













我们在工作中,经常用到 Excel,有时候,我们会使用 Pandas 生成 Excel。但生成的 Excel 列的顺序可能跟我们想要的不一样。
例如:
import pandas as pd
datas = [
{'id': 1, 'name': '王大', 'salary': 9999, 'work_time': 19},
{'id': 2, 'name': '李二', 'salary': 9999, 'work_time': 19},
{'id': 3, 'name': '张三', 'salary': 9999, 'work_time': 19},
{'id': 4, 'name': '朱四', 'salary': 9999, 'work_time': 19},
{'id': 5, 'name': '陈五', 'salary': 9999, 'work_time': 19},
{'id': 6, 'name': '老牛', 'salary': 9999, 'work_time': 19},
]
df = pd.DataFrame(datas)
df.to_excel('example.xlsx', index=False)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
运行效果如下图所示:
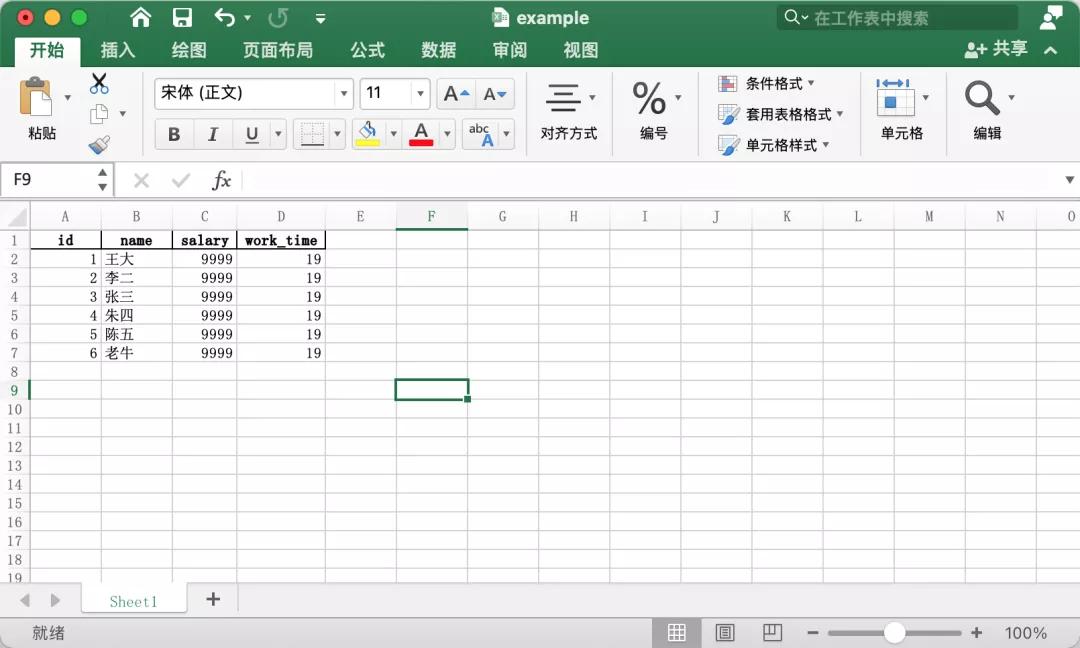
现在,我想在最终生成的 Excel 中,把work_time放到salary左边。这个时候,有两种方案:
方法1,把包含正确列表顺序的列表,传给 DataFrame 对象。
df = df[['id', 'name', 'work_time', 'salary']]
- 1.
运行效果如下图所示:
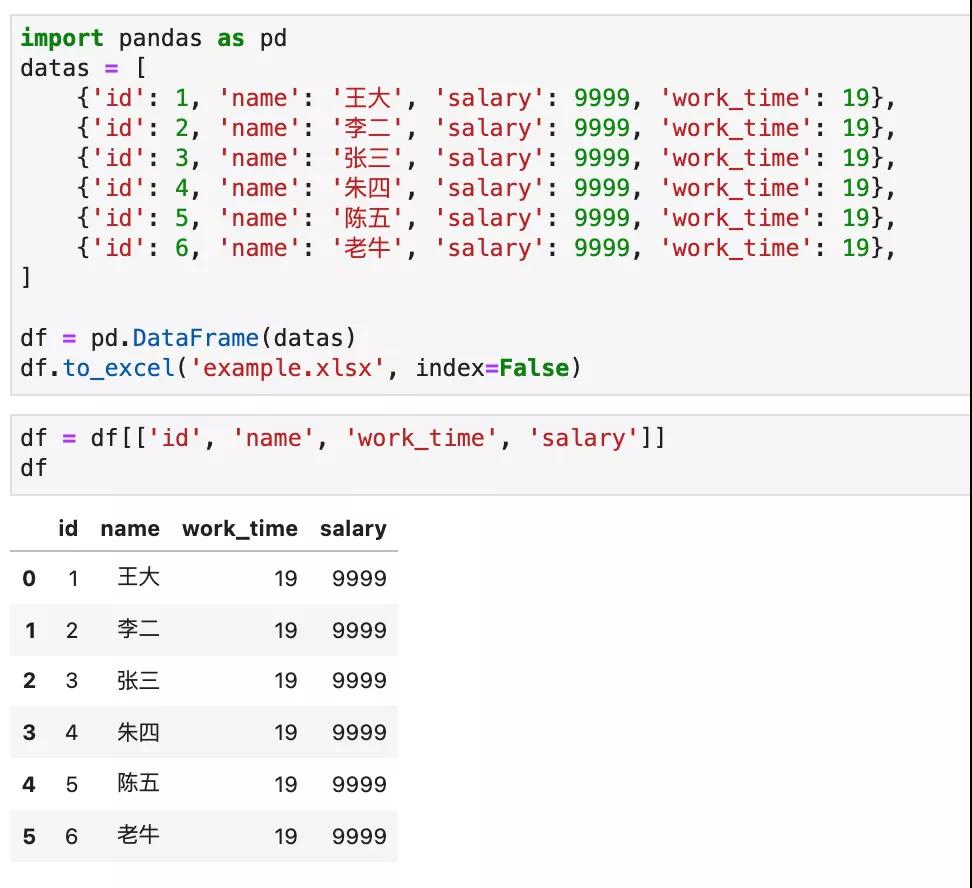
方法2,使用.reindex()方法:
df = df.reindex(columns=['id', 'name', 'work_time', 'salary'])
- 1.
运行效果如下图所示:

























