Serverless 应用调试秘诀
在应用开发过程中,或者应用开发完成,所执行结果不符合预期时,我们要进行一定的调试工作。但是在 Serverless 架构下,调试往往会受到极大的环境限制,出现所开发的应用在本地可以健康、符合预期的运行,但是在 FaaS 平台上发生一些不可预测的问题的情况。而且在一些特殊环境下,本地没有办法模拟线上环境,难以进行项目的开发和调试。
Serverless 应用的调试一直都是备受诟病的,但是各个云厂商并没有因此放弃在调试方向的深入探索。以阿里云函数计算为例,其提供了在线调试、本地调试等多种调试方案。
在线调试
1.简单调试
所谓的简单调试,就是在控制台进行调试。以阿里云函数计算为例,其可以在控制台通过“执行”按钮,进行基本的调试,如图所示。
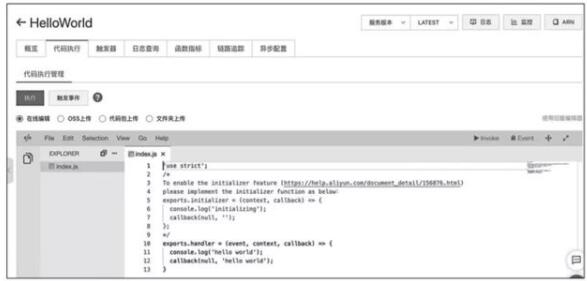
函数在线简单调试页面
必要的时候,我们也可以通过设置 Event 来模拟一些事件,如图所示。
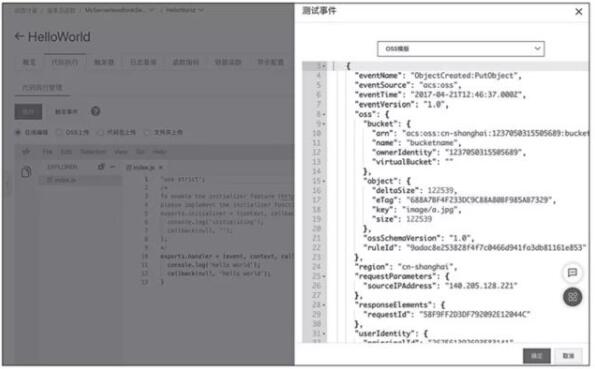
通过设置 Event 模拟事件
在线调试的好处是,可以使用线上的一些环境进行代码的测试。当线上环境拥有 VPC 等资源时,在本地环境是很难进行调试的,例如数据库需要通过 VPC 访问,或者有对象存储触发器的业务逻辑等。
2.断点调试
除了简单的调试之外,部分云厂商也支持断点调试,例如阿里云函数计算的远程调试、腾讯云云函数的远程调试等。以阿里云函数计算远程调试为例,其可以通过控制台进行函数的在线调试。当创建好函数之后,用户可以选择远程调试,并点击“开启调试”按钮,如图所示。
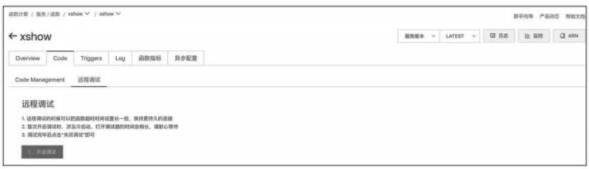
函数在线断点调试页面(一)
开启调试之后,稍等片刻,系统将会进入远程调试界面,如图所示。
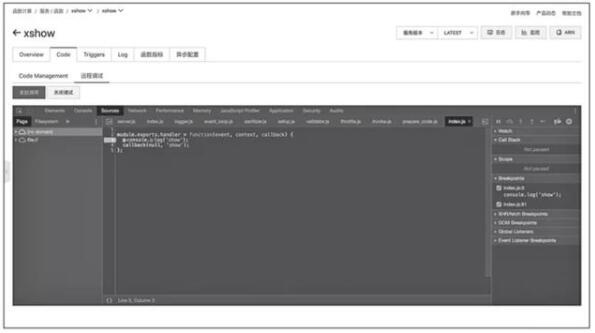
函数在线断点调试页面(二)
此时可以进行一些断点调试,如图所示。
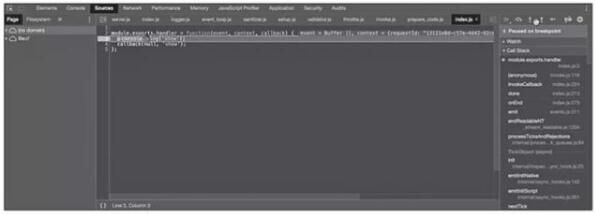
函数在线断点调试页面(三)
本地调试
1.命令行工具
就目前来看,大部分 FaaS 平台都会为用户提供相对完备的命令行工具,包括 AWS 的SAM CLI、阿里云的 Funcraft,同时也有一些开源项目例如 Serverless Framework、Serverless Devs 等对多云厂商的支持。通过命令行工具进行代码调试的方法很简单。以 Serverless Devs 为例,本地调试阿里云函数计算。
首先确保本地拥有一个函数计算的项目,如图所示。
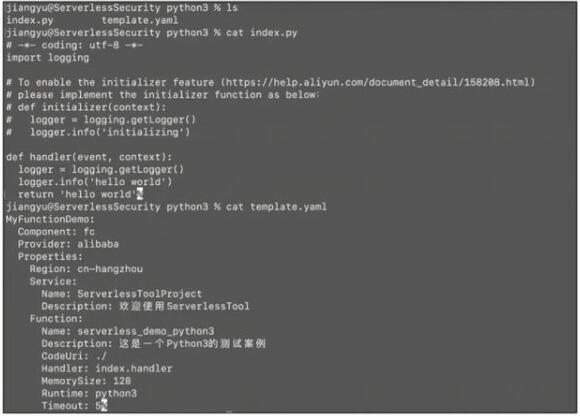
本地函数计算项目
然后在项目下执行调试指令,例如在 Docker 中进行调试,如图所示。
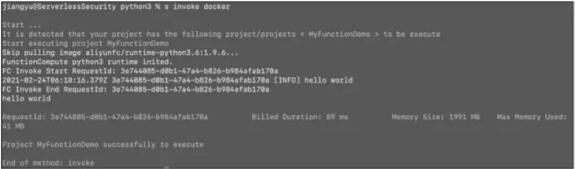
命令行工具调试函数计算
2.编辑器插件
以 VScode 插件为例,当下载好阿里云函数计算的 VSCode 插件,并且配置好账号信息之后,可以在本地新建函数,并且在打点之后可以进行断点调试,如图所示。
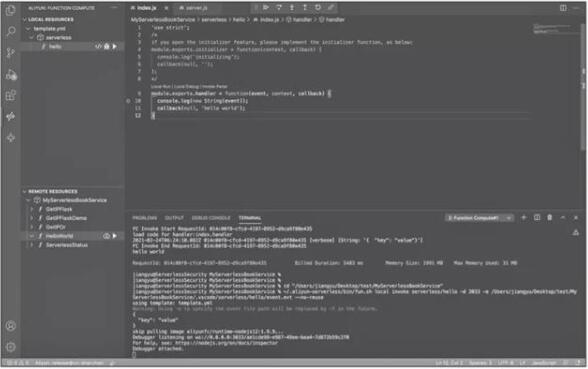
VSCode 插件调试函数计算
当函数调试完成之后,执行部署等操作。
其他调试方案
1.Web 框架的本地调试
在阿里云 FaaS 平台开发传统 Web 框架,以 Python 语言编写的 Bottle 框架为例,可以增加以下代码:
- app = bottle.default_app()并且对run方法进行条件限制 (if __name__ == '__main__'):if __name__ == '__main__': bottle.run(host='localhost', port=8080, debug=True)例如:# index.pyimport bottle@bottle.route('/hello/<name>')def index(name): return "Hello world"app = bottle.default_app()if __name__ == '__main__': bottle.run(host='localhost', port=8080, debug=True)
当部署应用到线上时,只需要在入口方法处填写 ndex.app,即可实现平滑部署。
2.本地模拟事件调试
针对非 Web 框架,我们可以在本地构建一个方法,例如要调试对象存储触发器:
- import jsondef handler(event, context): print(event)def test(): event = { "events": [ { "eventName": "ObjectCreated:PutObject", "eventSource": "acs:oss", "eventTime": "2017-04-21T12:46:37.000Z", "eventVersion": "1.0", "oss": { "bucket": { "arn": "acs:oss:cn-shanghai:123456789:bucketname", "name": "testbucket", "ownerIdentity": "123456789", "virtualBucket": "" }, "object": { "deltaSize": 122539, "eTag": "688A7BF4F233DC9C88A80BF985AB7329", "key": "image/a.jpg", "size": 122539 }, "ossSchemaVersion": "1.0", "ruleId": "9adac8e253828f4f7c0466d941fa3db81161****" }, "region": "cn-shanghai", "requestParameters": { "sourceIPAddress": "140.205.***.***" }, "responseElements": { "requestId": "58F9FF2D3DF792092E12044C" }, "userIdentity": { "principalId": "123456789" } } ] } handler(json.dumps(event), None)if __name__ == "__main__": print(test())
这样,通过构造一个 event 对象,即可实现模拟事件触发。
Serverless 应用优化
资源评估依旧重要
Serverless 架构虽然是按量付费的,但是并不代表它就一定比传统的服务器租用费用低。如果对自己的项目评估不准确,对一些指标设置不合理,Serverless 架构所产生的费用可能是巨大的。
一般情况下,FaaS 平台的收费和三个指标有直接关系,即所配置的函数规格(例如内存规格等)、程序所消耗的时间以及产生的流量费用。通常情况下,程序所消耗的时间可能与内存规格、程序本身所处理的业务逻辑有关。流量费用与程序本身和客户端交互的数据包大小有关。所以在这三个常见的指标中,可能因为配置不规范导致计费出现比较大偏差的就是内存规格。以阿里云函数计算为例,假设有一个 Hello World 程序,每天都会被执行 10000 次,不同规格的内存所产生的费用(不包括网络费用)如表所示。

通过表中可以看到,当程序在 128MB 规格的内存中可以正常执行,如果错误地将内存规格设置成 3072MB,可能每月产生的费用将会暴涨 25 倍!所以在上线 Serverless 应用之前,要对资源进行评估,以便以更合理的配置来进一步降低成本。
合理的代码包规格
各个云厂商的 FaaS 平台中都对代码包大小有着限制。抛掉云厂商对代码包的限制,单纯地说代码包的规格可能会产生的影响,通过函数的冷启动流程可以看到,如图所示。

函数冷启动流程简图
在函数冷启动过程中,当所上传的代码包过大,或者文件过多导致解压速度过慢,就会使加载代码过程变长,进一步导致冷启动时间变久。
设想一下,当有两个压缩包,一个是只有 100KB 的代码压缩包,另一个是 200MB 的代码压缩包,两者同时在千兆的内网带宽下理想化(即不考虑磁盘的存储速度等)下载,即使最大速度可以达到 125MB/s,那么前者的下载时间只有不到 0.01 秒,后者需要 1.6 秒。除了下载时间之外,加上文件的解压时间,那么两者的冷启动时间可能就相差 2 秒。一般情况下,对于传统的 Web 接口,如果要 2 秒以上的响应时间,实际上对很多业务来说是不能接受的,所以在打包代码时就要尽可能地降低压缩包大小。以 Node.js 项目为例,打包代码包时,我们可以采用 Webpack 等方法来压缩依赖包大小,进一步降低整体代码包的规格,提升函数的冷启动效率。
合理复用实例
为了更好地解决冷启动的问题、更合理地利用资源,各个云厂商的 FaaS 平台中是存在实例复用情况的。所谓的实例复用,就是当一个实例完成一个请求后并不会释放,而是进入静默的状态。在一定时间范围内,如果有新的请求被分配过来,则会直接调用对应的方法,而不需要再初始化各类资源等,这在很大程度上减少了函数冷启动的情况出现。为了验证,我们可以创建两个函数:
- 函数1:# -*- coding: utf-8 -*-def handler(event, context): print("Test") return 'hello world'函数2:# -*- coding: utf-8 -*-print("Test")def handler(event, context): return 'hello world'
在控制台点击“测试”按钮,对上述两个函数进行测试,判断其是否在日志中输出了 “Test”,统计结果如表所示。

函数复用记录
可以看到,其实实例复用的情况是存在的。进一步思考,如果 print("Test") 语句是一个初始化数据库连接,或者是函数 1 和函数 2 加载了一个深度学习模型,是不是函数 1 就是每次请求都会执行,而函数 2 可以复用已有对象?
所以在实际的项目中,有一些初始化操作是可以按照函数 2 实现的,例如:
在机器学习场景下,在初始化的时候加载模型,避免每次函数被触发都会加载模型。
在初始化的时候建立链接对象,避免每次请求都创建链接对象。
其他一些需要首次加载时下载、加载的文件在初始化时实现,提高实例复用效率。
善于利用函数特性
各个云厂商的 FaaS 平台都有一些特性。所谓的平台特性,是指这些功能可能并不是 CNCF WG-Serverless Whitepaper v1.0 中规定的能力或者描述的能力,仅仅是作为云平台根据自身业务发展和诉求从用户角度出发挖掘出来并且实现的功能,可能只是某个云平台或者某几个云平台所拥有的功能。这类功能一般情况下如果利用得当会让业务性能有质的提升。
1.Pre-freeze & Pre-stop
以阿里云函数计算为例,在平台发展过程中,用户痛点(尤其是阻碍传统应用平滑迁移至 Serverless 架构)如下。
异步背景指标数据延迟或丢失:如果在请求期间没有发送成功,则可能被延迟至下一次请求,或者数据点被丢弃。
同步发送指标增加延时:如果在每个请求结束后都调用类似 Flush 接口,不仅增加了每个请求的延时,对于后端服务也产生了不必要的压力。
函数优雅下线:实例关闭时应用有清理连接、关闭进程、上报状态等需求。在函数计算中实例下线时,开发者无法掌握,也缺少 Webhook 通知函数实例下线事件。
根据这些痛点,阿里云发布了运行时扩展 (Runtime Extensions) 功能。该功能在现有的 HTTP 服务编程模型上扩展,在已有的 HTTP 服务器模型中增加了 PreFreeze 和 PreStop Webhook。扩展开发者负责实现 HTTP handler,监听函数实例生命周期事件,如图所示。
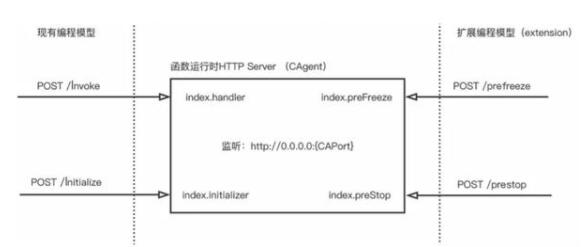
扩展编程模型与现有编程模型处理的工作内容简图
PreFreeze:在每次函数计算服务决定冷冻当前函数实例前,函数计算服务会调用 HTTP GET/prefreeze 路径,扩展开发者负责实现相应逻辑以确保完成实例冷冻前的必要操作,例如等待指标发送成功等,如图所示。函数调用 InvokeFunction 的时间不包含 PreFreeze Hook 的执行时间。
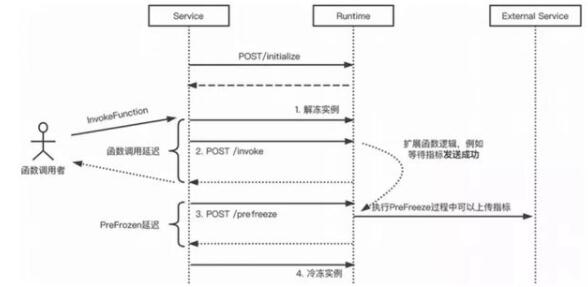
PreFreeze时序图
PreStop:在每次函数计算决定停止当前函数实例前,函数计算服务会调用 HTTP GET/prestop 路径,扩展开发者负责实现相应逻辑以确保完成实例释放前的必要操作,如等待数据库链接关闭,以及上报、更新状态等,如图所示。
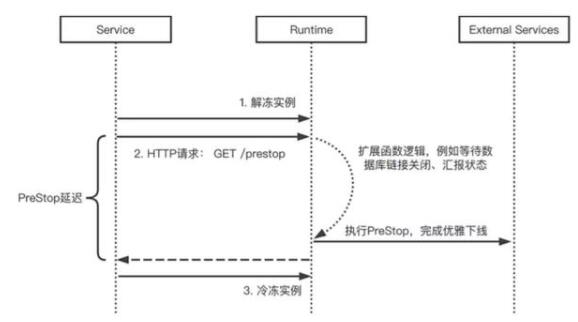
PreStope 时序图
2.单实例多并发
众所周知,各云厂商的函数计算通常是请求级别的隔离,即当客户端同时发起 3 个请求到函数计算,理论上会产生 3 个实例进行应对,这个时候可能会涉及冷启动以及请求之间状态关联等问题。因此,部分云厂商提供了单实例多并发的能力(例如阿里云函数计算)。该能力允许用户为函数设置一个实例并发度 (InstanceConcurrency) ,即单个函数实例可以同时处理多个请求,如图所示。
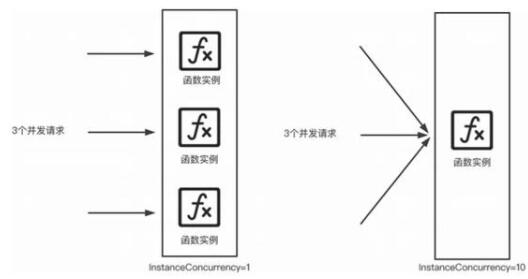
单实例多并发效果简图
如上图所示,假设同时有 3 个请求需要处理,当实例并发度设置为 1 时,函数计算需要创建 3 个实例来处理这 3 个请求,每个实例分别处理 1 个请求;当实例并发度设置为 10 时(即1个实例可以同时处理 10 个请求),函数计算只需要创建 1 个实例就能处理这 3 个请求。
单实例多并发的优势如下。
减少执行时长,节省费用。例如,偏 I/O 函数可以在一个实例内并发处理请求,减少了实例数,从而减少总的执行时长。
请求之间可以共享状态。多个请求可以在一个实例内共用数据库连接池,从而减少和数据库之间的连接数。
降低冷启动概率。由于多个请求可以在一个实例内处理,创建新实例的次数会减少,冷启动概率降低。
减少占用 VPC IP。在相同负载下,单实例多并发可以降低总的实例数,从而减少 VPC IP 的占用。
单实例多并发的应用场景比较广泛,例如函数中有较多时间在等待下游服务响应的场景就比较适合使用该功能。单实例多并发也有不适合应用的场景,例如函数中有共享状态且不能并发访问时,单个请求的执行要消耗大量 CPU 及内存资源,这时就不适合使用单实例多并发功能。