本文转载自微信公众号「有关SQL」,作者 Lenis。转载本文请联系有关SQL公众号。
上千行的 SQL 代码常见,且永不过时!
经历了大大小小的 MIS 系统,小到几人用的协作系统,几十人用的 OA 系统,到上千人用的 MES/ERP 系统,再到百万人用的电商系统,存储过程的影子在半个世纪(20世纪70年代末开始)以来从未淡出它的战场。我们几个 SQL 老玩家经常自吹, SQL 是半衰期最长的编程语言。玩会它不用担心失业。
我之前写过如何去阅读和拆解一个上千行的 SQL 存储过程,详情可见以下两篇文章:
- 如何提高阅读 SQL 源代码的快感
- 如何写好上千行的 SQL 存储过程(附代码规范)
这两文中提到了四大步骤:理解代码,分拆代码,改写代码和保存代码。拆过无数的代码,从上千行缩减到 2 成,也组装过无数的代码,从上百行塞成了上千行,业务所需。见过最长的 SQL 代码超 5000 行,已简无所简,那就实事求是了。人有分分合合,有生命力的代码也一样。
但装和拆并不是一个逆反的过程!
就像我们能读懂村上春树的小说《且听风吟》、《刺杀骑士团长》一样,但我们无法写出来或者说无法写的那么好。当然那毕竟是村上赖以为生的技能,老人家写了30多年的小说,我们可能一部都没完整的写完过,没法儿比。既然如此,在我们赖以为生的SQL阵营,这门吃饭的技能一定是要好好磨练的。
下面的领悟来自我实战中真实的想法,趟过无数次的坑,用教训总结出来的几条自认为极有用的经验。
- 理解业务
- 快速实现
- 重构与测试
- 版本控制
- 复盘记录
1.理解业务
你肯定不会去写没有业务逻辑的代码。充分理解业务逻辑对你有两个好处:一是写出可执行的并且可扩展的代码;二是主动了解业务将有利于职业生涯升级。
第一个好处不言而喻,写代码写出颈椎病的程序员,肯定意识到代码的扩展性,可以节省去医院的时间,可以霸屏更多次王者。
举例说说什么是代码的扩展性?
比如产品的价格。电商时代,产品的价格拥有明显的扩展属性。也就是说,今天是这个价,明天又是另一个价。电商时代给双11,双12附上了商业促销标签,对产品价格提出了高要求。此时,你去设定一个商品价格,你会怎么设计?是在原来的价格基础上直接更新,还是另起一列,承载新价格?这类价格设计,会直接影响对电商促销活动的成果分析。
如果我们直接更新价格,就会失去与历史销售对比的便捷,如果不随单记录单价,更是丢失了与历史的对比。从设计角度,这很失败,失去了灵活性,扩展性。这样的设计,每次更换价格,都需要大量更新产品价格表和销售历史表,对已有的商业活动造成干扰。更好的办法是,增加价格的有效使用日期。比如在这段时间内这个价格生效,在促销阶段又是另一个价格。并采用视图(view)的方式去提供产品数据,而不是直接从原表直接读取数据,失去中间业务的缓冲。
对这类业务的理解,kimball 最有说服力,他的《Dimensional modeling》(《维度建模》)总结了几十个行业的通用设计模型,堪称数据模型界的设计模式。
第二个好处可不是人人都能意识到了。虽然 SQL 是拥有最长职业生涯的编程语言,比如与其一起出现的 VFP 大概 90 后闻所未闻,但显然没人一辈子愿意鼓捣 CRUD 。玩吃鸡的同学把你的 iPhone 13 放下,家里有矿没说你。理解业务使你成为整个应用生态中不可缺少的一环。信息化的目的不是写代码,最终落脚点还是利润。我觉得二爷(邱岳)肯定能赞同我这话。
话说到这份上,大家可以明白,我们写SQL就是在通晓一个行业的数据流,资金流,做好大盘的监控。那么还有谁比我们更了解一个企业的真实经营情况呢,没有,完全没有。前提是,你要做对,要通晓。当你还只是把自己定位成一个码工,那真是大材小用。追逐SQL的技巧可以,但最终还是商业会支持你走的更远。你永远不可能20岁,30岁,总有一天你会被希望拥有开拓事业的本领,拥有可以指导后生的经验。到那时,技术经验就很泛泛了。甚至有可能技能上完全不如年轻人。唯一能给你树立权威的,还在于你在其他方向上能够走的多远。
2.快速实现
很多朋友(包括我)有时候碰到需求,苦思冥想,要的是一口气把 SQL 从头到尾完整的,畅快淋漓的写出来。“Wow” 和漂亮的回车,就是憋着这口气的期待。
但现实无数次打了我的脸!
越是有这种想法,越是憋得时间很长才写那么一点。总觉得这里不好,那里不行,这里的变量名称写得不够爽朗,那边的 Pivot 写得不够优化。结果往往是一个上午就在那里纠结,什么都没完成。
你是不是也有类似的经历?不孤独
村上春树、海明威、博尔赫斯,从来写小说都是第一遍爽快的写下去了,一旦写得卡壳了怎么办,束之高阁,明儿继续。我这里想说的策略,大家都可以猜得到了。先把业务实现了再说,命名规则,变量申明,事务控制以及性能优化,统统先放起来。写好 CRUD 交上第一稿,存档,Over!
作家们要是等灵感来了再动笔写,我们哪能看到那么多有趣的故事。同样,我们写代码哪能等到全盘都考虑好了再动手呢。想到一个数据流,用到哪些表,直接就可以写了。等着等着就慌了,写着写着思路就来了。
比如实现下面的CRUD,你会花多少时间?
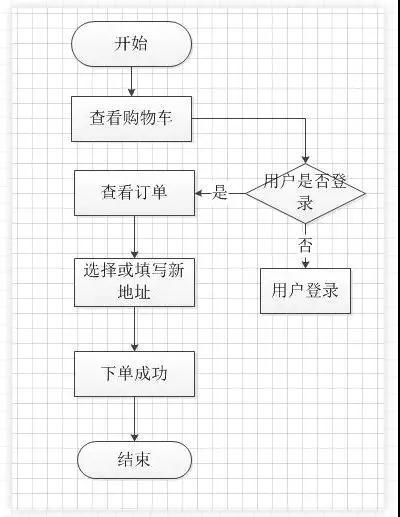
如果一开始,盯着这图你开始考虑日志怎么记,检查用户是否单点登录,用户是否用促销券,订单怎么撤回,要不要控制并发,那么无疑是给自己加了很多戏,很多无形的压力使得你自己无法动手做,越想越宏大,越觉得自己做不来。在你迷茫同时,如果有个会议,有个热闹的新闻,一开小差,再想回到你的宏伟蓝图上来,就难了。
怎么办?抓大放小
此时,你要做的第一件事,就是快速去实现这么几个关键点的CRUD代码。比如购物车的增删改查,用户登录,填写订单信息,还有结单。等到这一系列操作都完成,你对整个业务流,数据流都熟悉了,第二遍再去增加附加的功能。
3.重构与测试
终于,在第一版本时,你增加好了附加功能。实现了绝大多数的业务功能。
那这个时候,是不是可以交稿,checkin你的代码了呢?并不是!
如果此时你就认为高枕无忧,那会死的很惨。你会成为别人口中的“猪一样的队友,坑货……”
《巴黎评论》中,村上春树提到他的小说经常修改 4 - 5 遍才交稿,而且编辑还需要修改。我们一遍过的 SQL 就免检了?这个时候才考验你 SQL 真实功底和编码素质。
再检查命名规则,变量申明,事务控制以及性能优化。你会发现还有很多事情要做。
比如原本有很多次的嵌套
我知道很多朋友会这么写 :
- SELECT * FROM ( SELECT * FROM (SELECT * FROM BASE ) T1 )T2
如果继续放任你的项目里存在这样的代码,那项目很快就失控了。
至少,第一遍走读代码,我们需要完成格式上的美化:
- SELECT * FROM
- ( SELECT *
- FROM (
- SELECT * FROM BASE
- ) T1
- )T2
这样即使代码不够优雅,别人在阅读这块代码时,也不至于骂娘。
第二遍动手重构的时候,可以考虑减少嵌套,或加上 CTE 封装嵌套:
- ; WITH BASE_TABLE AS ( SELECT * FROM BASE )
- SELECT * FROM BASE_TABLE
再比如,unpivot 之后的聚合:
一开始我们能把 unpivot 写出来就很好了,然后嵌套一层做聚合,如下:
- SELECT Convert(Date,OrderDate) as OrderDate
- , Sum(Amount) AS Amount
- FROM (
- SELECT
- OrderDate,
- Unp.Amount AS Amount
- FROM FctOrderAmounts
- UNPIVOT( Amount for Type in(Shipment,UnitCost) ) Unp
- ) RSL
- GROUP BY Convert(Date,OrderDate)
这么一看特别清晰,但是信息量大,结构复杂,加上中间可能有其他字段或者Join,变得复杂,那我们至少还需再一次简化:
- SELECT
- OrderDate,
- Sum(Unp.Amount) AS Amount
- FROM FctOrderAmounts
- UNPIVOT( Amount for Type in(Shipment,UnitCost) ) Unp
- Group by Unp.Amount
再好比,有很多的关键步骤,其实我们可以拆分开来,直到一个存储过程完成一个功能,这样既完成代码简化,还可以提供复用的接口,还可以使得组里的小伙伴协同作战。一举三得,这样的事情才值得花时间。
最后,将所有的测试分支跑完测试,提交!
4.版本控制
如果你的团队没有 git, SVN, TFS 这些 Source Code Version Control, 赶紧上一个。没有自动化部署工具,自己想办法整一个。都 2021 年了,别偷懒吧。
为什么一定要版本控制呢?这,应该在刚入门编程的时候就知道。
好比你觉得越发讨厌现在的自己,或是太胖,或是太文弱,或是太没文化,好想要一台时光穿梭机,回到15,16岁,重新再来。你会告诉自己多吃蔬菜和水果,坚持每天锻炼,坚持每天看书写字读报。
虽然我们不能实现穿越,但代码可以。使用上述提到的软件,就可以帮助我们回退到想要重新开始的那个版本,修正代码。
5.复盘记录
做好上面4步,对公司项目是有个交代了。但做这一步,才是对自己有交代。
就好比刚才重构的时候,提到 CTE, UNPIVOT , 代码简化的策略,可能因为一时灵感或责任心爆棚,反正你当时想到了,但你不及时记录下来,可能很久过后就忘记你曾做过这么神奇的操作。
所以,等你费尽心思写完很长的代码,一定要通过复盘记录下来,放到你的 blog, github, 等你以后碰到类似情况,却想不出来如何解,你可以随时拿出来用上。
我复盘过很多这样的代码例子,关注微信公众号【有关SQL】,回复【5000】,就可以看到这些真实的源代码。
写好SQL代码,素质当然远不止这些!
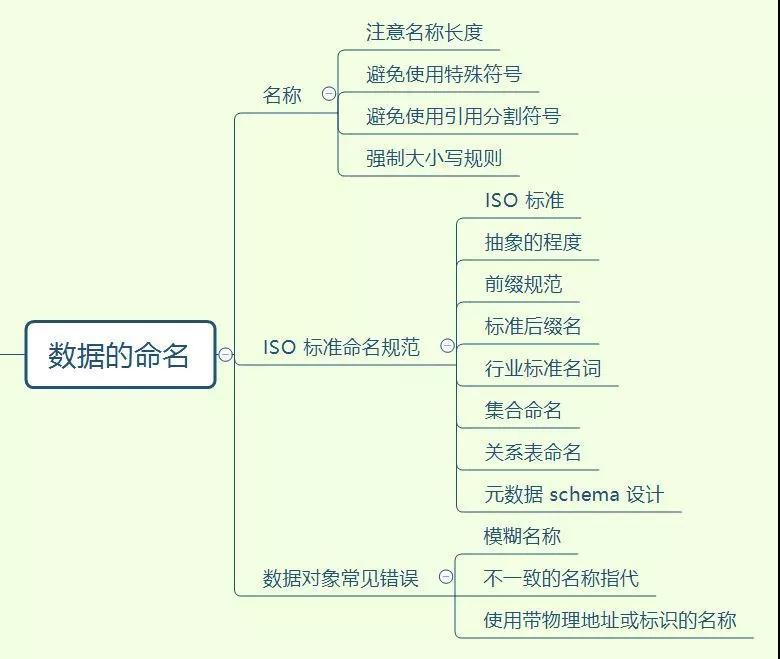
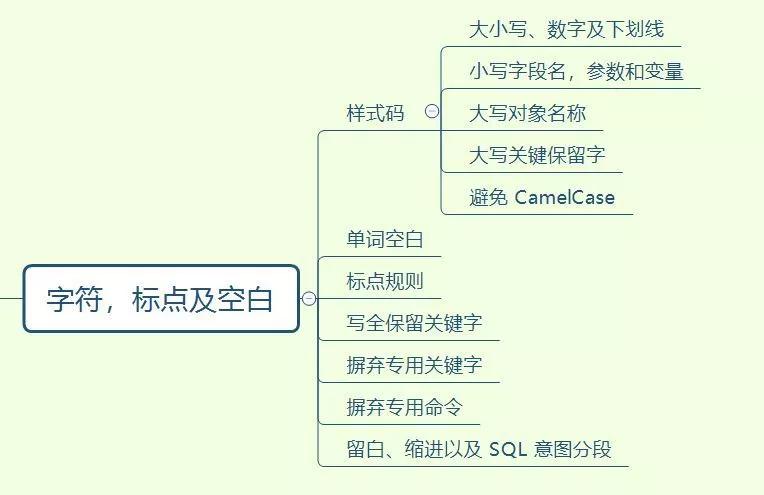
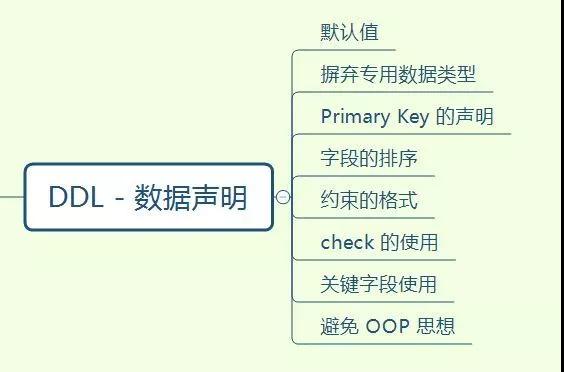
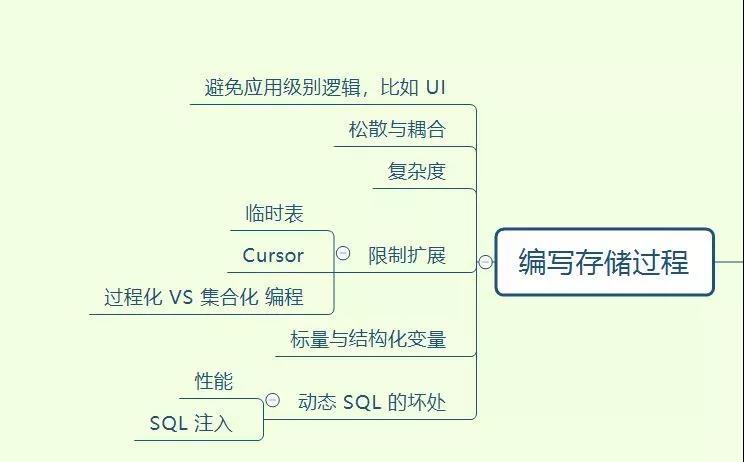
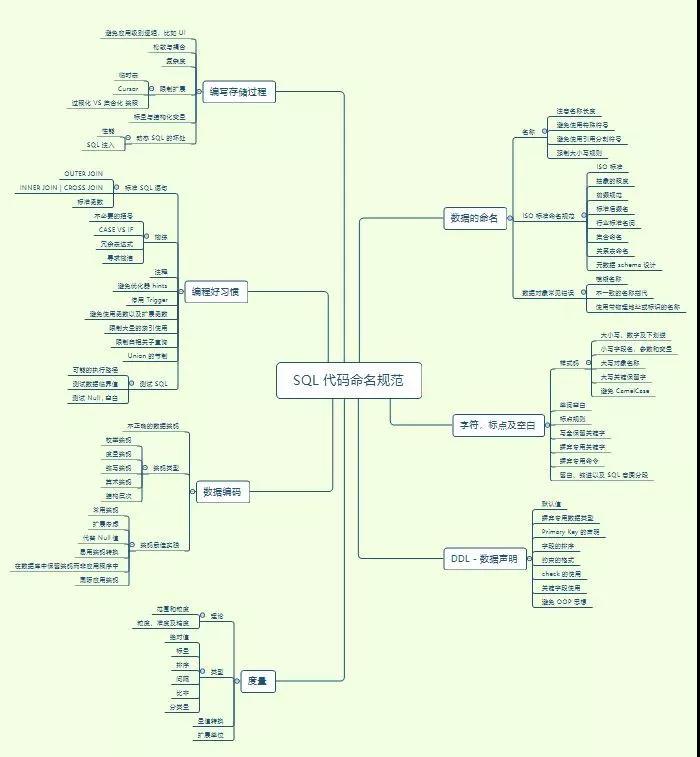
分享一个最近做的脑图,掌握了这些才可以说 SQL 编码入门了
摸着你的良心,看看这个图,有则改良,无则加勉
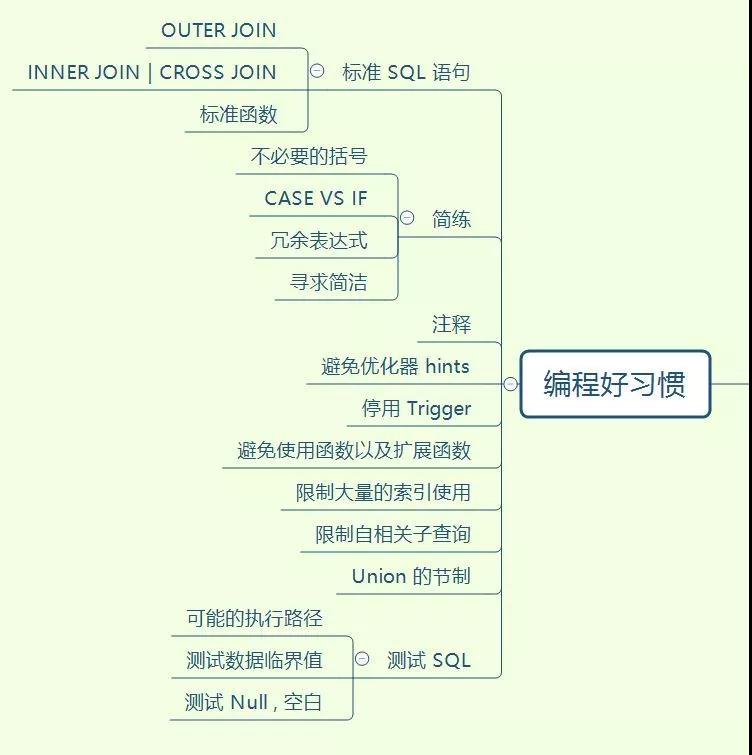
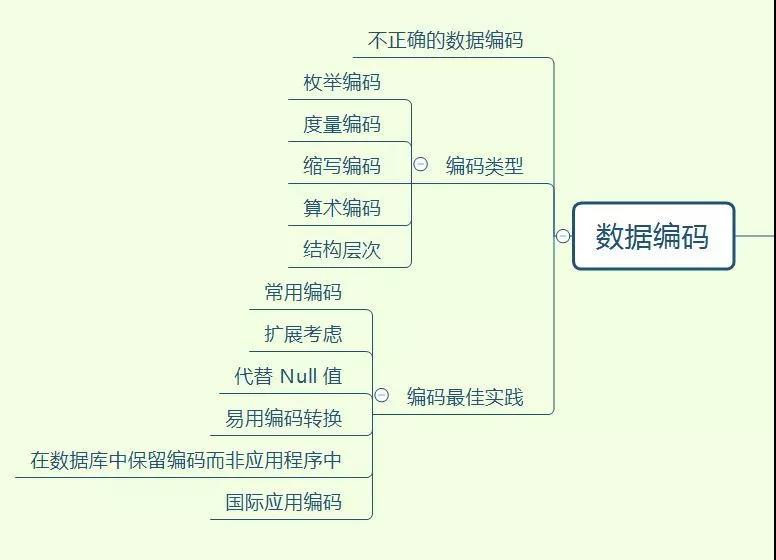
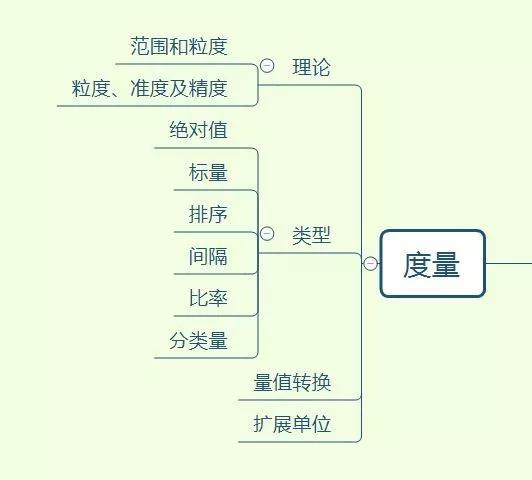
上面都是个人实战所学,所悟。鉴于本人技术水平和经验,还有表达能力有限,难免有些地方写得晦涩,有些地方深入不够,希望大家能够给予反馈,感谢!