自制一个能给葡萄缝针的机械臂?
近日,知名「硬核」up主稚晖君展示了一款自己从零到一设计的小型高精度六轴机械臂Dummy。
视频一出,直接冲到B站排行榜前十,打开弹幕,满屏都是惊叹号。
在「瑟瑟发抖」、「保存=会做」、「他竟然在试图教会我们」、「我看不懂,但大受震撼」的弹幕之中,有网友说「希望我们也能尽早做出中国版的『达芬奇』机器人」。
不止华为,其实各大科技公司都在发力机器人的技术研究。就在最近举办的国际智能机器人与系统大会IROS 2021上,我们就看到了很多熟悉的身影,其中不乏堪比穿针引线的灵活操作技术。
而这其中,有一个你肯定意想不到的名字!
没条胳膊也算机器人?
虽然现在服务型机器人遍地开花,不过大多只能问个「您好,请问有什么能帮您」,然后回答一个「暂不支持该功能」,连送个外卖都得人追着外卖跑。

为什么这些机器人难以派上用场?
嗯。。。可能得先需要一个可以灵活抓取的机械臂。

此处先放一个彩蛋
抓取是机械臂的基本功,要想成功完成抓取任务,需要闯过三个关卡:抓取物体时定位要精准,抓取姿态要合适,对物体间遮挡可能造成的碰撞要先知先觉,闯过了这三关,机器人才算是入了门。
这篇字节跳动AI Lab和中科院自动化所合作发表在IROS 2021的论文就提出了一个全新的机器人抓取操作方法。

https://arxiv.org/pdf/2108.02425.pdf
作者通过结合3D物体分割、碰撞预测和物体姿态估计,让机器人能在杂乱场景中准确地估计出物体级别、无碰撞的六自由度抓取姿态,并且达到了SOTA。
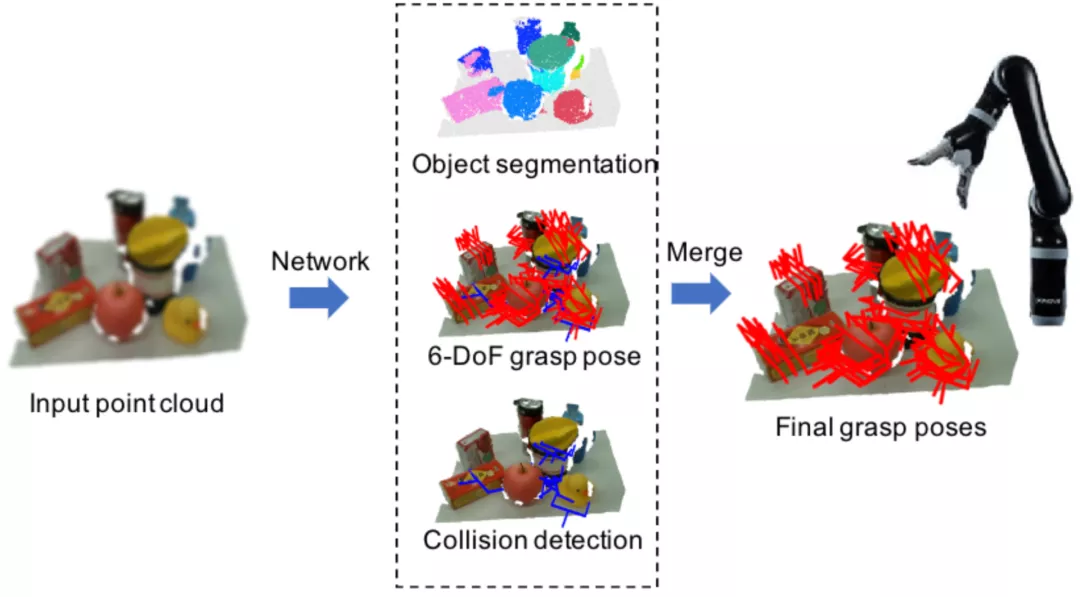
联合实例分割及碰撞检测的机器人抓取姿态估计示意图
首先采用PointNet++作为编码器从点云中捕捉3D特征信息,后接三个并行解码器:实例分割解码器,六自由度抓取姿态解码器和碰撞检测解码器。
这三个解码器分支分别输出逐点的实例分割、抓取配置和碰撞预测。在推理阶段,作用于同一个实例,且不会发生碰撞的抓取姿势会被归为一组,通过位姿非极大值抑制算法融合形成最后的抓取姿势。
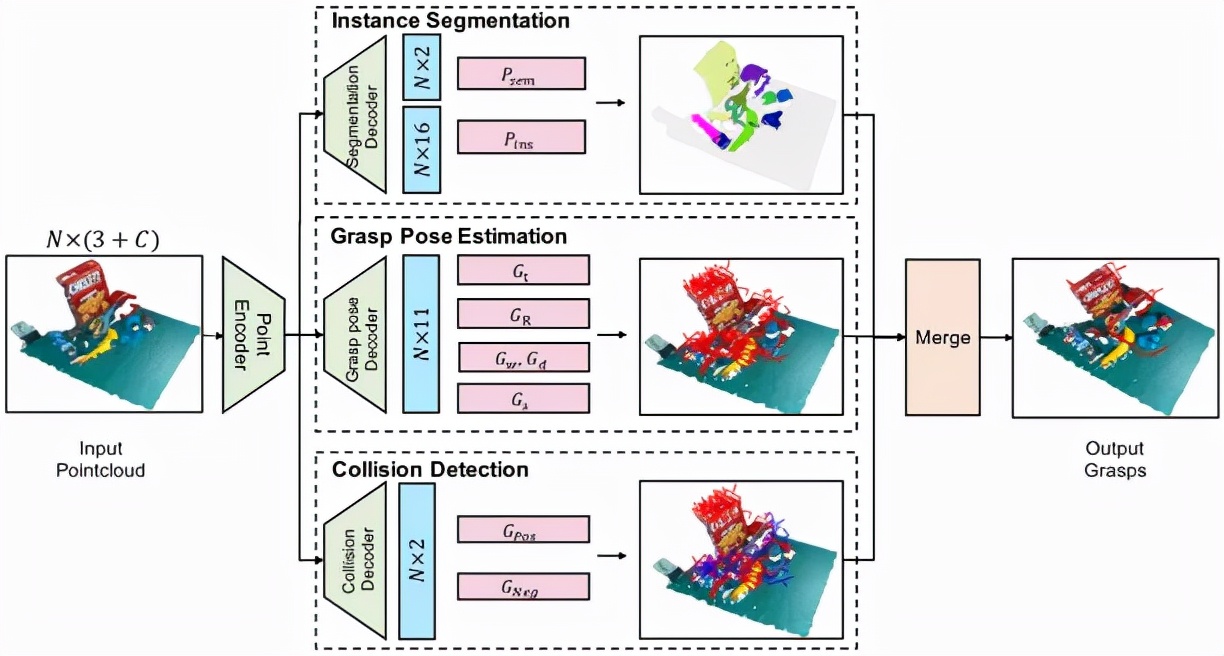
联合实例分割及碰撞检测的机器人抓取姿态估计算法框图
实例分割分支
想抓取一个物体,得先能看清它,看得清楚,才能抓得准确。实例分割分支采用一个逐点实例语义分割模块来区分多个对象。具体来说,属于同一实例的点应该具有相似的特征,而不同实例的特征应该不同。
在训练过程中,每个点的语义和实例标签都是已知的,用二分类交叉熵来计算该分支输出的语义损失
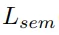
,可以对背景和前景进行分类。
而实例损失
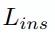
通过一个判别损失函数
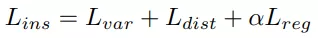
来计算:方差损失
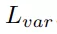
可以让属于同一个实例的点尽量向实例中心点靠近,而距离损失
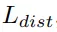
是为了增加不同实例中心之间的距离,正则化损失
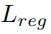
约束所有实例朝向原点,以保持激活有界。
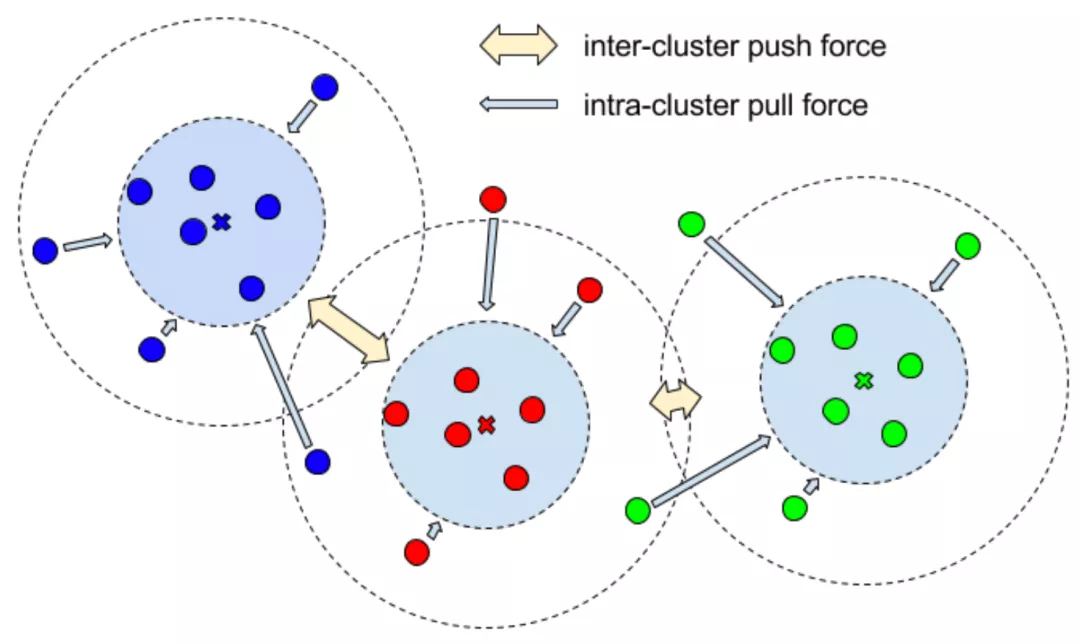
用于实例分割的判别损失函数图解
整体实例分割的总损失
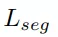
为语义损失和实例损失之和。
这样,实例分割分支就可以为算法学习实例级的抓握提供实例信息,因而模型可以自主完成抓取,更可以由你指定抓取目标,听你差遣,指哪抓哪。
六自由度抓取姿态估计分支
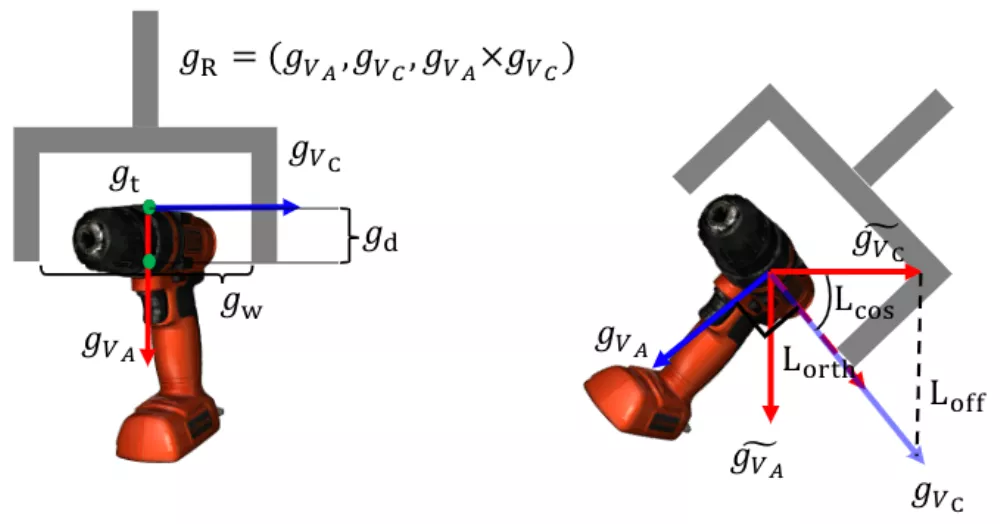
六自由度抓取姿态估计分支在得到了实例的点云后,会为点云中的每个点生成SE(3)抓取配置参数,SE(3)抓取配置g由抓取中心点gt、旋转矩阵gR、抓取宽度gw、抓取深度gd和抓取质量评估分数gs构成且每个点仅对应一个最优的抓取配置参数组合。
在训练时,将场景点云中可抓取点的预测视为一个二分类任务,使用交叉熵损失函数监督排除不可抓点,仅保留可抓点。每个可抓点的损失包含了旋转损失
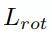
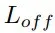
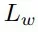
、抓持深度损失
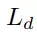
和抓持质量得分损失
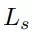
,以此进行监督训练。
可是,从非线性和不连续的旋转表示(如四元数或旋转矩阵)中直接学习六自由度抓取姿态是非常困难的,为了解决这个问题,gR用两个正交的单位向量将传统旋转矩阵分解为手爪的接近物体的方向
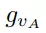
和手爪闭合的方向
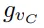
。
为了优化,将旋转损失
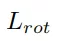
分为三个部分:偏移损失
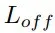
、余弦损失
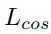
和关联损失
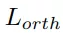
,分别用于约束位置、角度预测和正交性。抓持宽度损失
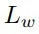
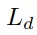
和抓持质量得分损失
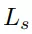
用均方误差(MSE)损失进行优化。
六自由度抓取姿态估计分支无需事先假定物体的几何信息,能够直接从3D点云的特征中进行抓取姿态的预测,并对损失函数做了更精巧的设计,对于复杂场景中各种形状和大小的物体都能「探囊取物」。
碰撞检测分支
虽然前两个分支能够实现实例级六自由度抓取姿态预测,但仍然需要一个碰撞检测分支来推断每个抓取的潜在碰撞以保证生成的抓取姿态在场景中是有效的和可执行的。
碰撞检测分支采用了一个可学习的碰撞检测网络来直接预测所生成的抓取姿态可能产生的碰撞。
在训练过程中,将对无碰撞和有碰撞视为二分类问题并进行采样,真实的碰撞结果标签由已有的碰撞检测算法根据六自由度抓取姿态估计分支的抓取配置生成,碰撞损失函数
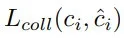
使用二分类交叉熵损失进行监督。
并行的碰撞检测分支使得该方法的六自由度抓取姿态估计分支不依赖碰撞检测作为后处理模块来过滤无效的抓取姿态,大幅降低「思考」延迟,机械臂的抓取动作看上去就是两个字,丝滑!

在公开数据集Graspnet-1Billion上的小试牛刀,一不小心就拿了个SOTA:
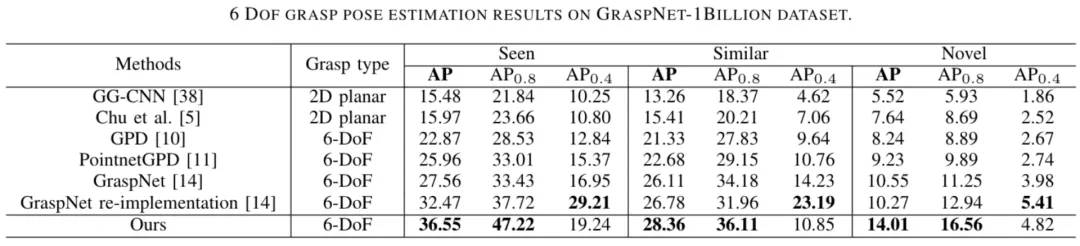
GraspNet-1Billion数据集实验结果
刷刷榜不过瘾,使用Kinova Jaco2机器人和商用RGB-D相机Realsense实战演练,再拿SOTA,成功率和完成率较之前表现最好的GraspNet都有不小的提升:
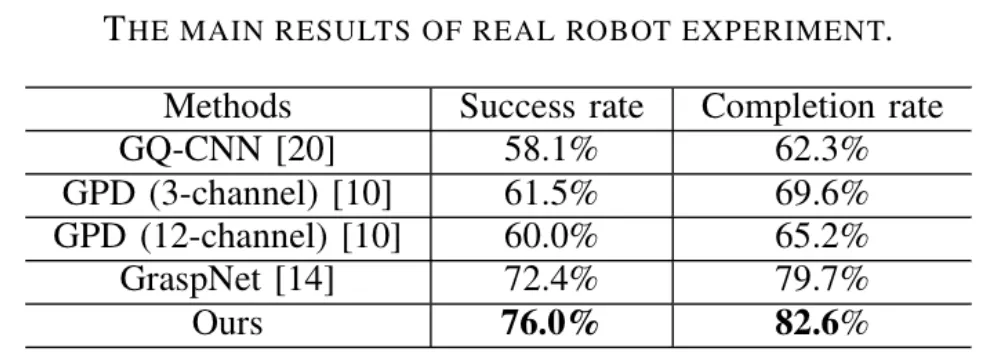
真实机器人平台实验结果
入门先学抓,要想拜师学艺,还得练练放。
合理地抓和放,可以完成更复杂的任务,比如自主装配,搭建等任务。
同样是IROS 2021收录的一篇字节跳动和清华大学合作的论文,让机器人可以在没有人类指导的图纸的情况下,也能进行结构设计与建造。
而以往机器人在装配、布置、堆积木时,得先告诉它任务的最终目标状态,相当于按「图」施工,没「图」可干不了。

https://arxiv.org/pdf/2108.02439.pdf
搭个桥嘛,这有啥难的?
如果不依赖人类设计出的蓝图,机器人要面对的是一个任意宽的悬崖,一堆杂乱摆放的积木块。
搭个什么样的桥啊?自己考虑。用几块积木啊?越少越好。这桥不会塌吧?那谁知道呢。
一问三不知,这可比给了精确目标状态的标准装配任务难多了,因为机器人既要考虑积木的操作顺序,还必须找出即物理上稳定的桥的架构,规划的搜索空间之大,让人头皮发麻。

工程师们脑洞大开,提出了一个双层框架来解决桥梁的设计和施工任务,在概念上,类似于任务与动作规划(Task and Motion Planning,TAMP) :机器人先学习一个高层蓝图策略来一次又一次生成将一个构建块移动到所需位置的组装指令,再实施一个低层操纵策略来执行高层指令。
这其中的创新之处在于:高级蓝图策略是以物理感知的方式,使用深度强化学习在一个魔改的物理模拟器中学习神经蓝图策略。
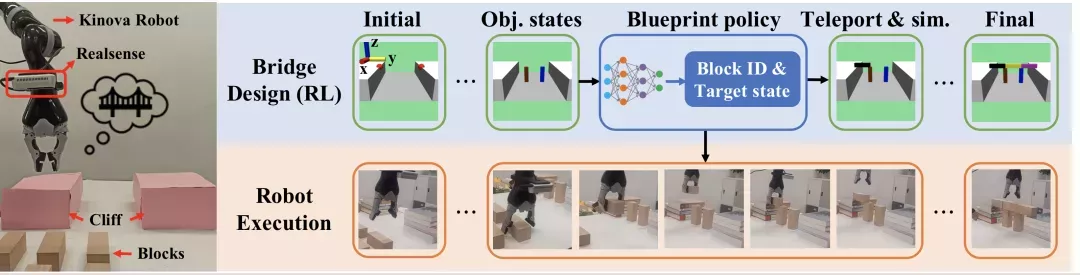
高层蓝图策略
高层蓝图策略要学习的,就是按顺序生成取放指令,用最少的积木搭建一座连接两个悬崖的平桥,还不能倒。
每次,agent都可以观察一下当前场景,然后指示拿一个积木去搭桥。让物理引擎飞一会儿,agent就可以接收来自环境的反馈(桥垮没垮),继续观察连续的场景并给出下一个指令。
咦?这个不就是传说中的马尔可夫决策过程(MDP)问题吗?不用怀疑,你又学会了。
用元组{S,A,Γ,R,T}定义这个问题,S表示状态空间,A表示动作空间,Γ是转移函数,R代表奖励函数,T是一回合的视野。
状态空间编码所有N个构建块和2个悬崖的状态:
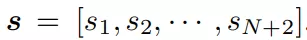
,
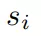
是包含三维位置、欧拉角、笛卡尔速度、角速度、表示物体是否为积木的一维物体类型指示器和一维时间组成的向量。
动作空间简单一点,只生成拾取放置指令,将构建块放在横跨两个悬崖中间的yz二维平面上,编码了一维目标对象标识、一维目标y位置、一维目标z位置和围绕x轴的一维旋转角度。
转移函数的构建非常复杂,想是想不出来的,咋办呢?
记得刚刚说过的物理模拟器吗?模拟器在接受蓝图策略的指令后直接将选中的积木块传送到指令位置,继续物理模拟,直到环境达到稳定状态后,将结果状态返回给蓝图agent。
因此,即使不依赖符号规则或任何已知的动力学模型,agent仍然可以获知某个指令在很长一段时间内会造成的的物理结果,并学会寻求物理稳定的解决方案。
没有明教,却有暗示,只能说是「妙啊」!
奖励函数是「施工奖励」、「平整度奖励」和「节省材料奖励」的组合,说白了就是,用料要少,桥面要平,还不能倒。
为了解决上述的马尔可夫决策过程问题,工程师们再次祭出三把「利器」:Transformer, 阶段性策略梯度算法(Phasic Policy Gradient,PPG)和自适应课程学习。
具体来说,提取积木块和悬崖的特征时,基于Transformer的特征提取器
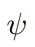
将对象和相互间关系的归纳偏差整合,传送给策略网络和价值网络,并使用PPG算法来有效地训练策略。
说到阶段性策略梯度算法(Phasic Policy Gradient,PPG),不同于近端策略优化算法(Proximal Policy Optimization,PPO),在训练时,它会阶段性地将价值信息提取到策略中,以便更好地进行表征学习,相当于使用一个模仿学习目标来稳定策略网络的训练。
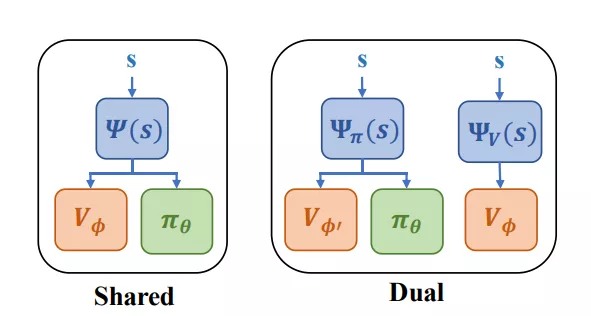
PPG有两种架构变体,Dual和Shared。Shared架构中,策略和价值网络共享同一个特征提取器
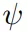
,后接策略头
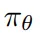
和价值头
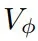
根据大量实践,发现Shared表现更好。
算法再强,一上来就设计长桥,也太难为人了。
自适应课程学习提供了一种循序渐进的升级打怪思路,根据agent的训练进度调整谷宽。当机器人在狭窄的谷间搭桥的成功率渐渐提升时,模拟器才会渐渐增加远距离悬崖出现的概率。
低层运动执行策略
指挥的有了,执行就不难了。
产生装配指令的蓝图策略训练好后,低层运动执行策略就可以照着这些指令来操纵积木块到目标状态。而蓝图策略在训练期间受到过物理规律的熏陶,所以它能够为低级控制器产生物理上可行的指令。
因此,低级策略每次只需要完成一个简单的取放任务,用经典的运动规划算法就能解决:通过生成块的质心抓取姿态,并使用双向RRT算法规划无碰撞路径。
正是由于在本方法中,指令生成和运动执行是完全解耦的,所以学习到的蓝图策略可以以Zero-Shot的方式直接应用于任何真实的机器人平台。
真实机器人实验
模拟器里学习到的蓝图策略+现成的运动规划方法放在真实的机器人系统身上表现如何呢?

现实世界中桥梁设计和施工的结果
拿三种情况测一测,其中悬崖之间的距离分别设置为10厘米、22厘米和32厘米,机器人可以成功地遵循所学习的蓝图策略给出的指令,使用不同的块数以不同的方式建造桥梁。
「老司机」领进门,修行在个「机器人」
学会了抓和放,机器人终于入了师门。
拜师学艺,学的可不是简单本领,光能摆弄两下胳膊显然是不够的,任务复杂了「脑子」转不过弯也不行。
这个看着很简单,照着「师傅」的操作照猫画虎地模仿几遍就会了。
但是机器人看了却只能直呼:「模仿难,难于上青天」。
比如把衣架挂起来这么一个操作,就需要让机器人去完成4个子任务,其中每一个子任务都是相互依赖的:
- 接近衣架
- 抓取衣架
- 移动衣架到挂杆附近
- 将衣架挂在杆子上
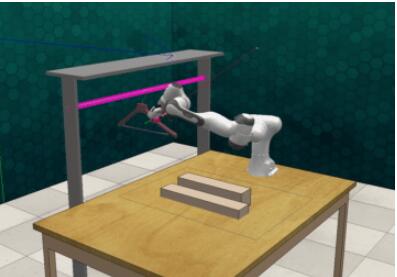
师傅领进门,修行在个人,机器人需要能理解整个任务过程是需要按阶段进行划分的,而且还需要「意识到」在一个阶段没有完成的情况下,是不能进行下一个阶段的。
把任务进行拆解之后,每个子任务的复杂度也得到了简化,同时也可以通过对已有的子任务进行重新组合实现新的更复杂的任务需求。
长序列操作任务
目前,主流的方法是利用分层模仿学习(HIL),包括行为克隆(BC)和逆向强化学习(IRL)。然而不幸的是,BC在专家示例有限的情况下,很容易出现累计误差。IRL则将强化学习和环境探索引入了模仿过程中,通过不断探索环境试错,最终得到对环境变化不敏感的行为策略。
虽然IRL可以避免这类错误,但是考虑到高层和低层策略的时间耦合问题,在option模型上实现绝非易事。
不过,问题不大,字节跳动在收录于ICML 2021的论文中提出了一个新的分层IRL框架「Option-GAIL」。
简单来说,Option-GAIL可以通过分析、利用专家给定的行为示教信息,学习其背后的行为逻辑,使机器人在相似环境和任务下能完整重现与专家一致的行为结果。

https://arxiv.org/pdf/2106.05530.pdf
方法实现
Option-GAIL算法基于对抗生成模仿学习(GAIL),其行为的整体相似度由对抗生成网络来近似得到,并且采用option模型代替MDP进行分层建模。
论文采用了单步(one-step)option 模型,也就是每一步都要决定下一步应该做什么子任务,然后再根据当前所处的子任务和观测到的状态决定采取什么动作。
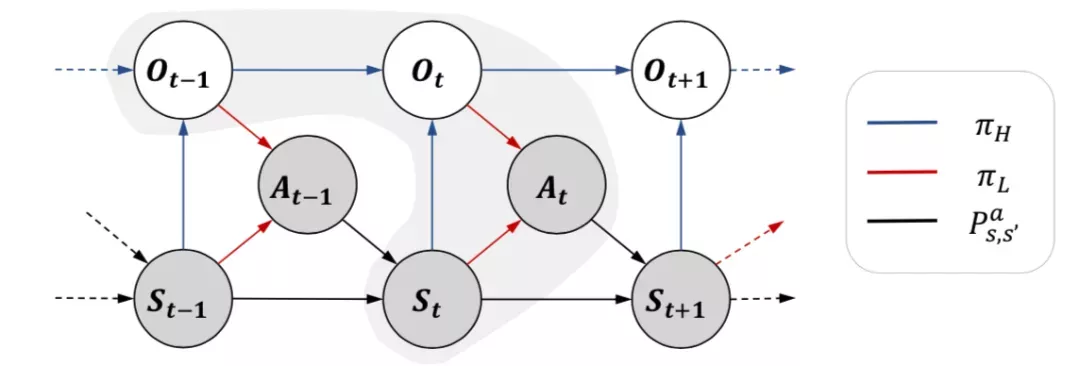
蓝色箭头所指是的决策过程,红色箭头是决策,黑色箭头是环境的状态转移
现在有了能把长周期任务表示成多个子任务分阶段执行的option模型,下一步就要解决如何训练这个模型,使得学到的策略能复刻演示数据。
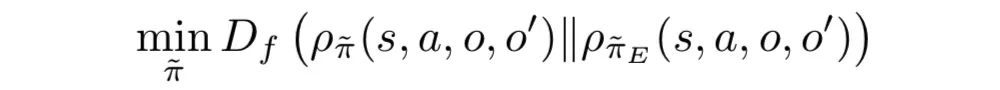
虽然和 GAIL 所解决的占用率度量(occupancy measurement)匹配问题很像,但是模型里多出来的 option 在演示数据里是观测不到的。
因此,论文提出了一种类似EM算法来训练Option-GAIL的参数,从而实现端到端的训练。
E(Expectation)步骤利用Viterbi算法推断出专家数据的option。
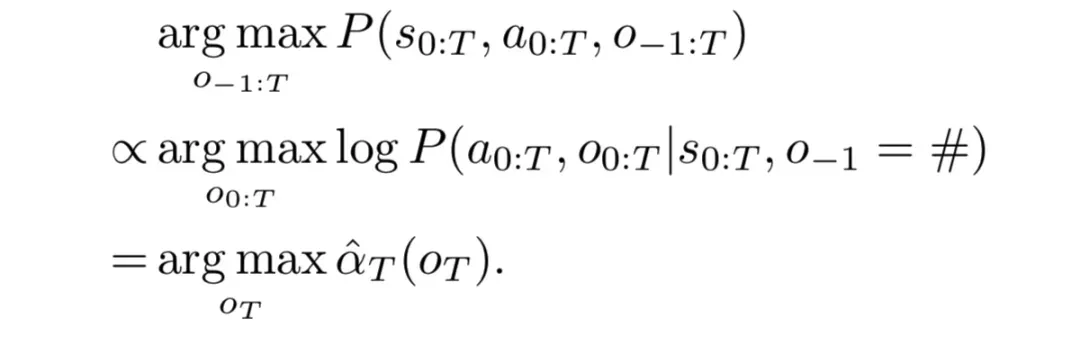
M(Maximization)步骤通过最小-最大博弈来交替优化内层和外层算子,从而得到给定专家option时最优的策略。
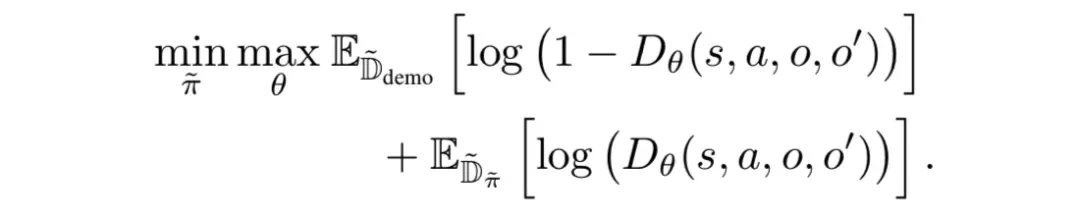
实验结果
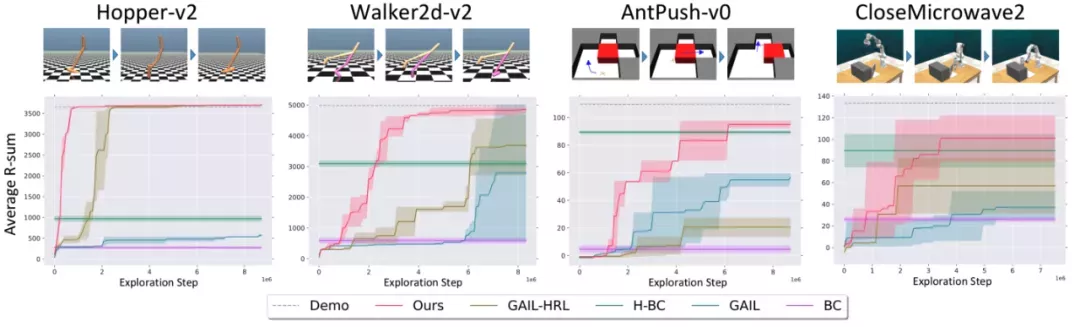
在常用的机器人移动和操作环境上测试我们的算法。测试任务包括:
- 控制单足、双足机器人运动,机器人需要在迈腿、弹跳等不同行为模式之间切换才能稳健行走;
- 控制蚂蚁机器人先推开迷宫里的障碍物才能走到终点;
- 控制机械臂关微波炉门,机械臂要靠近微波炉,抓住炉门把手,最后绕门轴旋转到关闭。
为了验证 Option-GAIL 中引入的层次化结构以及在演示数据以外和环境的交互是否能帮助智能体更好地学习长周期任务,选择如下四种基线方法和Option-GAIL进行对比:
- BC(纯动作克隆):只在演示数据上做监督学习,不和环境交互,也没有任何层次化的结构信息;
- GAIL:有在演示数据之外自己和环境交互,但没有利用长周期任务的结构信息;
- H-BC(层次化动作克隆):建模了层次化结构,但自己不和环境交互;
- GAIL-HRL:在占用率测度匹配的过程中不考虑option。
结果表明,Option-GAIL相比非层次化的方法收敛速度更快,相比不和环境交互的纯模仿学习算法最终的表现更贴近演示数据。
测试环境及各种算法的性能曲线
不如,一起来鼓捣机器人!
当然,除了让机器人学会抓取操作之外,字节跳动还研发了2D/3D环境语义感知、人机交互等系列技术,之前也对外开源了SOLO等系列机器人感知模型和代码,在GitHub上颇受欢迎。
不过,技术研究到产业化落地还有很长的路要走,这就需要长期的投入和探索。希望大厂们继续努力,让机器人早日真正走进我们的生活。