














1. Pyquery的安装
在使用pyquery解析库之前,首先简单介绍一下pyquery然后讲解如何安装pyquery库。
- pyquery的基础概念
Pyquery也是一个功能很强大的网页解析库,它支持对xml、html文档进行jQuery查询。
- 安装pyquery
pyquery的安装其实很简单,下面介绍两种不同的安装方式(适用不同的操作系统)。
- #方式一:pip安装 pip install pyquery
- #方式二:wheel安装
- #下载对应系统版本的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/
- pip install pyquery-1.4.3-py3-non-any.whl
方式一:安装比较简单,通过pip install pyquery命令就可以直接安装;
方式二:首先需要下载whl文件,然后再去安装。
其下载链接为:http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml。
进入这个链接后找到pyquery-1.4.3-py3-none-any.whl,并将其下载到本地。
2. Pyquery的使用方法
通过上述方法安装好pyquery之后,我们开始导入pyquery,并通过一个例子去了解pyquery的基本使用方法。首先构造了一段html源码,然后初始化为pyquery对象。
完整代码如下:
- from pyquery import PyQuery as pq
- html = '''
- <div id = "container">
- <ul>
- <li>第1个</li>
- <li><a href = "link2.html">第2个</a></li>
- <li class = "i0 active"><a href = "link3.html"><span>第3个</span></a></li>
- <li class = "i1 active"><a href = "link4.html">第4个</a></li>
- <li><a href = "link5.html">第5个</a></li>
- </ul>
- </div>
- '''
- py= pq(html)
- 获取标签元素
目标:比如我们需要获取html中的li标签
- #方式一
- print(py('li'))
- #方式二
- # 注意下面id 前面需要加上#,class 前面需要加上.
- print(py('#container .list li'))
这里有两种获取方式,第一种比较简单,第二种方法定位更加准确。针对上述的html源码,这两种方式获取的结果是一样的,其结果如下:
- <li>第1个</li>
- <li><a href="link2.html">第2个</a></li>
- <li class="i0 active"><a href="link3.html"><span>第3个</span></a></li>
- <li class="i1 active"><a href="link4.html">第4个</a></li>
- <li><a href="link5.html">第5个</a></li>
- 查询子级标签元素
目标:获取class为list的ul标签下的所有子标签(li标签),其代码如下:
- items = py('.list')
- lis = items.children()
- print(lis)
最后打印输出的结果同上,都是把所有的li标签打印输出。
- 查询父级标签元素
目标:获取class为list的ul标签的上一级标签(div标签),其代码如下:
- items = py('.list')
- pa = items.parent()
- print(pa)
打印输出结果:
- <div id="container">
- <ul>
- <li>第1个</li>
- <li><a href="link2.html">第2个</a></li>
- <li class="i0 active"><a href="link3.html"><span>第3个</span></a></li>
- <li class="i1 active"><a href="link4.html">第4个</a></li>
- <li><a href="link5.html">第5个</a></li>
- </ul>
- </div>
- 获取元素信息
目标:获取class为i0 active的a标签元素,并提取出a标签元素的相关信息
- a = py('.i0.active a')
- # 标签内容
- print(a)
- # 获取属性(两种方式)
- print(a.attr.href)
- print(a.attr('href'))
- # 获取文本
- print(a.text())
- # 获取<a>标签里的源码
- print(a.html())
结果:
- <a href="link3.html"><span>第3个</span></a>
- link3.html
- link3.html
- 第3个
- <span>第3个</span>
3. 实战:抓取由关键字搜索的结果
内容:抓取小说网站由关键字搜索的结果,并采集结果中小说的书名和链接
思路:首先在小说网站里面搜索关键字:斗罗,然后利用爬虫抓取搜索返回的结果中小说的书名和链接,这过程中通过pyquery去解析网页源码,最后提取出数据。
链接:http://book.chenlove.cn/search.html?keyword=斗罗
在浏览器中访问链接:
在编写之前先分析一下网页源码:
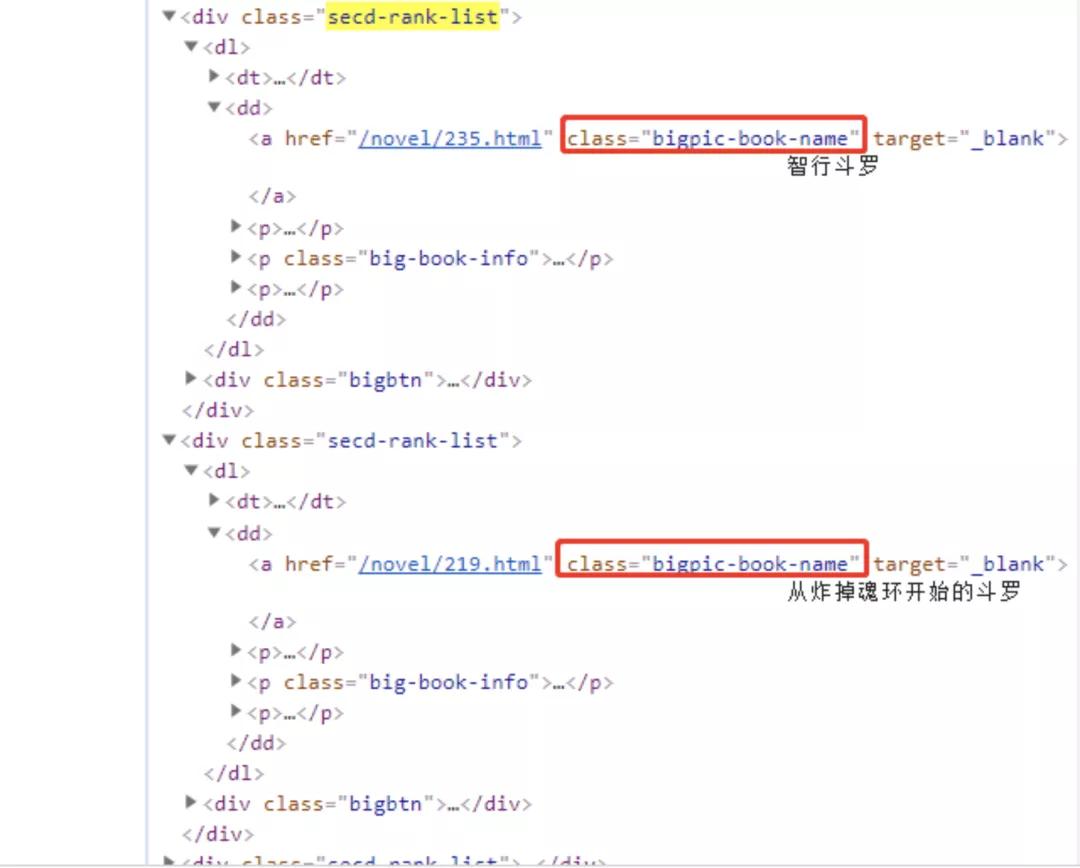
查看源代码,可以知道每一本书的数据都在class为bigpic-book-name的a标签中,首先使用pyquery去解析其a标签,然后进行循环遍历。
完整代码如下:
- from pyquery import PyQuery as pq
- import requests
- # 设置代理服务器
- headers = {
- 'User_Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'
- }
- #请求连接
- url = "http://book.chenlove.cn/search.html?keyword=斗罗"
- response = requests.get(url, headers=headers)
- if response.status_code == 200:
- # 转化为utf-8格式,不加这条语句,输出爬取的信息为乱码
- response.encoding = 'utf8'
- # 把网页解析为pyquery对象
- py = pq(response.text)
- a_list = py('.bigpic-book-name').items()
- for i in a_list:
- # 获取书名
- print(i.text())
- # 获取书名链接
- print(i.attr('href'))
上一小节我们学会了如何去提取a标签中的内容和链接,同样的这里一样使用text()和attr()去解析内容和链接。
结果:
- 智行斗罗
- /novel/235.html
- 从炸掉魂环开始的斗罗
- /novel/219.html
- 旅途从斗罗开始
- /novel/195.html
- 斗罗之卡BUG
- /novel/159.html
- 终极斗罗
- /novel/54.html
本文转载自微信公众号「Python研究者」,可以通过以下二维码关注。转载本文请联系Python研究者公众号。













