10 月 11 日 - 10 月 17 日,原定于加拿大蒙特利尔举办的计算机视觉领域三大顶会之一——ICCV 2021,正在线上举行。今天,大会全部奖项已经公布。
6 月中旬,ICCV 2021 官方公布了论文评审结果。据统计,大会共接收了 6236 篇有效论文投稿,在首轮 desk reject 之后还有 6152 篇。

7 月下旬,大会放出了接收论文列表,共有 1617 篇被接收,其中包括 210 篇 Oral 和 1412 篇 Poster 论文,接收率约为 25.9%。相较于 2019 年的 25%,ICCV 2021 的接收率略有上升。
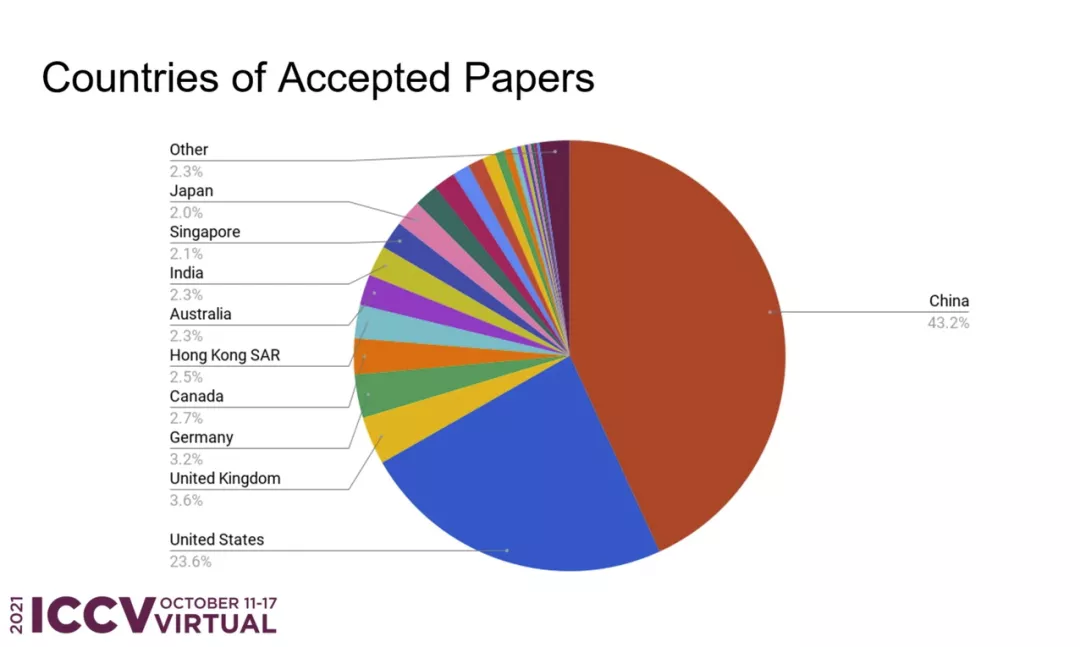
在所有被接收的论文中,来自中国的论文数量占比最高,达到了 43.2%,约为第二位美国(23.6%)的两倍。
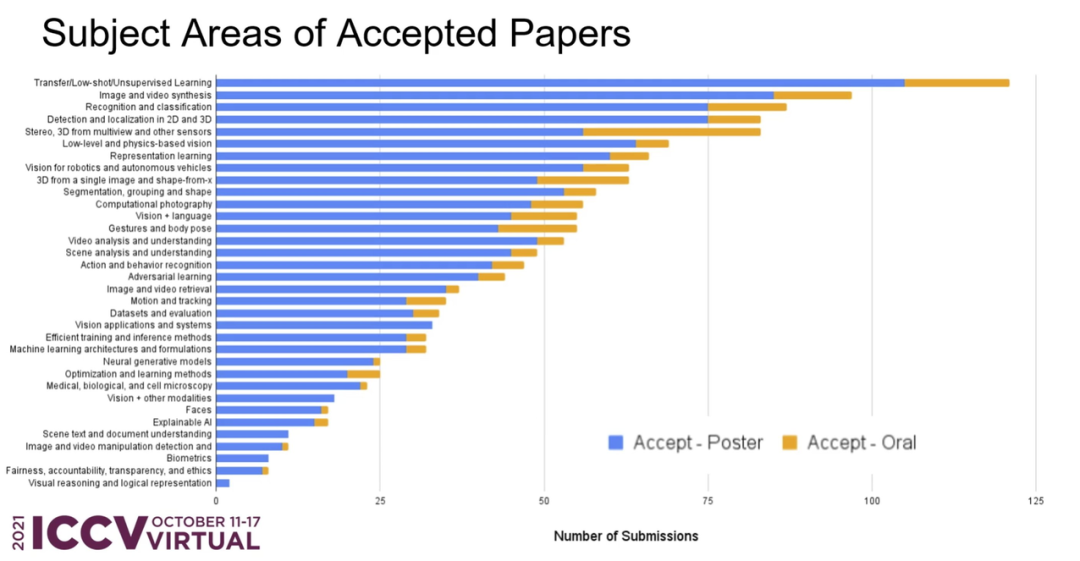
从接收论文的主题领域分布来看,前三位分别是:迁移 / 小样本 / 无监督学习、图像与视频合成、识别与分类。
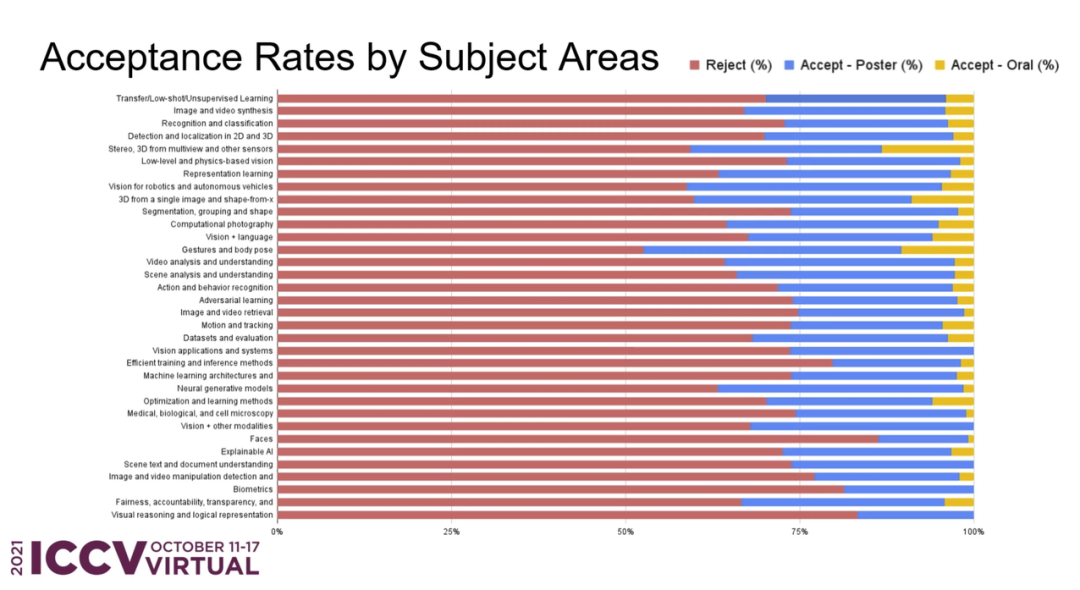
在所有投稿中,各个主题领域的接收率如何?ICCV 官方也进行了详细的统计:
接下来,介绍一下本届大会的获奖信息。
最佳论文 - 马尔奖
来自微软亚洲研究院的研究者获得 ICCV 2021 马尔奖(最佳论文)。论文作者主要包括来自中国科学技术大学的刘泽、西安交通大学的林宇桐、微软的曹越等人。
在 Swin Transformer 论文公开没多久之后,微软官方就在 GitHub 上开源了代码和预训练模型,涵盖图像分类、目标检测以及语义分割任务。目前,该项目已收获 4600 星。
- 获奖论文:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- 作者机构:微软亚洲研究院
- 论文地址:https://arxiv.org/pdf/2103.14030.pdf
- 项目地址:https://github.com/microsoft/Swin-Transformer

本文提出了一种新的 vision Transformer,即 Swin Transformer,它可以作为计算机视觉的通用骨干。相比之前的 ViT 模型,Swin Transformer 做出了以下两点改进:
其一,引入 CNN 中常用的层次化构建方式构建分层 Transformer;
其二,引入局部性(locality)思想,对无重合的窗口区域内进行自注意力计算。
首先来看 Swin Transformer 的整体工作流,下图 3a 为 Swin Transformer 的整体架构,图 3b 为两个连续的 Swin Transformer 块。
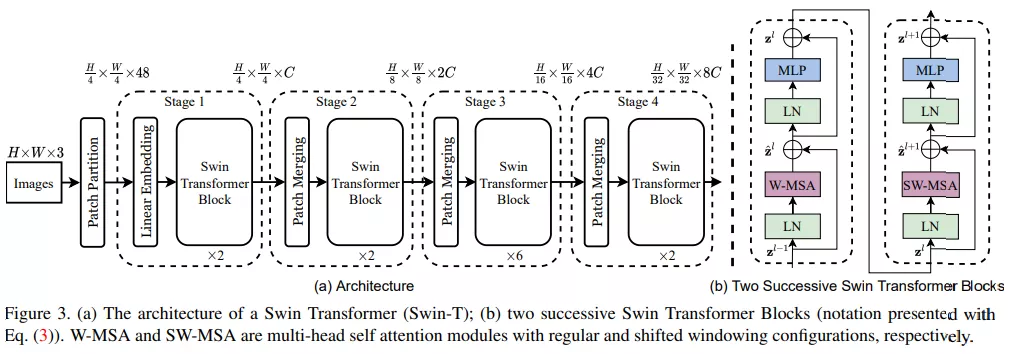
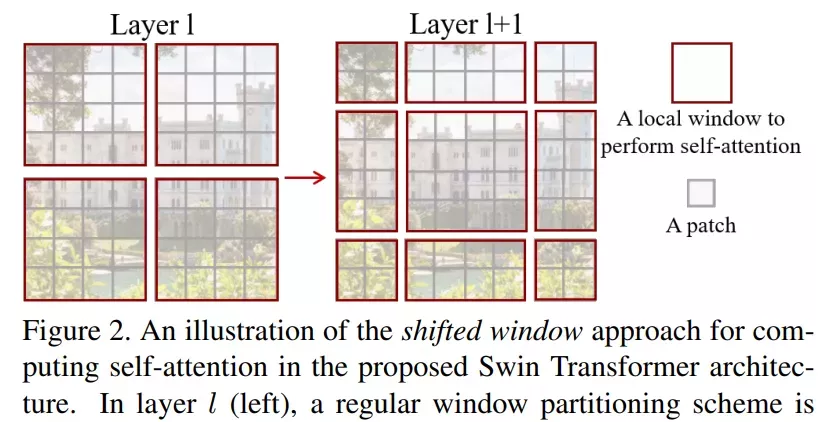
该研究的亮点在于利用移动窗口对分层 Transformer 的表征进行计算。通过将自注意力计算限制在不重叠的局部串口,同时允许跨窗口连接。这种分层结构可以灵活地在不同尺度上建模,并具有图像大小的线性计算复杂度。下图 2 为在 Swin Transformer 架构中利用移动窗口计算自注意力的工作流:
模型本身具有的特性使其在一系列视觉任务上都实现了颇具竞争力的性能表现。其中,在 ImageNet-1K 数据集上实现了 86.4% 的图像分类准确率、在 COCO test-dev 数据集上实现了 58.7% 的目标检测 box AP 和 51.1% 的 mask AP。目前在 COCO minival 和 COCO test-dev 两个数据集上,Swin-L(Swin Transformer 的变体)在目标检测和实例分割任务中均实现了 SOTA。

此外,在 ADE20K val 和 ADE20K 数据集上,Swin-L 也在语义分割任务中实现了 SOTA。
最佳学生论文奖
- 获奖论文:Pixel-Perfect Structure-from-Motion with Featuremetric Refinement
- 作者机构:苏黎世联邦理工学院、微软
- 论文地址:https://arxiv.org/pdf/2108.08291.pdf
- 项目地址:github.com/cvg/pixel-perfect-sfm (http://github.com/cvg/pixel-perfect-sfm)

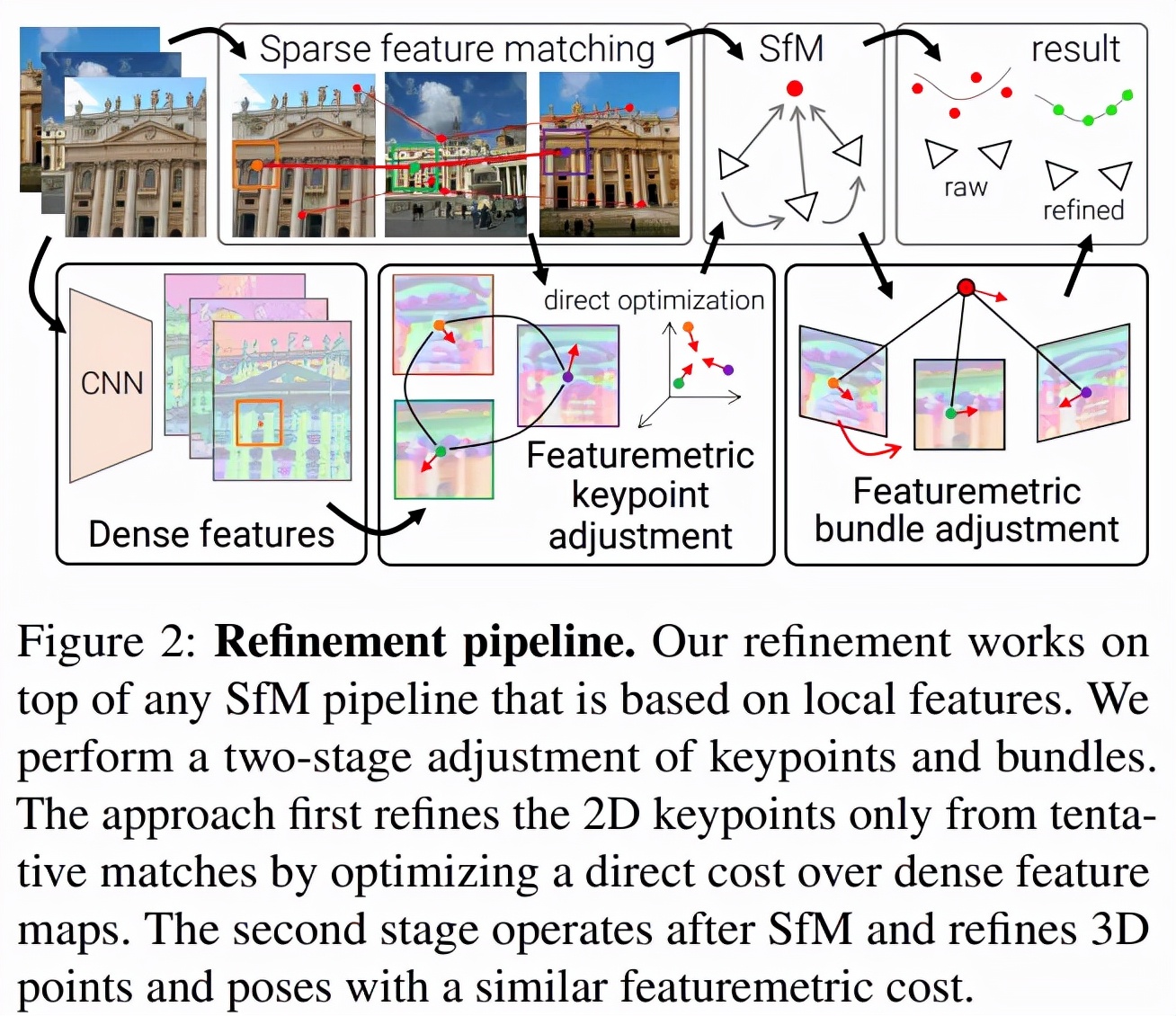
论文摘要:在多个视图中寻找可重复的局部特征是稀疏 3D 重建的基础。经典的图像匹配范式一次性检测每个图像的全部关键点(keypoint),这可能会产生定位不佳的特征,使得最终生成的几何形状出现较大错误。研究者通过直接对齐来自多个视图的低级图像信息来细化运动恢复结构(structure-from-motion,SFM)的两个关键步骤:首先在任何几何估计之前调整初始关键点位置,然后细化点和相机姿态作为一个后处理。这种改进对大的检测噪声和外观变化具有稳健性,因为它基于神经网络预测的密集特征优化了特征度量误差。这显著提高了相机姿态和场景几何的准确性,并适用于各种关键点检测器、具有挑战性的观看条件和现成的(off-the-shelf)深度特征。该系统可以轻松扩展到大型图像集合,从而实现像素完美的大规模众包定位。该方法现已封装为 SfM 软件 COLMAP 的附加组件。
细化几何原本是一种局部操作,但该研究表明局部密集像素可以起到较大的作用。SfM 通常尽可能早地丢弃图像信息,该研究借助直接对齐用几个步骤替代了 SfM。下图 2 是该方法的概览:
最佳论文荣誉提名奖
今年有四篇论文获得 ICCV 2021 最佳论文荣誉提名奖。
- 论文 1:Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields
- 作者机构:谷歌、加州大学伯克利分校
- 论文地址:https://arxiv.org/pdf/2103.13415.pdf

论文摘要:NeRF(neural radiance fields)使用的渲染过程以每像素单个光线对场景进行采样,因此当训练或测试图像以不同分辨率观察场景内容时,可能会产生过度模糊的渲染。该研究提出了 mip-NeRF,它以连续值的比例表示场景。他们通过高效地渲染消除反锯齿圆锥锥体( anti-aliased conical frustums)取代光线,mip NeRF 减少了混叠瑕疵(aliasing artifacts),并显著提高了其表示精细细节的能力,同时比 NeRF 快 7%,而大小仅为 NeRF 的一半。
与 NeRF 相比,mip NeRF 在数据集上降低了 17% 的平均错误率,在具有挑战性的多尺度变体上降低了 60% 的平均错误率。此外,Mip NeRF 还能够在多尺度数据集上与超采样 NeRF 的精度相匹配,同时速度快 22 倍。
- 论文 2:OpenGAN: Open-Set Recognition via Open Data Generation
- 作者机构:卡内基梅隆大学
- 论文地址:https://arxiv.org/pdf/2104.02939.pdf

论文摘要:真实世界的机器学习系统需要分析新的测试数据,而这些测试数据与训练数据不同。在 K-way 分类中,这被清晰地表述为开集识别,其核心是区分 K 个闭集类之外的开集数据的能力。关于开集的鉴别,有两种思想:1) 利用离群(outlier)数据作为开集,对开 - 闭(open-vs-closed)二进制鉴别器分别进行鉴别学习;2) 使用 GAN 对闭集数据分布进行无监督学习,并将其鉴别器作为开集似然函数。然而,前者不能很好地泛化到不同的开放测试数据,而后者由于 GAN 的训练不稳定效果不佳。
该研究提出了 OpenGAN,它通过将每种方法与几种技术见解相结合来解决每种方法的局限性。首先,他们展示了在一些真实的离群数据上,精心选择的 GAN 鉴别器已经达到了 SOTA 水平。其次,该研究用对抗性合成的假数据扩充可用的真实开集示例集。第三,也是最重要的,该研究在 K-way 网络计算的特征上可以构建鉴别器。大量实验表明,OpenGAN 显著优于先前的开集方法。
- 论文 3:Viewing Graph Solvability via Cycle Consistency
- 作者机构:特伦托大学等
- 论文地址:https://openaccess.thecvf.com/content/ICCV2021/papers/Arrigoni_Viewing_Graph_Solvability_via_Cycle_Consistency_ICCV_2021_paper.pdf

论文摘要:在运动恢复结构(structure-from-motion,SFM)中,视图图(viewing graph)是一种顶点与相机对应、边代表基本矩阵的图。该研究提供了一种新的公式和算法,用于确定视图图是否可解(即它唯一地确定一组投影相机)。已知的理论条件要么不能完全描述所有视图图的可解性,要么涉及求解含大量未知数的多项式方程组而非常难以计算。该论文的主要成果是提出一种利用循环一致性来减少未知数的方法。该研究通过以下 3 种方法来进一步理解可解性:(i) 完成对最多 9 个节点的所有先前未定最小图的分类;(ii) 将实际可解性测试扩展到具有最多 90 个节点的最小图;(iii) 通过证明有限可解性不等于可解性明确回答了一个开放型研究问题。最后,该研究以一个真实数据的实验表明在实际情况中出现了无解的图。
- 论文 4:Common Objects in 3D: Large-Scale Learning and Evaluation of Real-life 3D Category Reconstruction
- 作者机构:Facebook AI 研究院、伦敦大学学院
- 论文地址:https://arxiv.org/pdf/2109.00512.pdf

论文摘要:由于缺乏真实的以类别为中心的 3D 标注数据,传统的 3D 物体类别学习方法,主要是在合成数据集上进行训练和评估。该研究的主要目标是通过收集与现有合成数据类似的真实世界数据来促进该领域的进展。因此,这项工作的主要贡献是一个名为「Common Objects in 3D」的大规模数据集,,其中含有真实的多视角物体类别图像,并附有相机姿态和 3D 点云标注真值。该数据集包含来自近 19,000 个视频的 150 万帧捕获了 50 个 MS-COCO 类别的物体,因此它在类别和物体的数量方面都比其他数据集具有明显优势。研究者利用这个新数据集对几种新视图合成和以类别为中心的 3D 重建方法进行了大规模评估。此外,该研究还贡献了 NerFormer——一种新颖的神经渲染方法,利用强大的 Transformer 来重建仅给定少量视图的物体。
PAMI TC 奖
今年 ICCV 上的 PAMI 奖依旧包括四大奖项,分别是 Helmholtz 奖、Everingham 奖、Azriel Rosenfeld 终身成就奖和杰出研究者奖。
PAMI 是 IEEE 旗下的期刊,是模式识别和机器学习领域最重要的学术性汇刊之一,有着很高的影响因子和排名。
Helmholtz 奖
Helmholtz 奖项名称来源于 19 世纪的物理、生理学家 Hermann von Helmholtz,旨在奖励对计算机视觉领域做出重要贡献的工作,颁发对象是十年前对计算机视觉领域产生重大影响的论文。

今年共有 3 篇论文获得了 Helmholtz 奖,分别是:
- 论文 1:《ORB: An efficient alternative to SIFT or SURF》
- 论文链接:https://ieeexplore.ieee.org/document/6126544
- 论文 2:《HMDB: A large video database for human motion recognition》
- 论文链接:https://ieeexplore.ieee.org/document/6126543
- 论文 3:《DTAM: Dense tracking and mapping in real-time》
- 论文链接:https://ieeexplore.ieee.org/document/6126513
Everingham 奖
Everingham 奖的设立初衷是纪念计算机视觉领域专家 Mark Everingham 并激励后来者在计算机视觉领域做出更多贡献。颁奖对象包括为计算机视觉社区其他成员做出巨大贡献的无私研究者或研究团队。
本次获得 Everingham 奖项的分别是 Detectron 目标检测和分割软件团队和 KITTI 视觉基准团队。

Detectron 目标检测和分割软件团队成员包括 Ross Girshick, Yuxin Wu, llija Radosavovic, Alexander Kirillov, Georgia Gkioxari,Francisco Massa,Wan-Yen Lo,Piotr Dollar, 何恺明和其他开源贡献者。

KITTI 视觉基准团队成员包括 Andreas Geiger, Philip Lenz, Christoph Stiller, Raquel Urtasun 等。
Azriel Rosenfeld 终身成就奖
Azriel Rosenfeld 终身成就奖是为了纪念已故的计算机科学家和数学家 Azriel Rosenfeld 教授,旨在表彰在长期职业生涯中为计算机视觉领域作出突出贡献的杰出研究者。
今年的 Azriel Rosenfeld 终身成就奖颁给了 UC 伯克利电气工程与计算机科学系 NEC 特聘教授 Ruzena Bajcsy。

Ruzena Bajcsy 在斯坦福大学获得了计算机科学博士学位。从 1972 年到 2001 年,Ruzena Bajcsy 是宾夕法尼亚大学计算机与信息科学系的教授,并于 1978 年建立了通用机器人、自动化、传感和感知 (GRASP) 实验室。28 年间,她一直从事机器人研究,包括计算机视觉、触觉感知以及一般的系统识别问题。
在加入 UC 伯克利之前,她是美国国家科学基金会计算机与信息科学与工程理事会的负责人(1999-2001 年)。
Ruzena Bajcsy 美国国家工程院 (1997) 和美国国家医学科学院 (1995) 的成员,以及 ACM Fellow 和 AAAI Fellow。2002 年 11 月,她被《探索》杂志评为 50 位最重要的女性之一。由于在机器人和自动化领域的贡献,Ruzena Bajcsy 获得了本杰明富兰克林计算机和认知科学奖章(2009 年)和 IEEE 机器人与自动化奖(2013 年)。
杰出研究者奖
基于主要研究贡献及对其他研究的激发影响等考量原则,杰出研究者奖旨在奖励对计算机视觉发展作出重大贡献的研究者。
今年的杰出研究者奖获得者为 Pietro Perona 和 Cordelia Schmid。

Pietro Perona 是加州理工学院教授,他以计算机视觉领域的研究成果著名,同时也是加州理工学院计算机视觉小组的负责人。
Cordelia Schmid 是法国国家信息与自动化研究所(INRIA)的 THOTH 项目组负责人。她在 2012 年入选 IEEE Fellow,以表彰其在大规模图像检索、分类和目标检测方面的贡献。2020 年,Cordelia Schmid 获得了 Milner 奖。