【51CTO.com快译】为了实现这种复杂的操作,必须有某种类型的服务“邮局”来跟踪所有请求和警报。实现这一目标的工具便是消息队列。
消息队列是一种专门的应用程序,它充当分布式应用程序的不同服务之间或不同应用程序之间的中介。它将应用程序服务彼此分离,确保无论消息接收者是否可用,都会进行处理。消息队列确保最终成功接收所有消息。
消息队列的常见用例包括:
- 不同应用程序之间的异步处理。
- 基于微服务的应用程序,其中不同组件之间的可靠通信至关重要。
- 事务排序和限制。
- 可以从批处理的简化效率中受益的数据处理操作。
- 必须可扩展以满足突然和意外需求变化的应用程序。
- 应用程序必须具有足够的弹性才能从崩溃和意外故障中恢复。
- 通过长时间运行的进程限制资源消耗。
消息队列领域不乏供应商。像Amazon Web Services、Microsoft Azure和谷歌cloud这样的大型云平台都有自己的产品(AWS Simple Queue Service、Azure的服务总线和谷歌的Pub/Sub)。也有独立的通用消息代理,如RabbitMQ、Apache的ActiveMQ和Kafka。
本文介绍了一个名为KubeMQ的现代Kubernetes原生消息队列,以尝试让已经在Kubernetes上使用kafka的组织如何从中受益。
什么是Apache Kafka
要了解 KubeMQ 的全部价值,我们首先需要花一些时间来了解 Kafka。Kafka 最初由 LinkedIn 工程师创建,作为跟踪 LinkedIn 用户活动的软件总线。它后来作为开源产品发布,今天,Kafka 由 Apache 软件基金会开发和管理。
Apache 指出,超过 80% 的财富 100 强公司信任并使用 Kafka。尽管是开源的,但众所周知它是一个高度可扩展的系统,可以连接到广泛的事件生产者和消费者。它可以配置为使用数据流执行复杂的功能,即使在有限的网络环境中也能很好地工作。凭借在线用户社区中广泛可用的支持,Kafka 还提供多种商业产品。例如,AWS 提供托管 Kafka,Confluent 也是如此。
Kafka的局限性
尽管采用率很高,但 Kafka 并不总是作为消息队列系统的最佳选择。它具有单体架构,适用于本地集群或高端多虚拟机设置。鉴于 Kafka 需要多少内存和存储空间,在独立工作站上快速启动多节点集群以进行测试可能是一项挑战。
简而言之,将 Kafka 与你的基础设施集成所需的所有复杂部分成功地整合在一起并不容易。对于基于 Kubernetes 的架构尤其如此。
如下图所示,基于 Kubernetes 的 Kafka 部署有不同的活动部分。除了为基本 Kubernetes 集群配置底层计算、网络和存储基础设施(如果你在本地实施),你还需要安装所有 Kafka 部分并将其与 Helm 等包管理器集成。这些组件可以包括一个协调器,如 ZooKeeper 或 Mesos,用于管理 Kafka 的代理和主题。其他需要注意的地方包括依赖、日志、分区等。如果甚至缺少一个元素或配置错误,事情都不会奏效——成功部署 Kafka 并非易事。
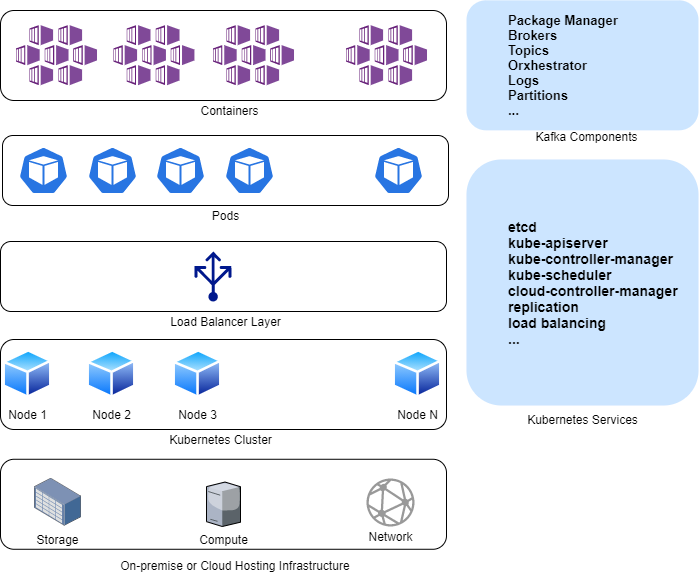
Kafka on Kubernetes 架构
将新的 Kafka 节点添加到 Kubernetes 集群需要复杂的手动平衡以保持最佳资源使用。这就是为什么没有简单的方法来管理和确保可靠的备份和恢复策略;对运行在大量节点上的 Kafka 集群进行防灾并不容易。与 Kubernetes 集群中的数据保存在 pod 之外,并且编排器自动启动失败的 pod 不同,Kafka 没有这样的原生防故障机制。
最后,对 Kafka/ZooKeeper/Kubernetes 部署的有效监控需要第三方工具。
什么是KubeMQ
Kube MQ 是一种消息服务,从头开始构建时就考虑到了 Kubernetes。遵循容器架构最佳实践,KubeMQ 旨在实现无状态和短暂的。也就是说,一个 KubeMQ 节点将在其整个生命周期内保持不变、可预测和可重现。如果需要更改配置,则会关闭并更换节点。
这种可重复性意味着,与 Kafka 不同,KubeMQ 带有零配置设置,安装后无需调整配置。
KubeMQ 旨在适应最广泛的消息模式。它是一个消息代理和消息队列,支持以下内容:
- 具有或不具有持久性的 Pub/Sub
- 请求/回复(同步、异步)
- 最多一次交货
- 至少一次交付
- 流媒体模式
- RPC
相比之下,Kafka 只支持具有持久性和流式传输的 Pub/Sub。Kafka 根本不支持 RPC 和请求/回复模式。
在资源使用方面,KubeMQ 以最小的占用空间胜过 Kafka。KubeMQ docker 容器仅占用 30MB 空间。如此小的占地面积有助于容错设置和简化部署。与 Kafka 不同,将 KubeMQ 添加到本地工作站中的小型开发 Kubernetes 环境非常简单。但与此同时,KubeMQ 具有足够的可扩展性,可以部署在运行在数百个本地和云托管节点上的混合环境中。这种易于部署的核心是kubemqctl,它是KubeMQ的命令行界面工具,类似于 Kubernetes 的 kubectl。
KubeMQ 优于 Kafka 的另一个方面是它的速度。Kafka 是用 Java 和 Scala 编写的,而 KubeMQ 是用 Go 编写的,确保快速运行。在内部基准操作中,KubeMQ 处理 100 万条消息的速度比 Kafka 快 20%。
回到 KubeMQ 的“免配置”方面,通道是开发人员唯一需要创建的对象。你可以忘记代理、交换和协调器——KubeMQ 的 Raft 代替 ZooKeeper 完成所有这些工作。
从监控的角度来看,通过 Prometheus 和 Grafana 的仪表板与 KubeMQ 完全集成,因此你无需手动集成第三方可观察性工具的额外工作。但是,由于 KubeMQ 与工具的原生集成,你仍然可以使用现有的日志记录和监控解决方案,包括:
- Fluentd、Elastic 和 Datadog,用于监控
- Loggly,用于记录
- Jaeger 和 Open Tracing,用于跟踪
由于Kafka 不是云原生计算基金会 (CNCF) 环境的原生部分,因此通常不支持与 CNCF 工具的集成,必须手动配置。
如果配置好,可以通过开源的gRPC远程过程调用系统进行连接,其与Kubernetes的卓越兼容性是众所周知的。Kafka 自己专有的连接机制不一定能提供可比的结果。
从 Kafka 到 KubeMQ 的透明迁移
除了 KubeMQ 的部署和操作简单之外,将现有的 Kafka 设置移植到 KubeMQ 也很简单。
为此,开发人员可以从使用 KubeMQ Kafka 连接器开始。KubeMQ 目标和源连接器被配置为转换来自 Kafka 的消息。在高层次上,KubeMQ 源连接器作为订阅者消费来自 Kafka 源主题的消息,将消息转换为 KubeMQ 消息格式,然后将消息发送到内部日志。KubeMQ 目标连接器订阅包含转换消息的输出日志,然后将消息发送到 Kafka 中的目标主题。高层架构如下图所示:
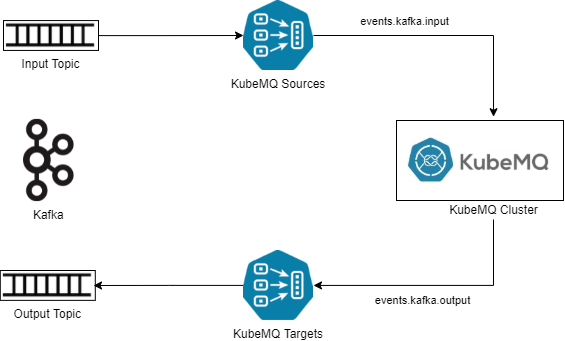
Kafka 与 KubeMQ 的集成
此外,Kafka 支持的任何消息传递模式都由 KubeMQ 支持。例如,Kafka 仅支持具有持久性和流的 Pub/Sub。KubeMQ 是一个消息队列和消息代理,支持 Pub/Sub(有或没有持久化)请求/回复(同步、异步)、至少一种交付、流模式和 RPC。因此,从 Kafka 迁移到 KubeMQ 时,无需重构应用程序代码并适应复杂的逻辑变化。
最后
对于大多数工作负载,KubeMQ内置的简单性、轻量级和容器优先集成将提供优于 Kafka 的性能。此外,所需的几乎为零的配置将节省大量的管理和设置时间。正如我们提到的,迁移很简单。
KubeMQ 是免费下载的,附带六个月的免费开发试用版。如果你使用 OpenShift,可以在 Red Hat Marketplace 中使用 KubeMQ 。它还适用于所有主要云环境,包括 GCP、AWS、Azure 和 DigitalOcean。
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】