












本文转自雷锋网,如需转载请至雷锋网官网申请授权。
人类是如何掌握这么多技能的呢?好吧,最初我们并非如此,但从婴儿时期开始,我们通过自监督发觉并练习越来越复杂的技能。但这种自监督并不是随机的——儿童发展文献表明,婴儿利用他们先前的经验,通过互动和感官反馈,对移动性、吸吮性、抓握性和消化性等可供性(affordance,也译作功能可供性、承担特质、直观功能、预设用途、可操作暗示、示能性等,指事物能够提示其可以帮助人们做什么的一种属性或特征)进行定向探索。这种类型的定向探索允许婴儿在既定环境中学习可以做什么以及如何做。那么,在机器人学习系统中,我们是否也可以实例一个类似于可供性定向探索的策略?
如下图所示。在左侧,我们先收集了由机器人完成各种任务的视频,比如打开和关闭抽屉、抓取和移动物体。在右侧,我们放置了一个机器人从未见过的盖子。机器人被给予一小段时间来熟悉这个新物体,之后它将获得一个目标图像,并负责使场景匹配这个图像。机器人如何在没有任何外部监督的情况下迅速学会操控环境并抓住盖子?

为此,我们面临几项挑战。当机器人被置于一个新环境时,它必须能够利用其先前的知识来思考环境可能提供的潜在有用行为。然后,机器人必须能够实际地练习这些行为。为了在新的环境中改进自己,机器人必须能够在没有外部奖励的情况下以某种方式评估自己的成功。
如果我们能可靠地战胜这些挑战,就能为一个强有力的循环打开大门。在这个循环中,我们的智能体使用先前的经验来收集高质量的交互数据,然后进一步增长它们以往的经验,不断提高它们的潜在效用!
1、VAL:视觉运动可供性学习
我们的方法,视觉运动可供性学习(Visuomotor Affordance Learning,简称VAL),解决了这些挑战。在VAL中,我们首先假设可以获得机器人在各种环境中展示可供性的先验数据集。至此,VAL进入了一个离线阶段,该阶段使用这些信息学习 1)想象新环境中有用的可供性生成模型,2) 用于有效探索这些可供性的强大离线策略,以及 3) 改进该策略的自我评估度量。最后,VAL已准备好进入在线阶段。智能体被放置在一个新的环境中,现在可以使用这些学到的功能来进行自监督的微调。整个框架如下图所示。随后,我们将深入探讨离线和在线阶段的技术细节。

2、VAL:离线阶段
给定一个展示各种环境可供性的先验数据集,VAL在三个离线步骤中消化这些信息:用于处理高维真实世界数据的表示学习,在未知环境中实现自监督练习的可供性学习,用于获得高性能的初始策略以加快在线学习效率的行为学习。
首先,VAL使用矢量量化变分自动编码器(VQVAE)学习该数据的低维表示。这个过程将我们的48x48x3图像压缩到144维的潜在空间。
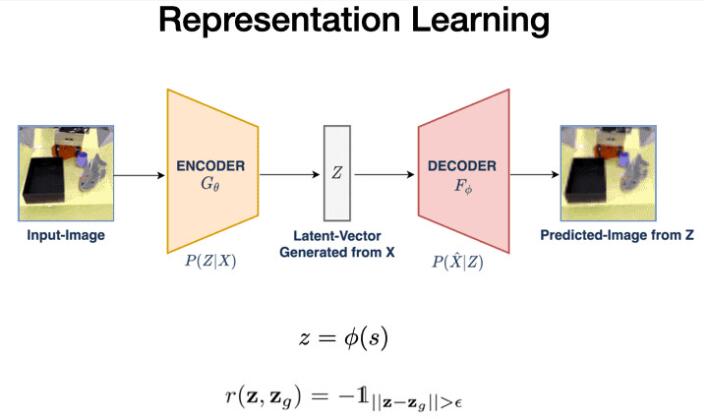
在这个潜在空间的距离是有意义的,为我们自我评价成功的关键机制铺平了道路。给定当前图像s和目标图像g,我们将它们编码进潜在空间,并设定它们可以获得奖励的距离阈值。
随后,我们还将使用这个表示作为我们潜在空间的策略和Q函数。
接下来,VAL 通过在潜在空间中训练 PixelCNN 来学习可供性模型,以学习以环境图像为条件的可达状态分布。这是通过最大化数据的似然 p(sn|s0) 来完成的。我们使用这种可供性模型进行定向探索和重新标记目标。
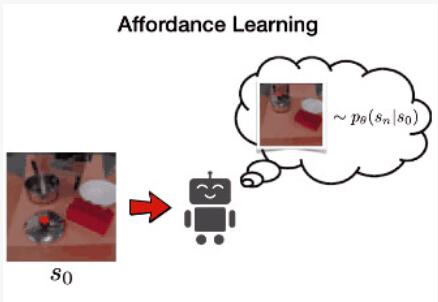
可供性模型如右图所示。在该图的左下方,我们看到条件图像包含一个罐子,右上方解码的潜在目标显示了不同位置的盖子。这些连贯的目标将允许机器人进行连贯的探索。
最后在离线阶段,VAL必须从离线数据中学习行为,然后可以通过额外的在线交互式数据收集进行改进。
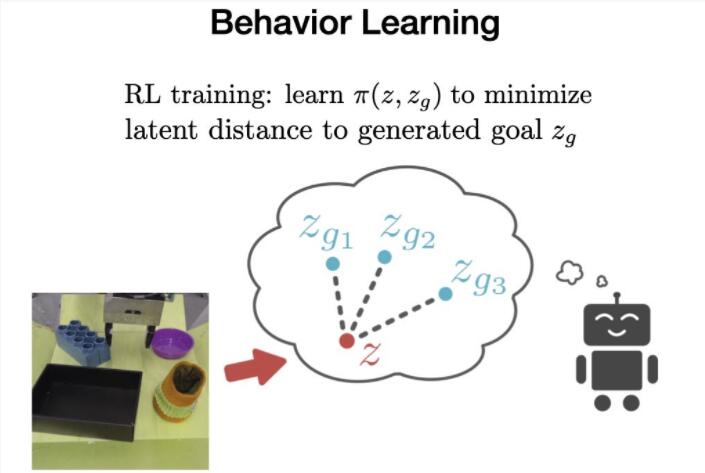
为了实现这一点,我们使用加权强化学习算法(Advantage Weighted Actor Critic)在先验数据集上训练目标条件策略,这是一种专为离线训练和在线微调而设计的算法。
3、VAL:在线阶段
现在,当VAL被放置在一个未见过的环境中时,它使用其先前的知识来想象有用可供性的视觉表示,通过尝试实现这些可供性来收集有用的交互数据,使用其自我评估指标更新其参数,并一直重复整个过程。
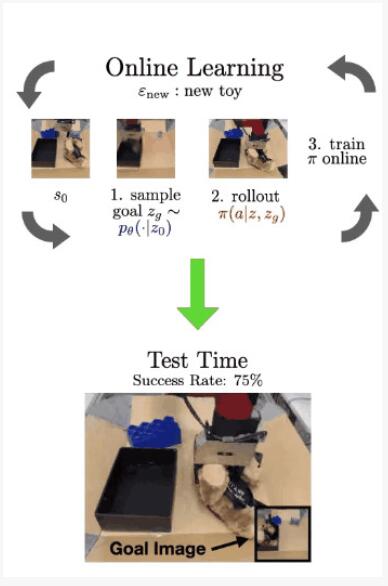
在这个真实的例子中,在左侧我们看到了环境的初始状态,它提供了打开抽屉和其他任务的功能。
在步骤1中,可供性模型对潜在目标进行采样。通过解码目标(使用 VQVAE 解码器,在RL期间从未实际使用过,因为我们完全在潜在空间中操作),我们可以看到可供性是打开抽屉。
在步骤2中,我们使用具有采样目标的训练策略。我们看到它成功打开了抽屉,实际上它拉太大力了,直接把抽屉拉了出来。但这为RL算法进一步微调和完善其策略提供了极其有用的交互。
在线微调完成后,我们现在可以评估机器人在每个环境中实现相应的未见过的目标图像的能力。
4、真实环境评估
我们在五个真实的测试环境中评估我们的方法,并评估VAL在无监督微调之前和五分钟之后完成环境提供的特定任务的能力。
每个测试环境至少包含一个未见过的交互对象和两个随机抽样的干扰对象。例如,当训练数据中有打开和关闭抽屉时,新的抽屉有没见过的把手。
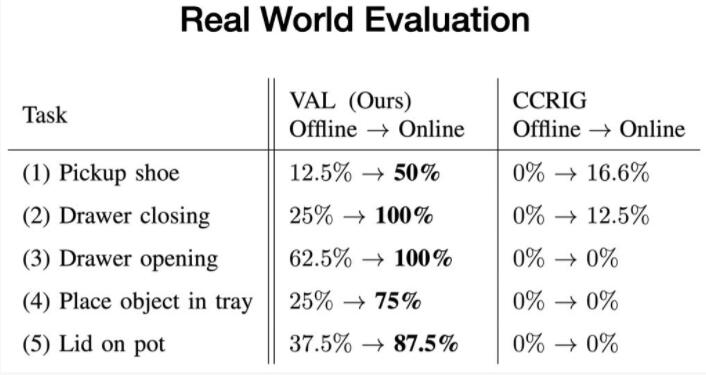
每个测试,我们都从离线训练策略开始,它每次完成任务的方式都不一致。然后,我们使用我们的可供性模型收集更多经验来采样目标。最后,我们评估经过微调的策略,它能始终一致地完成任务。

我们发现,在这些环境中,VAL在离线训练后始终显示出有效的零样本泛化,随后通过其可供性导向的微调方案快速改进。与此同时,先前的自监督方法在这些新环境中几乎没有改善。这些令人兴奋的结果表明,像VAL这样的方法具有使机器人成功操纵的潜力,远远超出它们现在习惯的有限的出厂设置。
我们的2,500个高质量机器人交互轨迹数据集,涵盖20个抽屉把手,20个锅把手,60个玩具和60个干扰物,现已在我们的网站上公开发布。
数据集地址:https://sites.google.com/view/val-rl/datasets
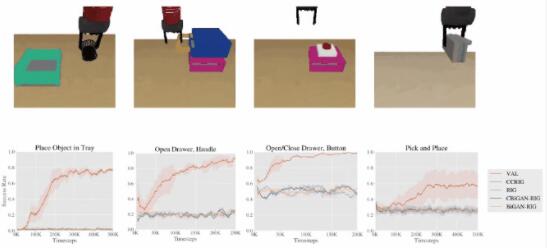
5、模拟评估与代码
为了进一步分析,我们在具有视觉和动态变化的程序生成的多任务环境中运行 VAL。场景中的对象以及它们的颜色和位置都是随机的。媒介可以用把手打开抽屉、抓取物体并移动它们、按按钮打开隔间等等。
给定机器人一个包含各种环境的先验数据集,并根据其在以下测试环境中的微调能力进行评估。
同样,给定一个单一的非策略数据集,我们的方法可以快速学习高级操作技能,包括抓取物体、打开抽屉、移动物体,以及对各种新对象使用工具。
环境和算法代码均已公开,请查阅我我们的代码库。
代码地址:https://github.com/anair13/rlkit/tree/master/examples/val
6、未来的工作
就像计算机视觉和自然语言处理等领域的深度学习是由大型数据集和泛化驱动的一样,机器人可能需要从类似规模的数据中学习。正因为如此,离线强化学习的改进对于使机器人能够利用大型先验数据集至关重要。此外,这些离线策略要么需要快速的非自主微调,要么需要完全自主的微调,以便在现实世界中部署是可行的。最后,一旦机器人独立运行,我们就能获得源源不断的新数据,这就强调了终身学习算法的重要性和价值。























