应该在1875行,这个函数用于解读执行python解释器时的命令行参数,设置好后点击F5启动调试,我们会看到VS停在断点设置的地方,然后点击F10单步,我们可以看看该函数前面几个变量的内容:
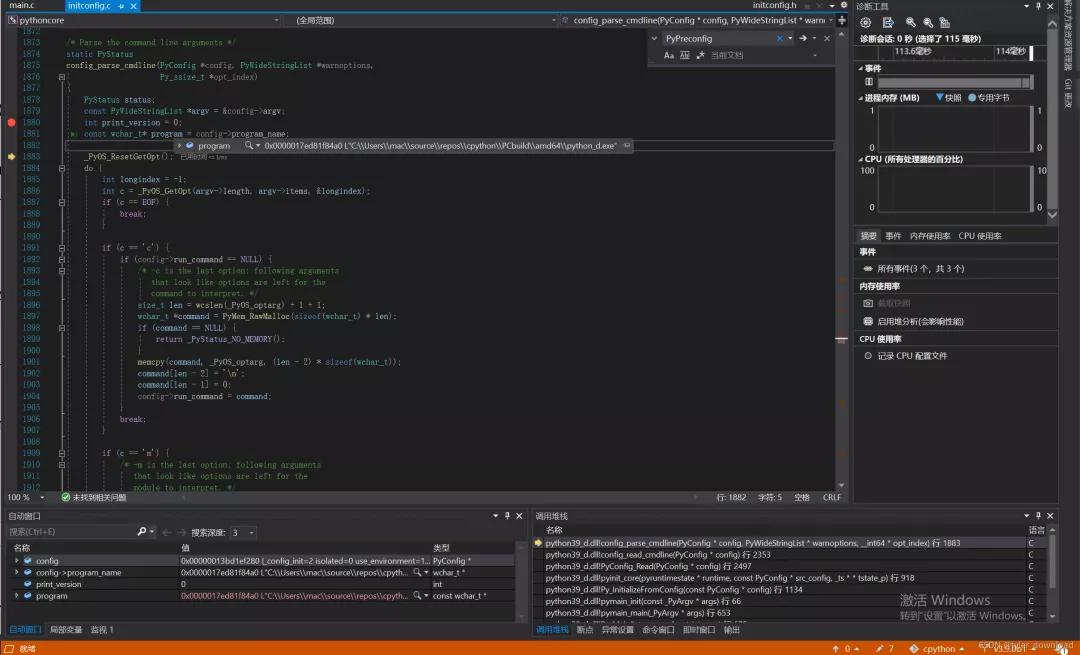
从中我们能看到Python解释器对应的可执行文件为python_d.exe,继续往下走可以看到代码进入case ‘v’,这里打开了verbose模式,这样Python解释器执行时会把很多信息打印出来。接下来在main.c中的pymain_run_command函数中设置断点,这个函数会调用一系列函数执行源码,该文件在Module目录下,
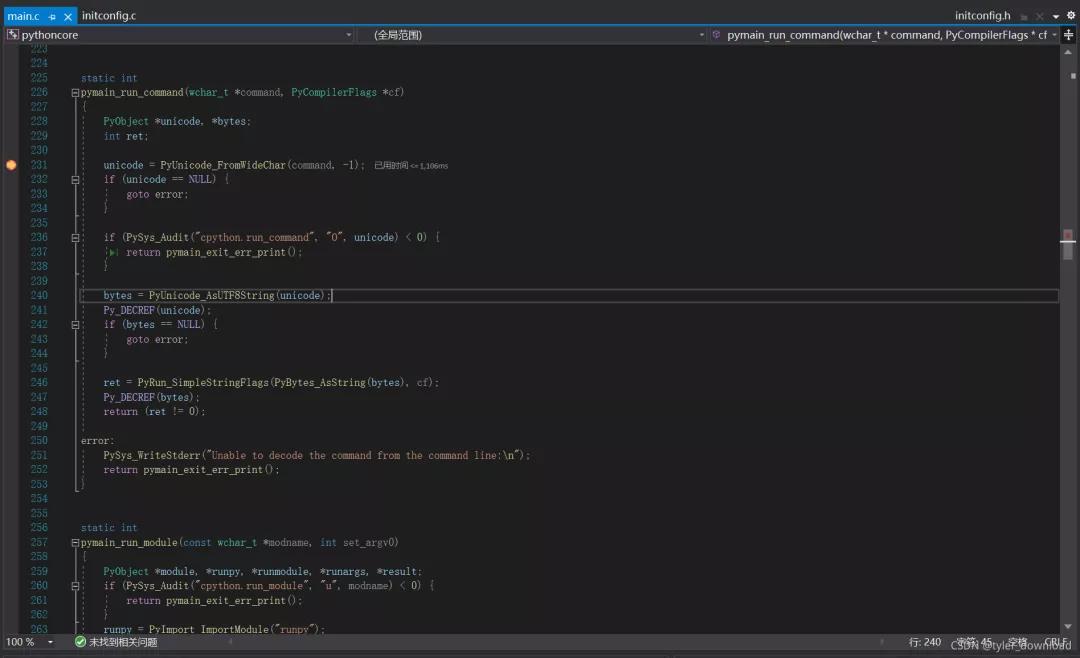
里面的PyRunSimpleStringFlags函数作用就是执行源码,我们单步运行该函数,然后打开控制台就会看到hello输出来了。上面代码中函数PyRunSimpleStringFlags的作用就是创建一个Module对象,一个Module对象就是含有__main入口的可执行模块。
















