













2021年10月8日-10日,第十七届全国机器翻译大会 (CCMT 2021) 在西宁举行,字节跳动火山翻译团队技术和产品研发负责人王明轩以《预训练时代的机器翻译》为题,阐述预训练技术在机器翻译的应用。
工欲善其事,必先利其器。火山翻译能够持续提供快速、稳定、安全的翻译服务,离不开团队对机器翻译前沿技术的深刻探索。近年来,预训练技术在多个领域都取得了不小的成就,随着深度学习的快速发展,面向自然语言处理领域的预训练技术 (Pre-training) 也获得了长足的进步,火山翻译团队对于预训练技术在机器翻译的应用也收获了一些成果。
以下是王明轩演讲全文:
这次我主要想介绍一下预训练技术在机器翻译的应用。今天早上各位老师提供了非常好的座谈会,对这方面已经做了一些介绍;此外,刚才王瑞老师提及的监督机器翻译和预训练也有比较密切的联系。那么我主要带大家整体了解一下预训练技术在机器翻译里面有什么样的应用,因为时间关系,主要会聚焦在文本翻译方面的预训练。

其实谈到 NLP(Natural Language Processing, 自然语言处理),这两三年以来最大的一个变化就是预训练。从 BERT(Bidirectional Encoder Representations from Transformers, 由 Google AI 研究院提出的一种预训练模型)到 GPT(Generative Pre-trained Transformer, 由 Open AI 提出的预训练语言模型)。从 NLP 到 CV (Computer Vision,计算机视觉) 再到 speech,他们在整个行业引起了一些翻天覆地的变化,可以说是过去十年来最大的进展。
预训练框架其实是一个非常简单但非常有效的思路,简单来说,它本质上也是一种监督学习,即通过大量的、没有标签的数据,来训练一个预训练模型,然后在下游任务上做 fine-tuning。其实这是一个非常简单的思路。它的一个优点是泛化性非常强:一个预训练模型,可以在不同的下游任务上进行适应。今天我们这场讲座其实并不是针对预训练,更多是探讨预训练和机器翻译结合会不会产生某种化学反应。
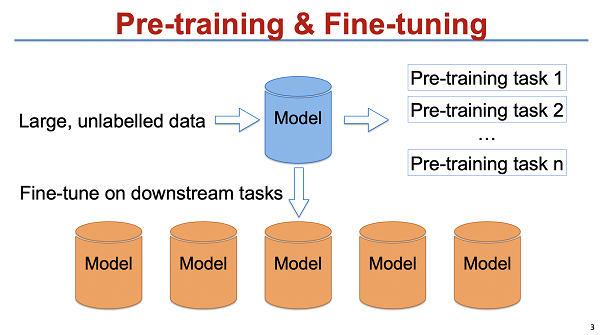
今天我的讲话内容主要包含两个部分,第一个部分是介绍单语的预训练模型,以及为什么预训练可能会对机器翻译有作用。
机器翻译的多语言预训练(Monolingual Pre-training for NMT)
这个是我画的一个实体图,主要用来介绍现今机器翻译双语、单语数据的大小。这个是现今的中英双语数据,包括在商业系统里面,大概一亿数据。可以看到单语数据是远远大于双语数据的。因此,这么多数据怎么更好地被利用起来其实是一个非常值得关注的点 。
此外,我们将BERT出现之前与之后的数据量进行对比。预训练其实是一个很古老的主题:在BERT之前,其实也有很多预训练的研究,早在2012年大家就已经开始了这类工作。过去到现在发生了什么变化呢?如图所示,过去的单语数据的量级比较小,而在 BERT 出现后数据量开始百倍增加,我认为质变可能是来自于数据这块的增加。因此,我们今天的一个主题就是:机器翻译能不能也利用上这么大规模的单语数据,或者通过预训练的技术把这部分的信息融合到翻译里面。第一部分会分为两节,第一节主要是把最近的几个工作简单介绍一下,分为两种类型,一种可以简单归类为 BERT fusion model,也就是研究它如何和已有的预训练模型做结合。我们知道机器翻译是一个端到端的模型,但是之前大家比较了解的一些模型像 BERT , GPT,这些都是一个理解模型,是一个language model。他们的模型和机器翻译的模型不一样,那么如何把这种异构的网络信息能够更好地结合起来,可能是一部分探索的方向。同时还有一部分探索方向,就是怎么做一个端到端的预训练,然后把它应用到机器翻译里面。这是目前从单语的角度来看两个大的应用方向。
BERT 在机器翻译里面发挥了什么作用?
关于第一个方向:BERT 在机器翻译里面会起什么样的一个作用?这块我们大概会介绍三个工作,基本上都是2020年以后的研究,那么第一个是微软早期的一个工作。他们提出,直接把 BERT 运用到 NMT(Neural Machine Translation,神经网络机器翻译)里面 ,发现直接用它去做 initialize,并没有那么有效,因为一般来说 BERT pre-training fine-tuning 的模型需要更新parameter 。团队甚至发现 BERT-Frozen 可以把整个参数固定下来,可能取得的效果会更好,所以这个工作主要探讨的是 BERT 怎么样和 NMT 模型更好地结合起来 ,他们提出这样一个思路:把BERT的表示作为feature 加进来。另外还提出一个框架,可以简单理解为双encoder。一个encoder是BERT, 一个 encoder 是机器翻译本身的 encoder,接着让 decoder 同时去做 attention ,这样的话等于 BERT 这部分信息就会被加进去。这个是ICLR2020的工作,比较简洁有效。最后证明了 BERT-fused 在 rich resource 还有 low resource 的场景都取得了比较好的结果,另外也发现这种预训练对于无监督的提升是非常大的。尤其当数据量比较少,或者是没有平行数据的时候,加了预训练可能会带来质变的提升,而且会让整个模型都更容易训练。

这是另外一篇工作,由阿里和南京大学合作完成,他和上一个工作本质上是比较接近的,但其中一个很大的不同点在于他做了一些 dynamic layers fusion,考虑到了把不同的 layer,即把 BERT 和 NMT 的 encoder 结合。另外一个不同点是:他们也在 decoder 做了一些尝试, 就是包括把 decoder 用 GPT 去做预训练。最后发现了一个简单的结论:encoder 用 BERT,decoder 用 GPT,这样的提升是最显著的。在 transformer base 的情况下,差不多有接近两个点的、比较显著的提升。
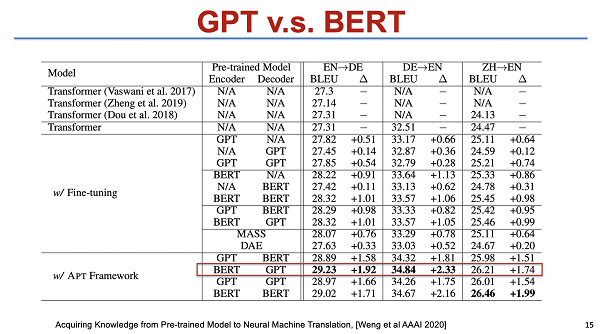
第三个是我们的工作。我简单介绍一下,我们的工作和前两个不一样的地方,是我们更关注于怎么在不改变模型的架构的情况下,也就是仍然用 BERT 做 initialize 进行 fine-tuning。最简单的一个思路就是我们不把 BERT tuning 得太多。在 tuning 的过程中就引入了 continue learning 的一些方法,就让 BERT 的 knowledge 和 NMT 的 knowledge 都能够同时保存,为此我们采用了一些具体的方法,结果也得到了比较大的提升。该模型已经开源,大家有兴趣的话可以在网上查询到相关细节。
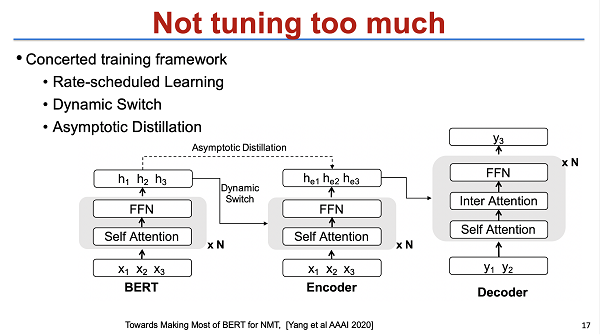
这些思路,其实还有一个问题,我们可以看到前面几个工作,主要是集中在BERT pre-train,就是对 decoder,包括 GPT 的应用其实是相对比较弱的。但从事机器翻译的同学其实都明白,target of language model 是非常重要的,或者说 target 的数据其实甚至是比 source 都要重要。那怎么能够把类似于 language model 或者 GPT model 等用到 NMT 模型里面是我们非常需要关注的一个点。这块的一个挑战在于,decoder 的分布是不一样的。如果直接用 GPT 预训练一个机器翻译模型的话,会发现中间的 cross attention 没有办法预训练,那么每一层的输出就不一样了。
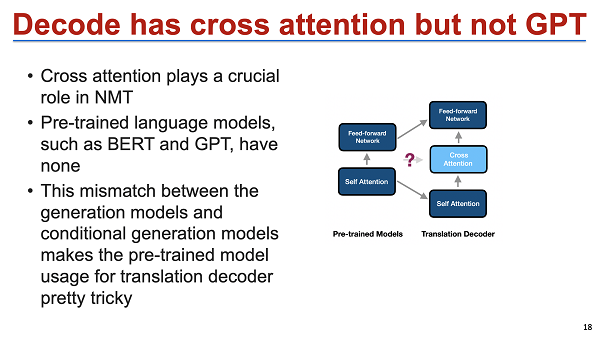
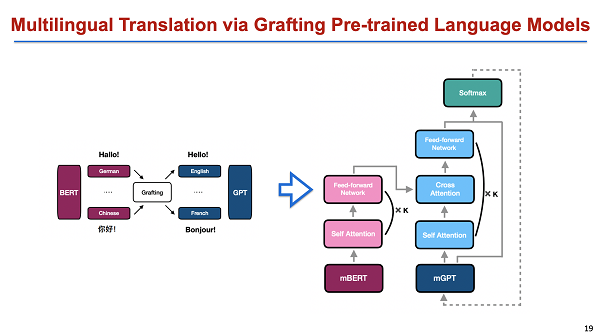
这种初始化其实效果不是特别好,所以我们今年在 EMNLP 会议上发表了一个比较简单的工作,就是 encoder 用 BERT, decoder 用 GPT,用 grafting 作为嫁接模型。中间再用类似的 adaptor 把它连接起来。因为 encoder 是一个多语言 BERT,decoder 是一个多语言 GPT,我们可以不考虑初始化,直接把多语言 GPT 的 attention 去掉,然后在上面再结合 cause attention。这样的好处是整个模型能够完全地保留 encoder 和 decoder 的信息,然后用少量的数据就能得到一个非常好的结果。上面讲述的主要是一种 fusion style,我们怎么把这种表示、生成,结合到机器翻译里面?
如何设计一种端到端预训练模型应用于机器翻译
当然,这块还有另外一种类型的工作,类似 MASS (Masked Sequence to Sequence Pre-training for Language Generation) 或者 BERT。他们其实是采取了一个不一样的思路:他们保证了模型结构的一致性来预训练一个端到端模型。这样的一个好处在于,我们接下来做模型 fine-tuning 的话结构是一致的,整个模型、参数等会比较简单,不需要去考虑模型结构不一致的问题,结果也比较简单。
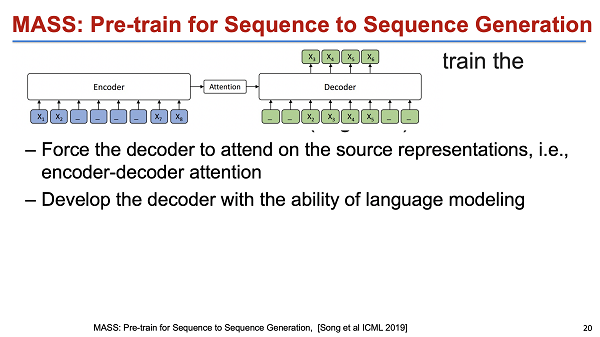
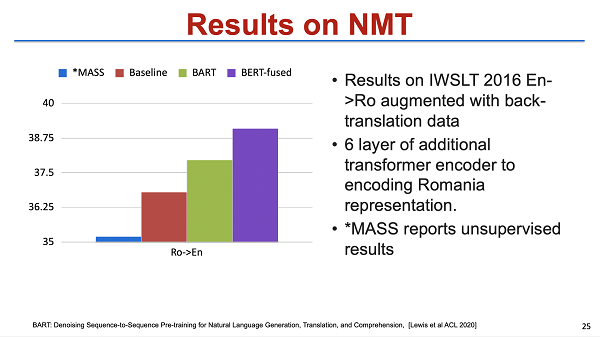
为了验证效果,我们在无监督的机器翻译上做了验证,其实效果是非常好的,基本上提升是七到八个点,但是在 rich resource 上的提升是比较有限的。此外,这个工作可能还有一个 cross-lingual 的问题。因为我们知道,机器翻译至少涉及两个语言,比如说中英翻译。那么我们如果用英语去预训练一个英语的 MASS,其实中文部分是没有办法很好地被预训练的。也就是其实整个模型虽然结构上一致了,但本质上也只有大概一半以上的参数被初始化,有一部分参数还是没有做好的,此外它的上下游的目标也不一致。端到端的预训练更多是一个 autoencoder 对自编码,而没有考虑 language transfer,所以也不一定是最好的结构。类似的一个工作还有 BART,它其实和 MASS 本质上比较接近。最大的区别是 MASS 包含一些更复杂的过程。它不只是做 mask,还关注了包括输入文本做 random shuffle 等细节。最后这个工作在 low resource 上,包括在 unsupervised results 上做了一些验证,效果也比较好。
简单地做一个总结,第一部分讲了两块,一块是 fused style,就是把多个模块结合起来,比如把 BERT 把 GPT 放到 NMT 里面,怎么做能更好地结合;一种是做预训练的端到端模型。主要是这两块的工作,刚才也提到,这两块都有它的一些局限性。
Fused model 的这种局限性主要是指整个模型比较复杂,往往需要改变网络结构,训练也没有那么稳定。对于端到端模型,其实它使用起来非常方便,但缺点在于上下游任务不一致,所以就不一定把这个语言的信息用到了最大。此外,这是个单语模型,没有办法扩展到双语的场景。就好比用英语去训练一个预训练模型,放到中英机器翻译里面,中文部分的信息是没有被充分考虑到的。所以接下来我们就会讨论这两年的一些在多语言预训练的一些探索。
机器翻译的多语言预训练(Multilingual Pre-training for NMT)
因为机器翻译本身就是一个多语言的问题,多语言机器翻译预训练也是一件非常自然的事情。这块的话,我们还是分两个部分去讲,一部分是关于 fused 的预训练,一部分是多语言的端到端预训练,这一块也会有一些不同的思路。

比如多语言模型,虽然模型一样,但大家研究的侧重点更多的是集中在 knowledge transfer,就是指不同的语言其实分享了同样的 knowledge。比如说中文和英文,因为大家都生活在地球上,我们可能用不同的语言去描述同一个世界,所以这些知识理论上是可以转换的。当然,人其实也有一个直觉,我们会发现很多语言学家在学过两种语言之后,学第三种语言会越来越快,甚至一些非常有天赋的人可以学八种语言。他们学语言的时候其实是会不断的去学习语言中的共性然后适应。所以我们在考虑语言之间是不是能够也寻找到这种共性然后学习。

这个是NeuIPS比较早期的工作:Cross-lingual Language Model Pretraining。它的思路是:是否能够把相同语义的句子表示到同一个空间里面。因为单独的模型中不同语义的句子其实是表示在不同空间里面的。这是一个例子:通过不断地去拉齐语义的表示达到目标。然后刚才王瑞老师也提及了,我就不再多讲,就是一个多语言预训练模型,这个模型其实比较简单。它沿用BERT的思路,把前半句翻译成英文后半句翻译成法语, 一起去训练一个 mask predict model。因为同种语义的英语和法语被放在了一个 context 里面,模型希望通过 context 能够比较隐式地去学习这种语言的贡献信息,最后把相似的东西表示在一块。
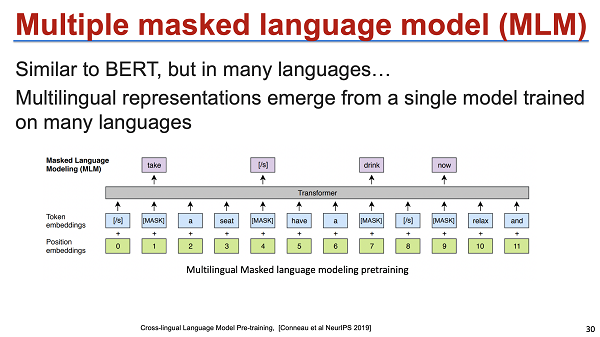
最后这项工作做了较多实验,主要集中在 low resource 和无监督,具体的实验结果这里就不再详细介绍,但其中有两个 ablation study 的结论是非常有趣的。一个是增加更多的语言,对 low resource 的提升非常显著。在我们要翻译一些很冷门的语言对时,比如说从英语到印地语,增加更多的语言对其实是对low resource有较大的提升帮助的。但是增加更多的语言对有可能会降低 rich resource 的结果。为什么会降低 rich resource 的结果?我觉得本质可能还是因为 model capacity 不够,也就是说这个模型空间是有限的,rich resource 本身资源已经比较充分了。所以这一块的话就需要引入更大的模型。 说明多语言之间是能够很好的去学习 share knowledge 的。

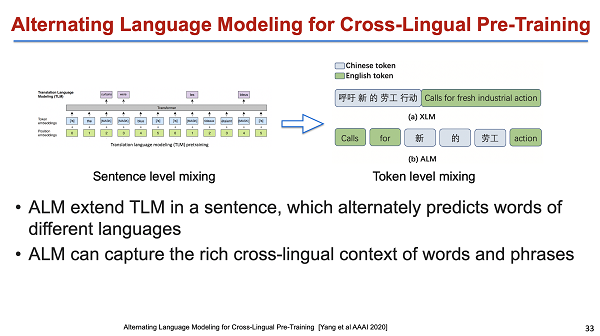
接下来的这个工作是微软的另外一个研究,这个工作比较上一个,有一些不一样的地方。不一样的地方是上一个工作是在句子的维度做了mix,上半句放中文,下半句放法语,然后把它放在一起。希望他们的context 能够对齐,是潜在的。而微软的这个工作是在做一个 language model:我们希望模型对于英文的下半句的预测不一定是英文,因而我们会去做一些替换 ,像“calls for 新的劳工”。其实就是把中文和英文混在一起,让英文去预测中文。该模型中,词本身就是它的 contaxt,它的表示来自于contaxt,那么“新的劳工”和 "calls for action" 这种关系就会被建立起来。甚至于“新的劳工”可能和其对应的英文表达 "fresh industrial action" 也能够对齐。它其实是一个 Alternating language model,当然这块的话侧重的是一个 language model。最后对结果可视化,发现从词的级别来看这种模型确实是能够把距离拉近的。
还有一个类似的工作——mBART。mBART 的思路和前两个不太一样,如果用一个词一句话来总结,我觉得就是:“大力出奇迹。”也就是说做的事情是非常简单的,它本质上还是把所有的语言放在一起去做预训练,你可以理解为一个多语言MASS或者多语言 BERT。我们不需要双语数据,只需把英语 、法语、德语几十种数据全部放在一起,然后做一个 auto-encoder,然后再去下游任务做 fine-tuning ,那么他希望隐式的,比如 model 本身不同的语言都有相同的阿拉伯数字,或者有一些东西本身就是隐式的, 能够学习不同语言之间的 share 的表示。最后它的规模非常大,引入了可能有二十几倍的 BERT 的数据量,做了一个很大的多语言 BERT。最后在非常多的任务上,尤其在 low resource 上可能有三到十个点的提升。

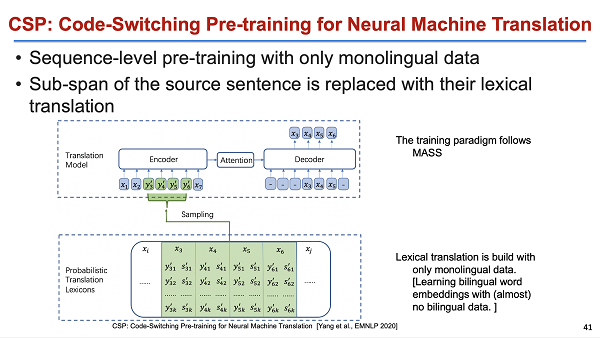
同期类似的工作还有 Code-switching pretraining,当然这个也是完整地沿用了 MASS 的结构。它和 MASS 唯一的区别点在于 MASS 是 mask 来 predict ,模型把 mask 的 token 替换成了其他语言。所以就也是一个 Code-switching 的结构。
同期我们完成了 mRASP 工作,也是同期工作,做的规模要大很多。我们把多种语言混在一起去做预训练。这些语言会有比较丰富的 code-switching,最后可以把所有的语言距离拉近。最后得到的一个结果,即 rich resource 和 low resource 都能被映射到一个空间,那么 low resource 就能更好地借助 rich resource。而且在下游 fine-tuning速度也是非常快的,即能够一定程度上减少 pretraining knowledge loss 的一个问题。以前用 BERT 之类的进行预训练,最后做 fine-tuning 时往往需要花费两三天。那么用端到端预训练的模型可能只需两三个小时就可以完成fine-tuning。那么它的灾难性遗忘问题其实也会潜在地被缓解。
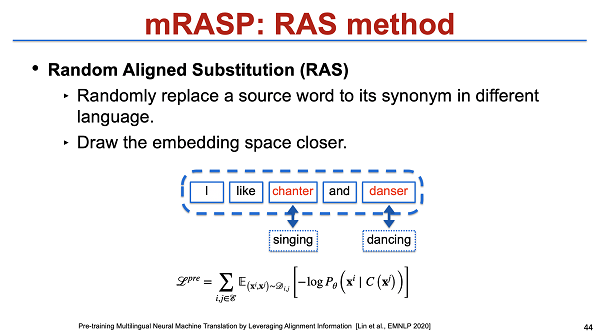
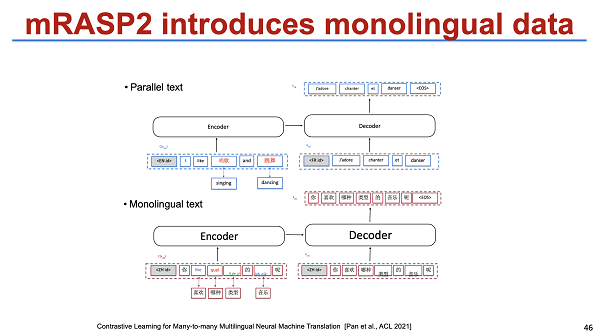
在这个基础上,在今年的 ACL2021 会议,我们也做了一个 unsupervised 的,或者说 contrast learning 来进行预训练。我们的正例可能是 parallel 的,cross-lingual 的句子,反例可能让模型去区分不同语言,不再做数据增强,那么最后也能够得到一个统一的表示。另外,我们的框架跟之前的一个区别点在于,不论是单语还是多语言数据,都能放到一个框架里。这个模型的一个潜在优点在于,即使不做 fine-tuning,效果也挺好的。当然,做了 fine-tuning 则会有进一步提升,细节就不展开描述了。
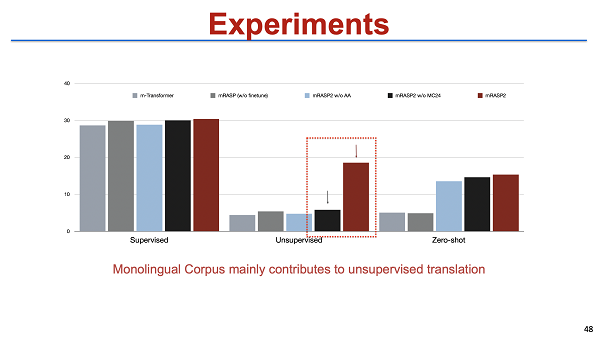
从整体来看,在 rich resource, low resource,甚至 zero-shot 的情况下表现都不错。关于 zero-shot 在这里稍微多提一句,我们发现一个很有趣的点:把所有的语言进行对齐之后,模型就潜在具备了这种 zero-shot 的能力。也就是说,我们训练数据里没有法语到德语的平行数据,但我们当我们把德语和英语、法语和英语映射到一起后,这个 model 直接得出的法语和德语的翻译效果居然还不错,基本上能够接近于 pure。这种方式得到的 bleu 差距在一个点以内,我觉得几乎已经达到可用的状态。
最后我们简单地做一个总结, 其实今天围绕文本翻译主要讲了两块,第一部分是如何在多语言的场景下,怎么尽可能用更多的单语数据来帮助机器翻译。这里有两种方式,一种是把已经训练好的或者最强的,类似于 BERT, GPT 这类单独训练的 model 尝试用到机器翻译里。另一种场景:尝试针对机器翻译,端到端设计一种预训练模型,然后和机器翻译比较好地结合起来。
第二部分主要是介绍,多语言预训练最重要的一个点在于:它更多的不是依靠增加单语数据,而是学习一种 universal的 knowledge,即实现不同语言的表示,只要语义是接近的,他们就能有相似的表示。其实,不管对 low resource 还是 rich resource 其实都会有非常大的帮助。
因为时间关系,今天的介绍就主要到这里,谢谢大家。

















