arXiv上2021年10月1日上传的论文“Motion Planning for Autonomous Vehicles in the Presence of Uncertainty Using Reinforcement Learning“,作者来自加拿大的华为诺亚实验室和魁北克大学。

存在不确定性的运动规划是开发自动驾驶车的主要挑战之一。本文专注于有限的视野、遮挡和传感距离限制导致的感知不确定性。通常是考虑遮挡区域或传感器感知范围之外的隐藏目标这个假设来解决这个问题,保证被动安全。然而,这可能导致保守的规划和昂贵的计算,特别是需要考虑大量假设目标存在时。
作者提出一种基于 强化学习 (RL) 的解决方案,对最坏情况结果通过优化处理不确定性。这种方法和传统的 RL 形成对比,传统 RL代理只是试图最大化平均预期奖励,是不安全和鲁棒的做法,而该方法建立在 分布RL (Distributional RL) 之上,其策略优化方法最大化随机结果的下限。这种修正方式可以应用于一系列 RL 算法。作为概念验证,这里应用于两种不同的 RL 算法, Soft Actor-Critic (SAC) 和 Deep Q-Network(DQN) 。
该方法针对两个具有挑战性的驾驶场景进行评估,即 遮挡情况下的行人穿越 和 有限视野的弯曲道路 。该算法用 SUMO 交通模拟器进行训练和评估。与传统的 RL 算法相比,所提出的方法用于生成更好的运动规划行为,与人类的驾驶风格相当。
RL方法主要有两种:基于价值和基于策略。本文分别讨论两种方法的不确定性问题。
分布RL (论文“ Distributional reinforcement learning with quantile regression ,” AA Conference on Artificial Intelligence, 2018)旨在估计每个状态-动作对可能结果的分布。 通过访问奖励分布,可以将一个状态的价值指定为其可能结果的最坏情况(下限)。
在RL中估计随机变量分布的一种有效方法是 分位数回归 ( Quantile Regression,QR) ,用 N 个分位数定义的分布,其第一个分位数是可能的奖励近似下限。这种方法, QR-DQN ,可以应用于任何包含价值函数的RL算法。 为此,需要增强价值函数,估计 N 个分位数,近似其分布。
用分位数回归(QR)来估计分位数价值时,回归过程会得到价值从最低到最高的排序。 因此,直接使用第一个价值作为下限估计。这个方法,称为 保守QR-DQN(CQR-DQN) 。
另一种 RL 算法 SAC(见论文“ Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor ,” ICLR 2018),遵循 Actor-Critic 框架。它 训练 Q -网络估计遵循策略的价值,并训练策略最大化 Q -值。 这里用分位数回归(QR)扩展 SAC,即 QR-SAC 。
实际上,Q -网络被扩展估计分位数。 然后类似于 QR-DQN,估计状态-动作对的 Q-值,即分位数第一个价值作为下限估计。依此,修改QR-DQN的分布Bellman方程,可以得到Critic的分布SAC Bellman更新规则。该方法,称为 保守QR-SAC(CQR-SAC) 。
在输入的感知中,OGM 提供有关遮挡区域的信息,道路网络的光栅图像,识别道路使用者可能存在的位置。 此外,希望运动规划器从 OGM 中感知目标,无需提供场景目标的任何明确信息。为解决这个运动规划问题,在 Frenet 框架搜索最佳轨迹。 这类似于 Frenet 框架的传统运动规划方法。
在 Frenet 框架中,沿着车道中心的轨迹变为直线轨迹, 简化了搜索空间。每个轨迹包括当前速度、当前横向偏距、最终速度和最终横向偏距。该轨迹建立之后,车辆速度和横向位置在预定的时间内按照一阶指数轨迹从初始值逐渐变化到最终值。
RL智体的输入包括 2 帧 (当前和之前时刻)OGM、道路网络的当前帧和当前速度,奖励定义为安全、舒适度和移动性等方面。
一个思路,从RL角度来看,如果智体动作被定义为轨迹,假设智体在未来状态的动作与当前状态的动作相同,那么评估轨迹等效于估计 Q-值。这样的算法分别记做 (CQR-DQN,CQR-SAC)价值版 。
另一个思路,在 RL 公式中未来状态的动作(轨迹)取决于智体策略,在知道未来动作可能与当前动作不同的情况下进行评估。 如果遵循智体策略,分配给状态-动作对的 Q-值是预期的奖励。这样的算法分别记做 (CQR-DQN,CQR-SAC)策略版 。
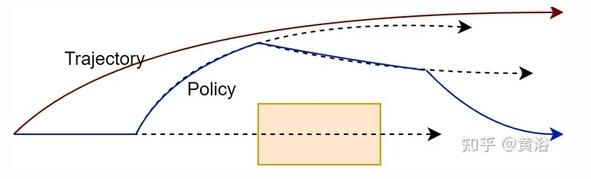
遵循和评估一个策略带来更大灵活性,并且运动规划器可能会找到更好的解决方案。如图所示说明在评估轨迹与策略时要评估的路径:
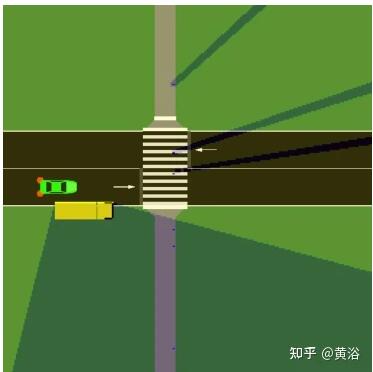
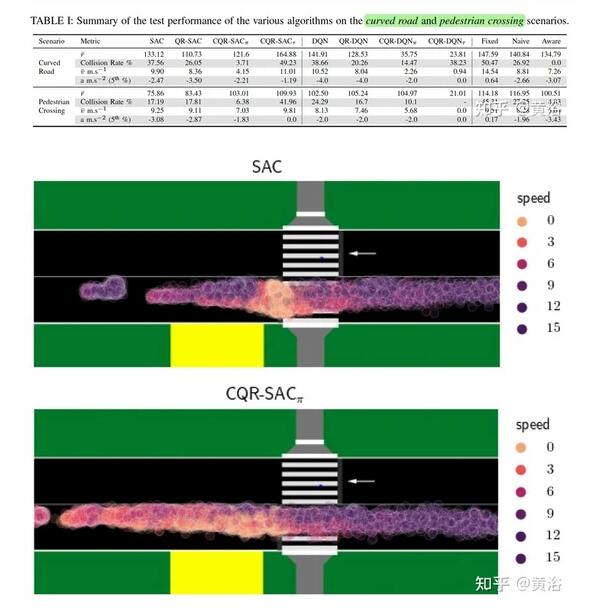
实验分两个场景。一是如图的行人过马路,有遮挡:
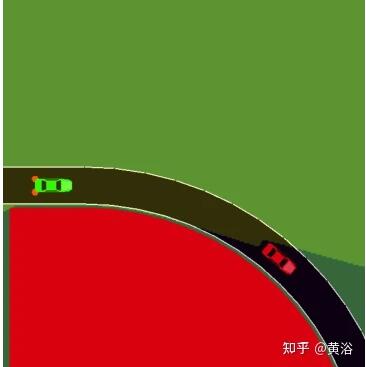
二是如图弯曲道路造成的遮挡:
实验采用SUMO模拟。比较的RL方法包括:SAC, QR-SAC, CQR-SAC策略版, CQR-SAC价值版, DQN, QR-DQN, CQR-DQN策略版, CQR-DQN价值版。
作为基准的规则方法有:固定fixed、幼稚naive和觉察 aware三种。
- 固定法 限速行驶,不考虑其他目标。
- 幼稚法 忽略遮挡,限速行驶,除非在其行驶路径看到一个目标。 这种情况下,它会以恒定减速度刹车,最高可达 -4 [m/s2],结果是在目标前停住。
- 觉察法 采用知道遮挡的 IADSR 算法(论文“ What lies in the shadows? safe and computation-aware motion planning for autonomous vehicles using intent-aware dynamic shadow regions ,” ICRA, 2019)。 假设一个目标存在于遮挡区域,如果一个目标从遮挡区域出现,那么它刹车减速(以 -4 [m/s2] 减速度)到完全停止而不会发生碰撞。 此外,觉察法还会远离遮挡机动以增加遮挡附近的视野。
实验结果比较如下:其中下标Pai是策略版,下标Tao是价值版。
这项工作针对由遮挡引起不确定性的运动规划问题,讨论在实际 RL 问题中,采用最大化最坏情况奖励的策略如何更好地匹配所需行为,利用分布RL 最大化最坏情况奖励而不是平均奖励。用分位数回归(QR)扩展 SAC 和 DQN,找到优化最坏情况的动作。
用 SUMO 模拟环境设计和评估一组遮挡情况下的自动驾驶运动规划器。提出基于 CQR-SAC和 CQR-DQN 的运动规划器,避免与被遮挡视图发生碰撞,无需微调奖励函数。
未来的工作想应用于更复杂和多样化的环境,包括交叉路口、环形交叉路口以及包含移动车辆的场景。工作期望是,自车智体可以从其他车辆的行为隐式地推断出遮挡区域的状态。