自监督表征学习近两年十分火热。机器学习界的三位泰斗 Geoffroy Hinton、 Yann Lecun 、 Yoshua Bengio 一致认为自监督学习有望使 AI 产生类人的推理能力,其中 Hinton 与 Lecun 近两年也在 ICML / NeurIPS 中发表自监督表征学习的研究工作。
可以说在机器学习顶会发表自监督表征学习的文章,是与 Hinton 和 Lecun 站到了同一赛道上。而今年的 NeurIPS 2021,Lecun 刚发推感叹他与另外一位 CV 泰斗 Jean Ponce 的自监督投稿 VICReg 被拒掉了,可见在机器学习领域,自监督学习的竞争激烈程度。另外一方面,最近热门的 Transformer 给计算机视觉算法带来了全面的升级。那么 Transformer 跟自监督表征学习在一起会迸发出怎样的火花?
来自港大、腾讯 AI Lab、牛津大学的学者在 NeurIPS 2021 发表的文章会带来一个启发性的答案。
该研究受现有自监督表征学习架构 BYOL 的启示,结合前沿的 Transformer ,提出利用 Transfomer 来提升 CNN 注意力的自监督表征学习算法。本文将现有的架构归为 C-stream,另提出 T-stream。在 CNN 骨干网络的输出并行接入 T-stream。将 Transformer 置于 T-stream 中提升 CNN 输出的注意力,并以此结果来监督 CNN 自身的输出,从而达到提升 CNN 骨干网络注意力的效果。在现有的标准数据集中,也进一步提升了 CNN 骨干网络在下游识别任务的各类性能。

- 论文地址:https://arxiv.org/pdf/2110.05340.pdf
- Github 地址:https://github.com/ChongjianGE/CARE
背景和启示:自监督表征学习与样本对比
基于图像内容的自监督表征学习目标为训练一个普适的视觉特征编码器(encoder backbone)。在给定神经网络架构(如 VGG, ResNet)的情况下,摆脱数据标注依赖构建自监督的过程,进行从零开始的初始化训练(pretext training)。将训练好的网络认为类似于用 ImageNet 标注数据预训练的结果,后续将该网络进行一系列下游识别任务的迁移(downstream finetuning),包括图像分类,物体检测和分割。由于在初始化训练中未使用数据标签做约束,预训练的网络表征并不针对下游具体的某个识别任务,从而具备普适的视觉表征能力。其潜在的应用在于利用海量的互联网数据,摆脱人工标注的、依赖自适应学习神经网络的视觉表征能力,从而能够受益于一系列的下游识别任务。自监督学习在下游识别任务中可以媲美有监督学习。
在自监督表征学习的研究中,对比学习 (contrastive learning) 为常用的方法。给定一批未标注的数据,以当前一个数据为正样本,其余数据为负样本。对比学习通过这样的方式,构建正负样本及其增广的数据来确定损失函数从而训练网络。其中一个输入数据通过两路网络形成两个不同的 view,进行后续的样本对比。在处理海量数据的过程中,有效的从数据中构建样本和防止模型坍塌成为了热门研究方向。从 MoCo[a]的队列设计及网络动量更新开始,一系列的研究工作应运而生。这里介绍几个代表性的工作,为简洁起见,算法框架图中的映射器 (projector) 没有画出:
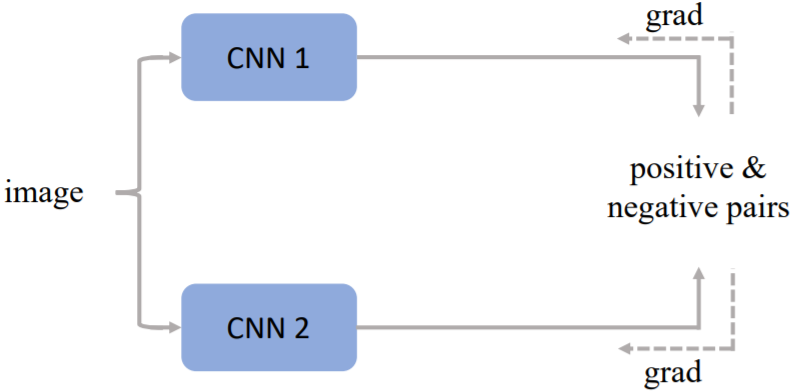
SimCLR
上图为 Hinton 团队的 SimCLR[b]算法框架,其采用 large batch 的设计,摆脱队列存储的依赖,直接对正负样本进行对比构造损失来更新网络。
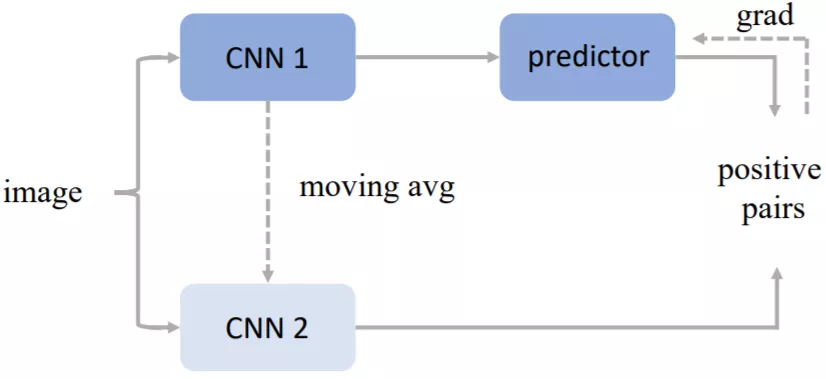
BYOL
上图为 DeepMind 团队的 BYOL[c]算法框架,其单纯利用当前样本进行自身的多种数据增广进行对比。同时引入 projector 来摆脱上下游任务对于网络的影响。在更新网络时也采用了动量更新的方式防止模型的坍塌。
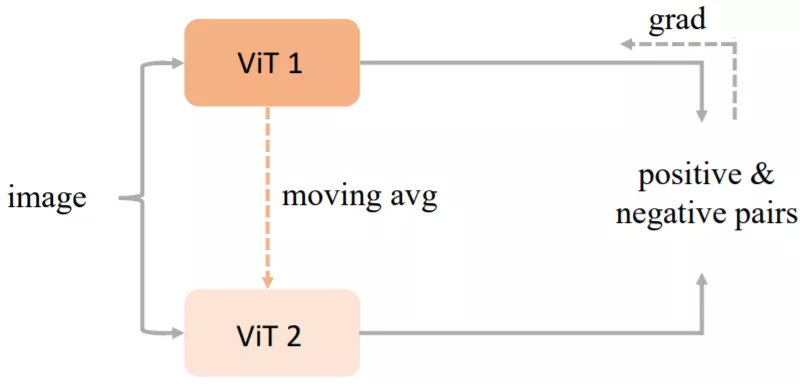
MoCo V3
上图为 Kaiming He 团队的 MoCo V3[d],其将 transformer 做为学习编码器(encoder backbone),利用现有的自监督学习框架进行样本对比学习。同时也是将 vision transformer (ViT[e])作为编码器引入自监督学习中的工作之一。
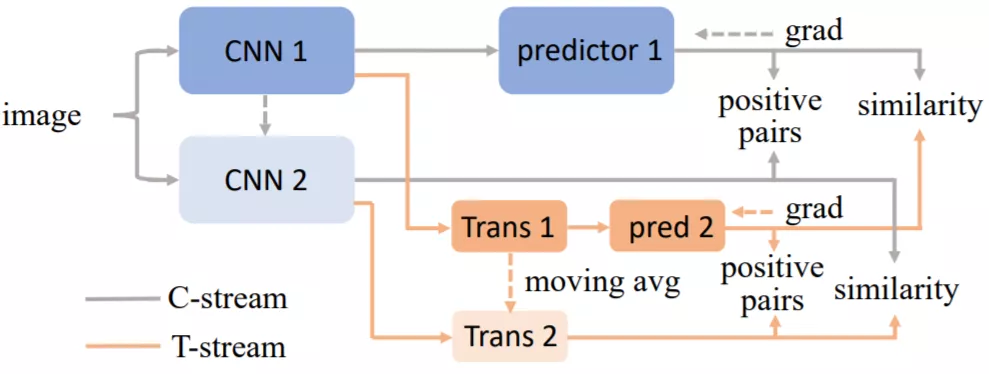
本文方法
与 MoCo V3 的出发点不同,本文的工作旨在利用 transformer 的自注意力机制来提升 CNN 编码器的性能。其中将原有的 CNN 框架归为 C-stream,然后提出包含 Transformer 的 T-stream。两个 stream 同时接收 CNN 编码器的输出,然后用 T-stream 监督 C-stream。相比于 Yann Lecun 团队的 Barlow Twins[f]利用协方差矩阵衡量两个 view 的冗余,本文引入可学习的 transformer 能够自适应的在不同网络训练状态下提供注意力的辅助,从而更有效的提升 CNN 编码器的视觉表征能力。
本文的方法:CARE (CNN Attention REvitalization)
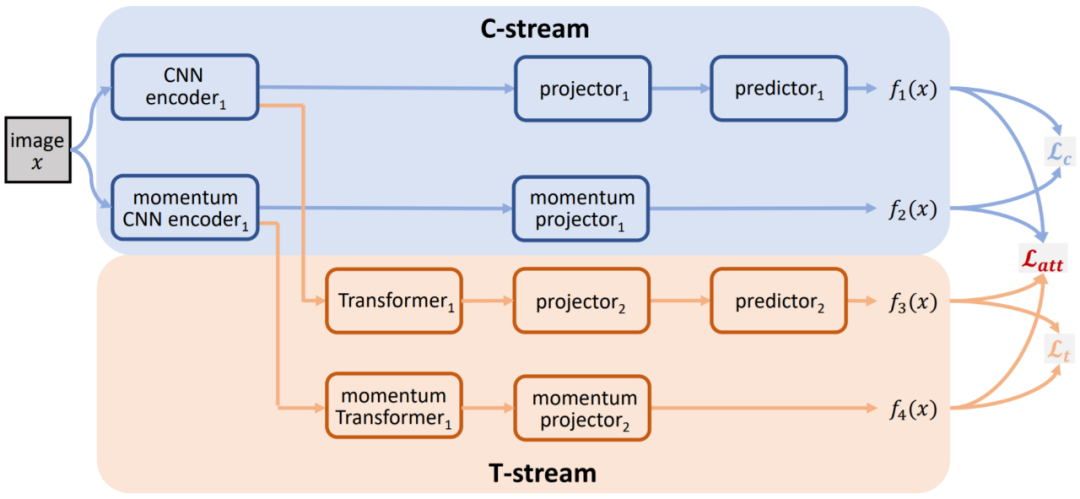
Proposed pipeline
本文提出的算法流程图如上所示。首先将输入图像x进行两次不同的预处理得到两个正样本x_1、x_2。然后,用 C-stream 的两个 CNN 编码器分别提取x_1、x_2的特征,其中将一路 CNN 提取的特征输入映射器 projector1 和预测器 predictor1 得到高维特征f_1(x),同时将另一路 CNN 提取的特征仅输入动量更新的映射器 (momentum projector1) 得到高维特征f_2(x)。此外,双路 CNN 提取的这两组特征也会被同时输入到 T-stream。其中一路的 Transformer1 提取具有空间注意力的特征,并将此特征输入到映射器 projector2 和预测器 predictor2 得到高维特征f_3(x)。另一路动量更新的 Transformer 同样提取 CNN 特征并输入动量更新的映射器 momentum projector2 得到高维特征f_4(x)。
至此,算法框架的前向过程已经设计完成。后续通过对f_1(x)、f_2(x)、f_3(x)、f_4(x)进行针对性的损失函数设计进行反向传播的学习。本算法在反向传播过程中,仅更新 C-stream 以及 T-stream 的其中一路,而对应的另外一路则利用动量更新 (momentum update) 的手段进行。具体形式在后续介绍。
网络架构设计:本算法旨在通过自监督学习框架的搭建,利用自定义的辅助任务来学习一个能够有效提取图像特征的 CNN 编码器。本算法对任意的 CNN 编码器均具有一定的适用性,因此在 CNN 编码器的选取上有着很好的灵活性。例如,ResNet50,ResNet101 以及 ResNet152 皆可以作为本算法的 CNN 编码器。Transformer 的结构如下图所示:
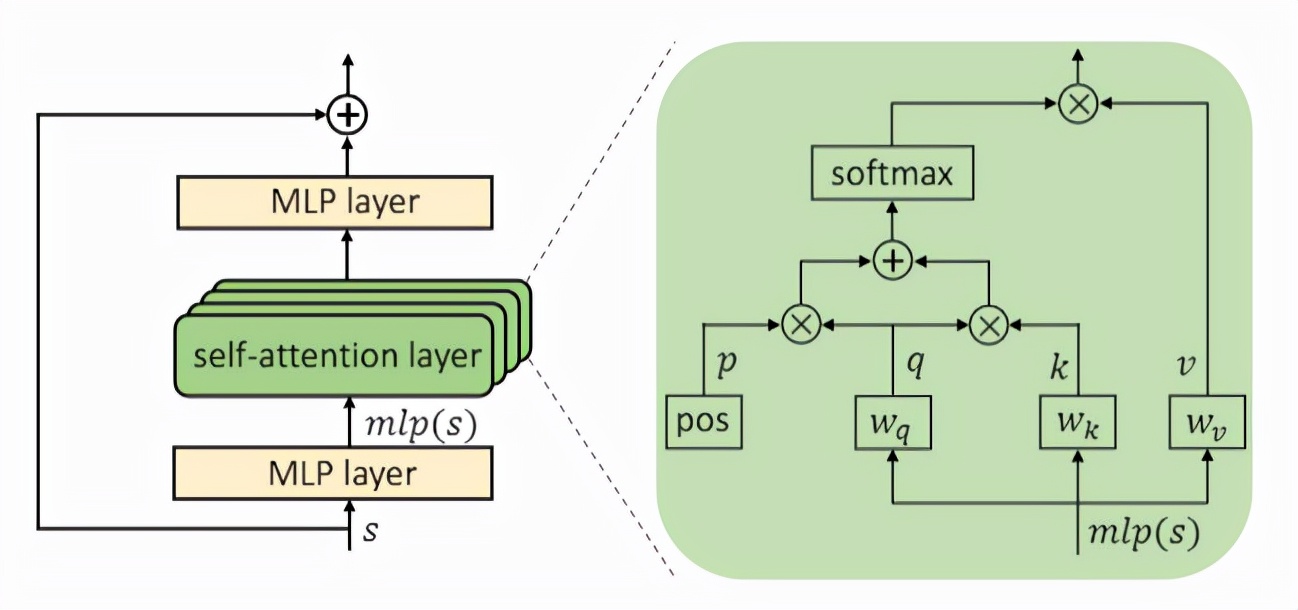
Transformer 结构示意图
该 Transformer 以 CNN 编码器输出为输入,并输出f_1(x)、f_2(x)、f_3(x)、f_4(x)更具空间专注度性质的特征。本算法所设计的 Transformer 主要包括 4 个串行的模块,其中单个模块如上图所示。单个模块主要包含由一个 1x1 的卷积层,一个多头自注意力层(Multi-head Self-attention, MHSA)[g]以及额外一个 1x1 卷积层组成。其中 MHSA 层可以很好地学习到具有空间专注度性质的特征。此外,映射器 projector 和预测器 predictor 的主要结构为多层感知器(Multi-layer perceptron)。两者皆包含两个全线性连接层(fully connected layers),一个激活层以及一个标准化层(batch normalization)。
本文设计的损失函数基于流程框架中的四个输出f_1(x)、f_2(x)、f_3(x)、f_4(x)。其中本文用
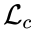
表示 C-stream 的损失项,用
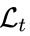
表示 T-stream 的损失项。其具体形式如下:
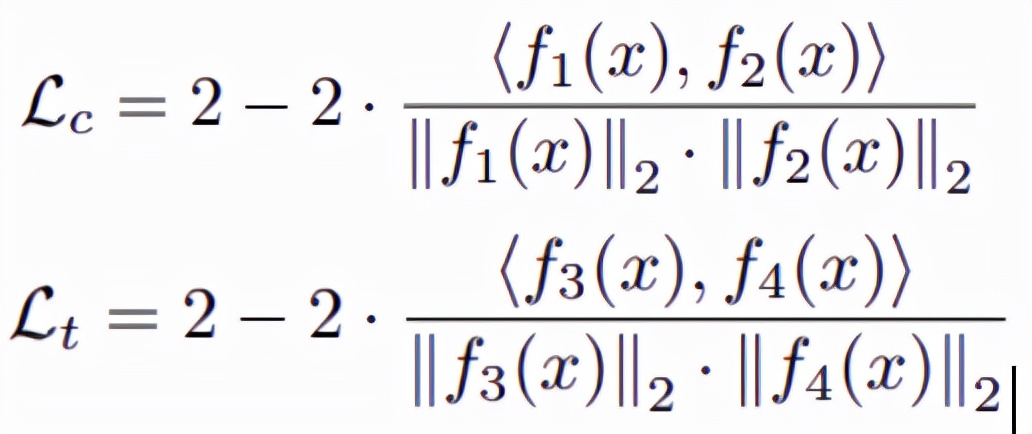
此外,本文用 T-stream 的输出来监督 C-stream 的输出。这个约束用
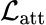
表示,具体形式如下:
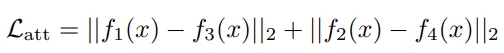
该约束表明在自监督学习中,C-stream 的输出会与 T-stream 的输出尽量相似。所以最终整体的损失函数可以由如下表示:
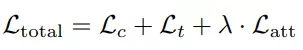
在计算整体损失后,本算法只后向传播梯度更新 C-stream 和 T-stream 的上支。其下路分支主要通过动量更新的方式来更新参数。所谓动量更新指的主要是利用当前 C-Stream 和 T-Stream 的上路分支的参数,以及其之前时刻的参数信息,来动量更新其下路分支的网络参数。在网络训练结束后,只保留 CNN encoder1 作为目标编码器。该编码器随后会用做下游识别任务的 backbone 网络。
可视化分析:CNN 编码器的注意力展示
在自监督训练结束后,本文对 CNN 编码器进行特征响应的可视化展示,从而观察编码器在训练后对视觉内容关注程度的变化。本文对同样的编码器进行两种自监督策略,一种是只使用 C-stream 的结构进行训练,一种是使用全部结构进行训练。本文对这两种训练策略下的同样的编码器进行可视化展示,如下图所示:

CNN 编码器的注意力可视化展示
从图中可以看到,第一行为输入图像,第二行为单纯利用 C-stream 结构进行训练的编码器的注意力,第三行为利用本文提出 CARE 结构进行训练的编码器的注意力。通过观察注意力在图像上面的分布和强度可以看出,本文提出的 CARE 算法训练的编码器对图像中的物体更敏感,注意力更强烈。
实验结果
在实验过程中,本文从多个方面验证提出算法的有效性。包括上游训练好的模型在线性分类问题中的性能、在半监督数据中的效果,以及在下游物体检测和分割任务中的性能。在骨干网络模型选择方面,本文选取了 CNN 通用的 ResNet 系列模型进行训练。对比模型为 ResNet 系列和 Transformer 结构。验证的方式为利用不同的自监督学习算法在多种模型上进行各类任务不同训练阶段中的性能验证。在本文算法的训练过程中,使用 8 卡 V100 算力即可进行模型训练的收敛。在当前海量算力的视觉自监督表征学习任务下相对算力友好。
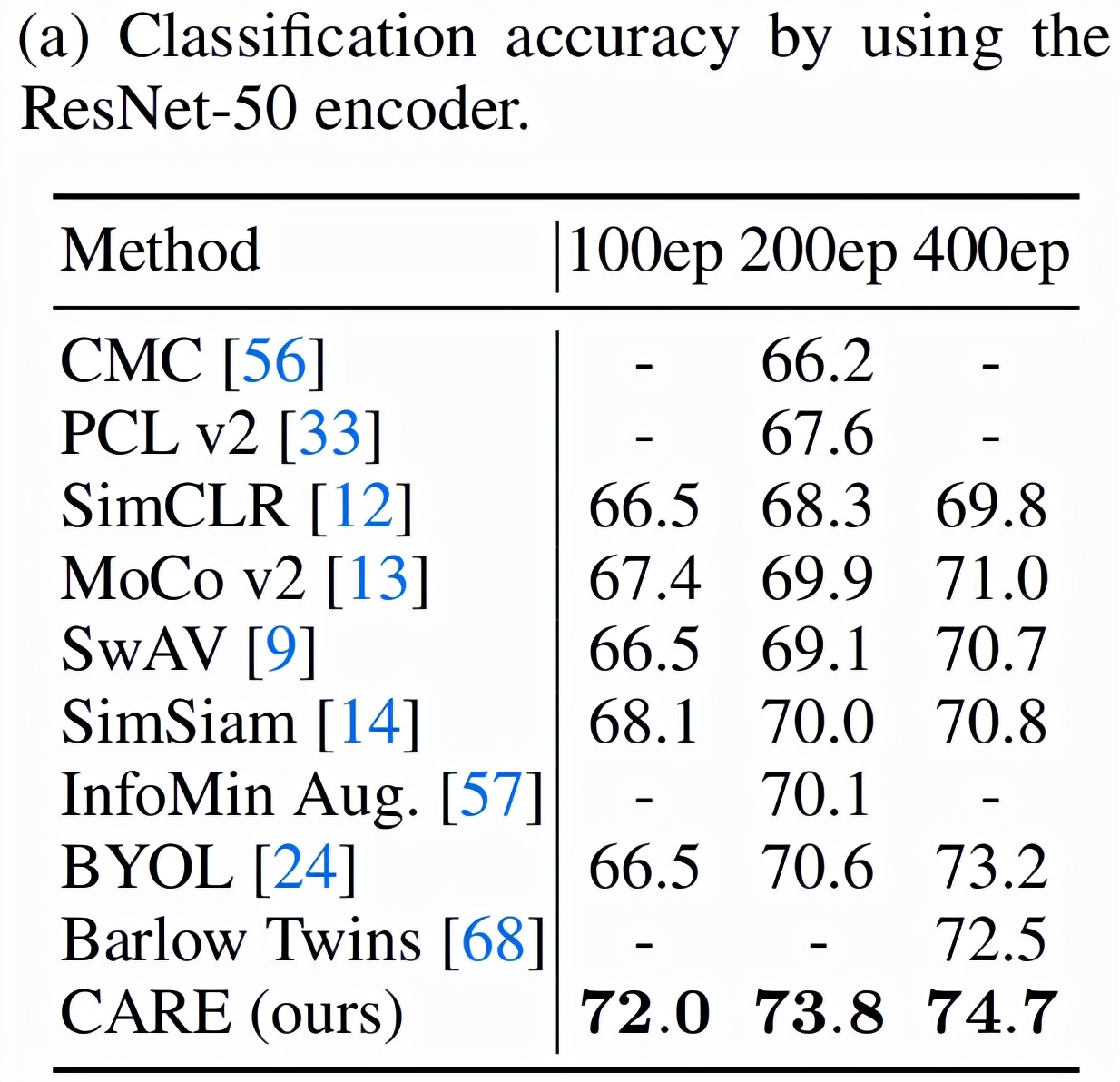
上游任务线性分类的比较。在固定 ResNet-50 为骨干网络情况下,针对不同的自监督学习算法进行训练,展示在不同训练阶段的线性分类效果。如下图所示,本文提出的 CARE(CNN attention revitalization)方法取得的优异的表现。
此外,本文也与 BYOL 方法在 ResNet 不同骨干网络、不同训练阶段的性能进行对比,如下图所示。本文的 CARE 方法在不同骨干网络下性能更佳。
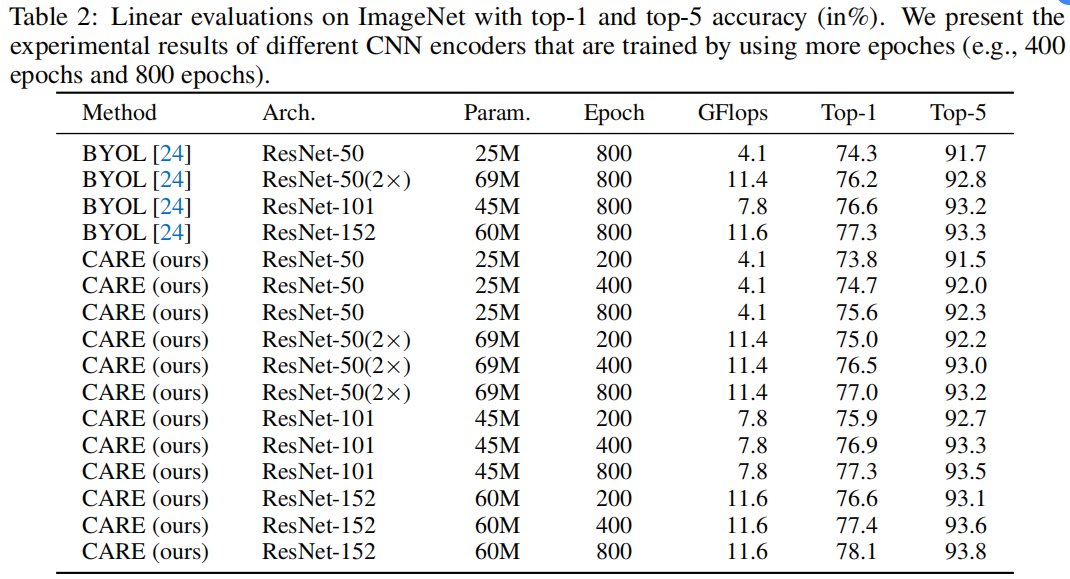
以上为相同骨干网络、不同学习算法的对比。本文同时也对比了 Transformer 的骨干网络以及现有的学习算法。效果如下图所示,跟 Transformer 结构相比,本文利用 ResNet 网络,在参数量相近的情况下,取得了更好的结果。
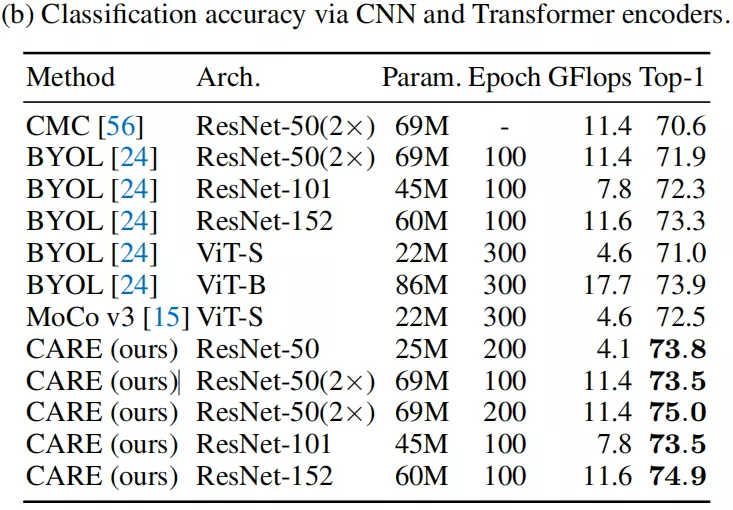
更多的实验对比,以及 CARE 算法的 Ablation Study 详见文章中的实验章节。
总结
综上,本文提出了一个利用 Transformer 结构来辅助 CNN 网络训练的视觉自监督表征学习框架。其核心贡献在于利用一种网络结构的特性(即 Transformer 的注意力提升特性),在训练中监督目标网络(即 CNN 骨干网络),从而使得网络特性能够得到迁移并提升目标网络性能的效果。在视觉识别的各类任务中也得到了充分验证。本文的框架对自监督表征学习具有很强的启示意义,现有网络结构设计繁多,功能各异。如何利用这些网络独有的特点,进而集成在一个网络中达到浑然一体的目标,也是后续自监督表征学习可探索的重要方向。