特斯拉、谷歌、微软、Facebook 等科技巨头有很多共同点,其中之一是:它们每天都会运行数十亿次 Transformer 模型预测。比如,Transformer 在特斯拉 AutoPilot 自动驾驶系统中驱动汽车、在 Gmail 中补全句子、在 Facebook 上及时翻译用户的帖子以及在 Bing 中回答用户的自然语言查询。
Transformer 在机器学习模型的准确率方面带来了巨大提升,风靡 NLP 领域,并正在扩展到其它模态上(例如,语音和视觉)。然而,对于任何一个机器学习工程团队来说,将这些大模型应用于工业生产,使它们大规模快速运行都是一个巨大的挑战。
如果没有像上述企业一样聘用数百名技艺高超的机器学习工程师,应该怎么应用这样的大规模模型呢?近日,Hugging Face 开源了一个新的程序包「Optimum」,旨在为 Transformer 的工业生产提供最佳的工具包,使得可以在特定的硬件上以最高的效率训练和运行模型。
项目地址:https://github.com/huggingface/blog/blob/master/hardware-partners-program.md
Optimum 使 Transformer 实现高效工作
为了在训练和服务模型过程中得到最佳性能,模型加速技术需要与目标硬件兼容。每个硬件平台都提供了特定的软件工具、特性和调节方式,它们都会对性能产生巨大影响。同样地,为了利用稀疏化、量化等先进的模型加速技术,优化后的内核需要与硅上的操作兼容,并特定用于根据模型架构派生的神经网络图。深入思考这个三维的兼容性矩阵以及如何使用模型加速库是一项艰巨的工作,很少有机器学习工程师拥有这方面的经验。
Optimum 的推出正是为了「简化这一工作,提供面向高效人工智能硬件的性能优化工具,与硬件合作者合作,赋予机器学习工程师对其机器学习的优化能力。」
通过 Transformer 程序包,研究人员和工程师可以更容易地使用最先进的模型,无需考虑框架、架构、工作流程的复杂性;工程师们还可以轻松地利用所有可用硬件的特性,无需考虑硬件平台上模型加速的复杂性。
Optimum 实战:如何在英特尔至强 CPU 上进行模型量化
量化为何如此重要却又难以实现?
BERT 这种预训练语言模型在各种各样的 NLP 任务上取得了目前最佳的性能,而 ViT、SpeechText 等其它基于 Transformer 的模型分别在计算机视觉和语音任务上也实现了最优的效果。Transformer 在机器学习世界中无处不在,会一直存在下去。
然而,由于需要大量的算力,将基于 Transformer 的模型应用于工业生产很困难,开销巨大。有许多技术试图解决这一问题,其中最流行的方法是量化。可惜的是,在大多数情况下,模型量化需要大量的工作,原因如下:
首先,需要对模型进行编辑。具体地,我们需要将一些操作替换为其量化后的形式,并插入一些新的操作(量化和去量化节点),其它操作需要适应权值和激活值被量化的情况。
例如,PyTorch 是在动态图模式下工作的,因此这部分非常耗时,这意味着需要将上述修改添加到模型实现本身中。PyTorch 现在提供了名为「torch.fx」的工具,使用户可以在不改变模型实现的情况下对模型进行变换,但是当模型不支持跟踪时,就很难使用该工具。在此基础之上,用户还需要找到模型需要被编辑的部分,考虑哪些操作有可用的量化内核版本等问题。
其次,将模型编辑好后,需要对许多参数进行选择,从而找到最佳的量化设定,需要考虑以下三个问题:
- 应该使用怎样的观测方式进行范围校正?
- 应该使用哪种量化方案?
- 目标设备支持哪些与量化相关的数据类型(int8、uint8、int16)?
再次,平衡量化和可接受的准确率损失。
最后,从目标设备导出量化模型。
尽管 PyTorch 和 TensorFlow 在简化量化方面取得了很大的进展,但是基于 Transformer 的模型十分复杂,难以在不付出大量努力的情况下使用现成的工具让模型工作起来。
英特尔的量化神器:Neural Compressor
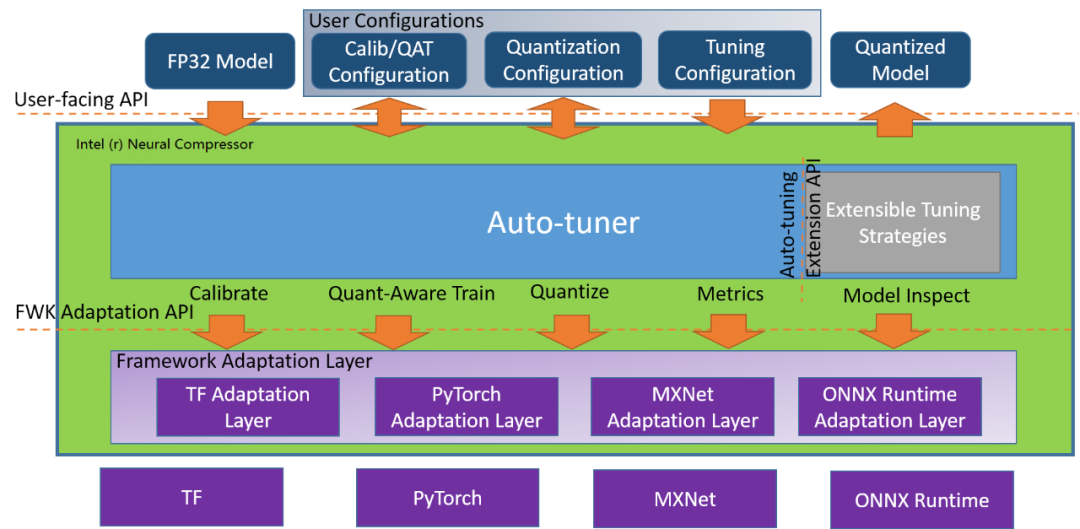
Neural Compressor 架构示意图。地址:https://github.com/intel/neural-compressor
英特尔开源的 Python 程序库 Neural Compressor(曾用名「低精度优化工具」——LPOT)用于帮助用户部署低精度的推理解决方案,它通过用于深度学习模型的低精度方法实现最优的生产目标,例如:推理性能和内存使用。
Neural Compressor 支持训练后量化、量化的训练以及动态量化。为了指定量子化方法、目标和性能评测标准,用户需要提供指定调优参数的配置 yaml 文件。配置文件既可以托管在 Hugging Face 的 Model Hub 上,也可以通过本地文件夹路径给出。
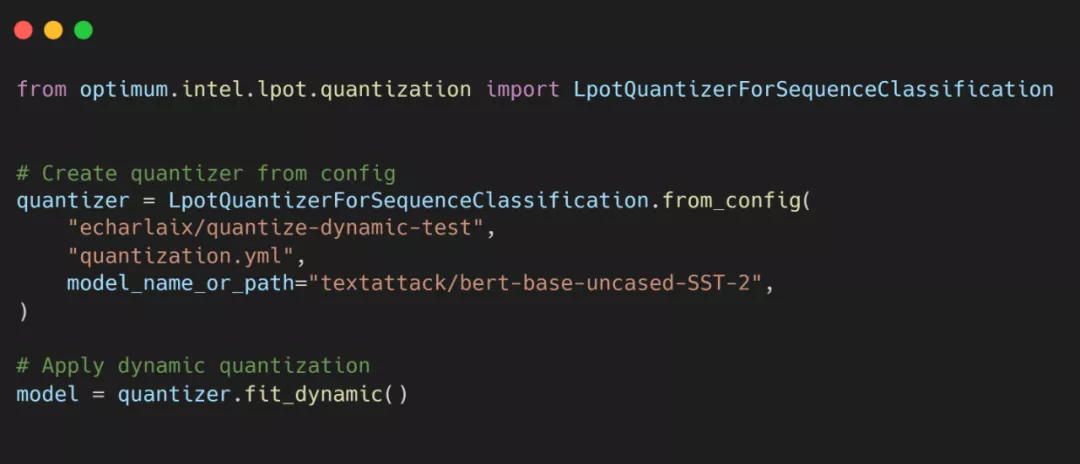
使用 Optimum 在英特尔至强 CPU 上轻松实现 Transformer 量化
实现代码如下:
踏上 ML 生产性能下放的大众化之路
SOTA 硬件
Optimum 重点关注在专用硬件上实现最优的生产性能,其中软件和硬件加速技术可以被用来实现效率最大化。Optimum 团队将与硬件合作伙伴协作,从而赋能、测试和维护加速技术,将其以一种简单易用的方式交互。该团队近期将宣布新的硬件合作者,与其一同实现高效机器学习。
SOTA 模型
Optimum 团队将与硬件合作伙伴研究针对特定硬件的优化模型设置和组件,成果将在 Hugging Face 模型上向人工智能社区发布。该团队希望 Optimum 和针对特定硬件优化的模型可以提升生产流程中的效率,它们在机器学习消耗的总能量中占很大的比例。最重要的是,该团队希望 Optimum 促进普通人对大规模 Transformer 的应用。