












大家好,我是志斌~
之前给大家介绍了一种SVG映射反爬虫,今天在给大家介绍另外一种通过映射关系来进行反爬虫的方式。
不知道大家有没有遇到过这种情况,在写爬虫程序之前我们需要对目标数据进行观察,但是在我们观察时发现目标数据在网页中是以这种奇怪的方式出现的。
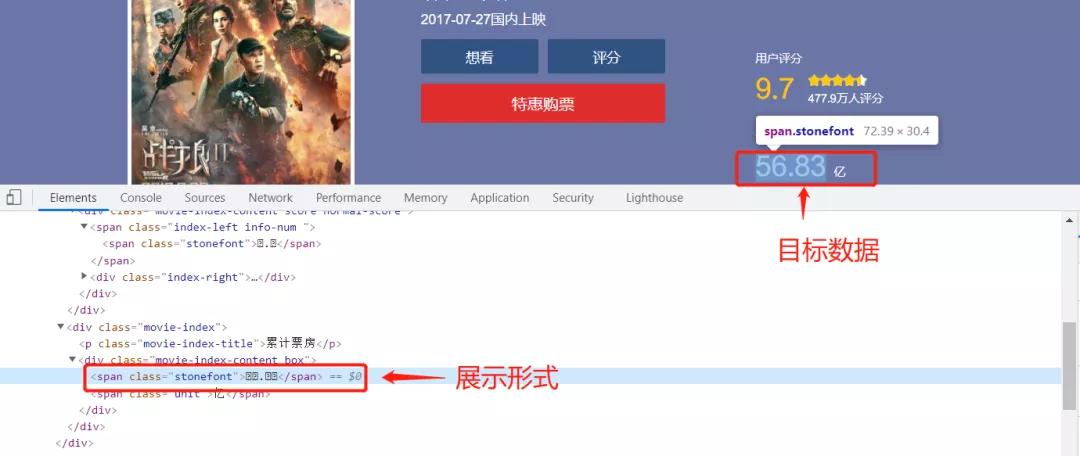
这种反爬虫就是字体反爬虫,今天志斌就来跟大家分享一下如何绕过这类反爬虫。
一、原理
在之前,网站开发者在设计网页时只能使用公用的字体来展示网页中的数据。
但是,随着CSS样式的深入开发,网站开发者可以将自己的字体放到服务器中。当用户在访问Web界面时,对应的字体就会被浏览器自动下载到用户的计算机中,然后通过CSS样式进行调用。
之后,通过一种映射关系,使得网页中的源数据变为真正的数据进行展示。
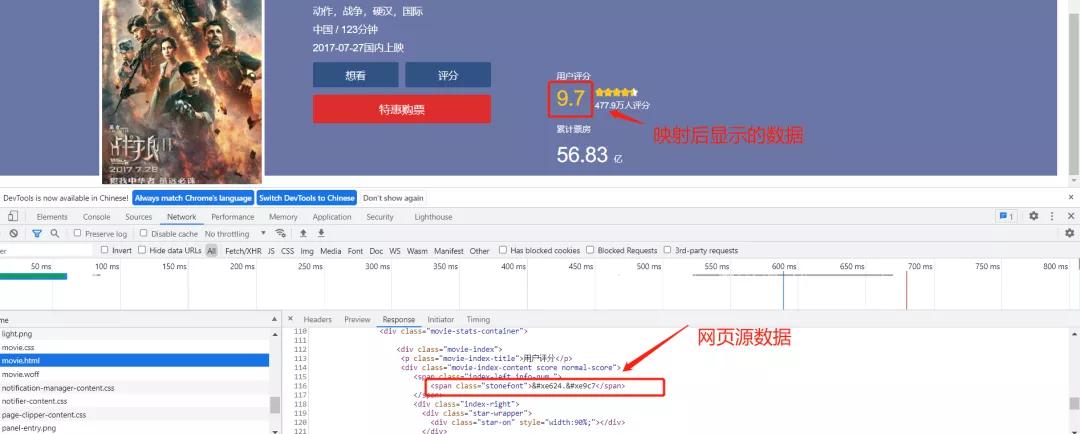
通过这种方式,使得这样就使得网站开发者进行网页设计时,只需要使用特殊字符进行占位即可,不需要将真正的数据放到页面中去。这样,爬虫程序如果不知道这种映射关系的话,就无法从字体中获取正确的数据,从而实现反爬虫。
二、破解
破解这类字体反爬虫有以下几步。
1.下载字体woff文件
从上面我们知道,字体是在服务器上进行存储,并通过浏览器下载到我们的电脑上的,那么我们就可以在网站上找到加载的字体文件,下载下来。

下载下来之后,打开它进行观察,这里给大家分享一个再点字体编译器网站,使用它可以很方便打开woff文件。网址:http://font.qqe2.com/index-en.html。
打开字体文件之后,我们发现,每个数字都对应一个字符串,如7对应的是$E9C7。

2.寻找映射关系
通过对源网页中的占位数据和字体进行比对,我们发现将源数据中的&#x替换成$,然后将字符串首字母大写,就变成了字体对应的字符串了。

3.构建映射算法
在上面我们已经找到了字体之间映射关系,那么我们现在就可以开始用Python来构建映射算法,从而使得爬虫可以获取一个正确的数据。
构建代码如下:
- data = {
- '' : 7,
- '' : 1,
- '' : 2,
- '' : 6,
- '' : 9,
- '' : 5,
- '' : 3,
- '' : 0,
- '' : 4,
- '' : 8,
- }
之后,我们即可对网页进行爬取,然后将对应的源数据与data进行比如,从而获得正确数据。
三、小结
1. 本文详细介绍了如何破解字体反爬虫,由于这种反爬虫是使用CSS进行加载和映射的,所以即使使用一些自动化软件或者渲染工具也无法获得真正的数据。
2. 这类反爬虫的破解只需要将woff文件中的字体与页面数据之间的对应关系找到,构建好即可。
3. 找到woff文件进行下载是关键。
4. 有兴趣的读者可以找志斌要一下网站自己尝试一下。
5. 本文仅供学习参考,不做它用。

















