












介绍
在很多业务系统中,我们经常会遇到生成全局唯一的分布式ID的需求,如IM系统,订单系统等。那么生成全局唯一的分布式ID的方法有哪些呢?
UUID
- // 3eece1c6-5b57-4bce-a306-6c49e44a1f90
- UUID.randomUUID().toString()
「本地生成,生成速度快,但识别性差,没有顺序性」
可以用来标识图片等,不能用作数据库主键
数据库自增主键
「我们原来刚开始做IM系统的时候就单独建了一个表来获取自增id作为消息的ID」,单独开一张表来获取自增id也不会影响对消息分库分表
Zookeeper
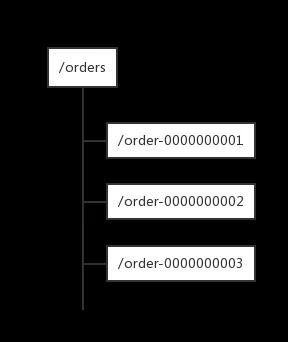
「每次要生成一个新Id时,创建一个持久顺序节点,创建操作返回的节点序号,即为新Id,然后把比自己节点小的删除即可」
这种方式能生成的Id比较少,因为数字位数比较少
Redis
「用incr命令即可实现」
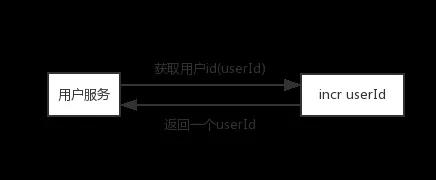
设置一个key为userId,值为0,每次获取userId的时候,对userId加1再获取
- set userId 0
- incr usrId //返回1
每获取一次id都会和redis有一个网络交互的过程,因此可以改进为如下形式
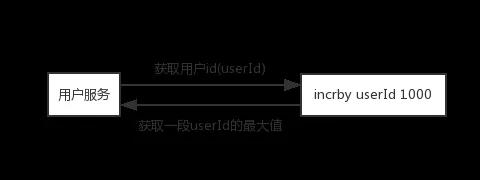
直接获取一段userId的最大值,缓存到本地慢慢累加,快到了userId的最大值时,再去获取一段,一个用户服务宕机了,也顶多一小段userId没有用到
- set userId 0
- incr usrId //返回1
- incrby userId 1000 //返回10001
雪花算法
「雪花算法是最常见的解决方案,满足全局唯一,趋势递增,因此可以用来作为数据库主键」
雪花算法是由Twitter公布的分布式主键生成算法,它能够保证不同进程主键的不重复性,以及相同进程主键的有序性。
在同一个进程中,它首先是通过时间位保证不重复,如果时间相同则是通过序列位保证。同时由于时间位是单调递增的,且各个服务器如果大体做了时间同步,那么生成的主键在分布式环境可以认为是总体有序的,这就保证了对索引字段的插入的高效性。例如MySQL的Innodb存储引擎的主键。
使用雪花算法生成的主键,二进制表示形式包含4部分,从高位到低位分表为:1bit符号位、41bit时间戳位、10bit工作进程位以及12bit序列号位。
「符号位(1bit)」
预留的符号位,恒为零。
「时间戳位(41bit)」
41位的时间戳可以容纳的毫秒数是2的41次幂,一年所使用的毫秒数是:365 * 24 * 60 * 60 * 1000。通过计算可知:
- Math.pow(2, 41) / (365 * 24 * 60 * 60 * 1000L);
结果约等于69.73年。ShardingSphere的雪花算法的时间纪元从2016年11月1日零点开始,可以使用到2086年,相信能满足绝大部分系统的要求。
「工作进程位(10bit)」
该标志在Java进程内是唯一的,如果是分布式应用部署应保证每个工作进程的id是不同的。该值默认为0,可通过属性设置。
「一般情况这10bit会拆分为2个5bit」
前5个bit代表机房id,最多代表 2 ^ 5 个机房(32 个机房) 后5个bit代表机器id,每个机房里可以代表 2 ^ 5 个机器(32 台机器)
「因此这个服务最多可以部署在 2^10 台机器上,也就是1024台机器」
「序列号位(12bit)」
该序列是用来在同一个毫秒内生成不同的ID。如果在这个毫秒内生成的数量超过4096(2的12次幂),那么生成器会等待到下个毫秒继续生成。

理解了实现思路,我们来把算法实现一遍
- public class SnowFlake {
- /**
- * 起始的时间戳
- */
- private final static long START_STMP = 1480166465631L;
- /**
- * 每一部分占用的位数
- */
- private final static long SEQUENCE_BIT = 12; //序列号占用的位数
- private final static long MACHINE_BIT = 5; //机器标识占用的位数
- private final static long DATACENTER_BIT = 5;//数据中心占用的位数
- /**
- * 每一部分的最大值
- */
- private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
- private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
- private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
- /**
- * 每一部分向左的位移
- */
- private final static long MACHINE_LEFT = SEQUENCE_BIT;
- private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
- private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
- private long datacenterId; //数据中心
- private long machineId; //机器标识
- private long sequence = 0L; //序列号
- private long lastStmp = -1L;//上一次时间戳
- public SnowFlake(long datacenterId, long machineId) {
- if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {
- throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");
- }
- if (machineId > MAX_MACHINE_NUM || machineId < 0) {
- throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
- }
- this.datacenterId = datacenterId;
- this.machineId = machineId;
- }
- /**
- * 产生下一个ID
- *
- * @return
- */
- public synchronized long nextId() {
- long currStmp = getNewstmp();
- // 发生时钟回拨
- if (currStmp < lastStmp) {
- throw new RuntimeException("Clock moved backwards. Refusing to generate id");
- }
- if (currStmp == lastStmp) {
- //相同毫秒内,序列号自增
- sequence = (sequence + 1) & MAX_SEQUENCE;
- //同一毫秒的序列数已经达到最大
- if (sequence == 0L) {
- currStmp = getNextMill();
- }
- } else {
- //不同毫秒内,序列号置为0
- sequence = 0L;
- }
- lastStmp = currStmp;
- return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分
- | datacenterId << DATACENTER_LEFT //数据中心部分
- | machineId << MACHINE_LEFT //机器标识部分
- | sequence; //序列号部分
- }
- private long getNextMill() {
- long mill = getNewstmp();
- while (mill <= lastStmp) {
- mill = getNewstmp();
- }
- return mill;
- }
- private long getNewstmp() {
- return System.currentTimeMillis();
- }
- public static void main(String[] args) {
- SnowFlake snowFlake = new SnowFlake(2, 3);
- for (int i = 0; i < (1 << 12); i++) {
- System.out.println(snowFlake.nextId());
- }
- }
- }
「这端代码将workerid分为datacenterId和machineId,如果我们业务上不需要做区分的话,直接使用10位的workerid即可。」
workerid生成
我们可以通过zookeeper的有序节点保证id的全局唯一性,比如我通过以下命令创建一个永久有序节点
- # 创建一个根节点
- create /test ''
- # 创建永久有序节点
- create -s /test/ip-port- ''
- # 返回 Created /test/ip-port-0000000000
「ip和port可以为应用的ip和port,规则你来定,别重复就行」
其中/test/ip-port-0000000000中的0000000000就是我们的workerid
说一个我们原来生产环境遇到的一个workerid重复的问题,生成workid的方式那叫一个简洁
- // uid为zookeeper中的一个有序持久节点
- List<String> pidListNode = zkClient.getChildren("uid");
- String workerId = String.valueOf(pidListNode.size());
- zkClient.create("uid", new byte[0], CreateMode.PERSISTENT_SEQUENTIAL);
「你能看出来这段代码为什么会造成workid重复吗?」
它把uid子节点的数量作为workid,当2个应用同时执行到第一行代码时,子节点数量是一样的,得到的workerId就会重复。
有意思的是这段代码跑了好几年都没有问题,直到运维把应用的发版效率提高了一点,线上就开始报错了。因为刚开始应用是串行发版,后来改为并行发版
「当使用雪花算法的时候,有可能发生时钟回拨,建议使用开源的框架,如美团的Leaf。」
雪花算法在很多中间件中都被使用过,如seata用来生成全局唯一的事务id
本文转载自微信公众号「Java识堂」,作者李立敏。转载本文请联系Java识堂公众号。




















