最近机器学习 (ML) 进步的关键贡献者之一是定制加速器的开发,例如Google TPU和Edge TPU,它们显着提高了可用计算能力,从而解锁了各种功能,例如AlphaGo、RankBrain、WaveNets和对话代理。这种增加可以提高神经网络训练和推理的性能,为视觉、语言、理解和自动驾驶汽车等广泛的应用提供新的可能性。
为了保持这些进步,硬件加速器生态系统必须继续在架构设计方面进行创新,并适应快速发展的 ML 模型和应用程序。这需要对许多不同的加速器设计点进行评估,每个点不仅可以提高计算能力,还可以揭示新的能力。这些设计点通常由各种硬件和软件因素(例如,内存容量、不同级别的计算单元数量、并行性、互连网络、流水线、软件映射等)参数化。这是一项艰巨的优化任务,因为搜索空间呈指数级大1 而目标函数(例如,更低的延迟和/或更高的能源效率)通过模拟或综合进行评估在计算上是昂贵的,这使得确定可行的加速器配置具有挑战性。
在“ Apollo: Transferable Architecture Exploration ”中,我们介绍了我们在定制加速器的 ML 驱动设计方面的研究进展。虽然最近的 工作已经证明了利用 ML 来改进低级布局规划过程(其中硬件组件在空间上布局并在硅中连接)方面的有希望的结果,但在这项工作中,我们专注于将 ML 混合到高级系统规范和架构设计阶段,这是影响芯片整体性能的关键因素,其中建立了控制高级功能的设计元素。我们的研究展示了 ML 算法如何促进架构探索并建议跨一系列深度神经网络的高性能架构,其领域涵盖图像分类、对象检测、OCR和语义分割。
架构搜索空间和工作负载
架构探索的目标是为一组工作负载发现一组可行的加速器参数,以便在一组可选的用户定义下最小化所需的目标函数(例如,运行时的加权平均值)约束。然而,体系结构搜索的流形通常包含许多点,从软件到硬件没有可行的映射。其中一些设计点是先验已知的,可以通过用户将它们制定为优化约束来绕过(例如,在面积预算2约束,总内存大小不得超过预定义的限制)。然而,由于体系结构和编译器的相互作用以及搜索空间的复杂性,一些约束可能无法正确地表述到优化中,因此编译器可能无法为目标硬件找到可行的软件映射。这些不可行点在优化问题中不容易表述,并且在整个编译器通过之前通常是未知的。因此,架构探索的主要挑战之一是有效地避开不可行的点,以最少数量的周期精确架构模拟来有效探索搜索空间。
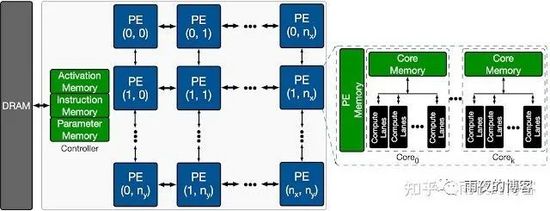
下图显示了目标 ML 加速器的整体架构搜索空间。加速器包含处理元件 (PE) 的二维阵列,每个处理元件以单指令多数据(SIMD) 方式执行一组算术计算。每个 PE 的主要架构组件是处理核心,包括用于 SIMD 操作的多个计算通道。每个 PE在其所有计算核心之间具有共享内存 ( PE Memory ),主要用于存储模型激活、部分结果和输出,而单个核心具有主要用于存储模型参数的内存。每个内核有多个计算通道,具有多路乘法累加(MAC) 单位。每个周期的模型计算结果要么存储在 PE 内存中以供进一步计算,要么卸载回 DRAM。
优化策略
在本研究中,我们在架构探索的背景下探索了四种优化策略:
1.随机:随机均匀地对架构搜索空间进行采样。
2.Vizier:使用贝叶斯优化在搜索空间中进行探索,其中目标函数的评估成本很高(例如硬件模拟,可能需要数小时才能完成)。使用来自搜索空间的一组采样点,贝叶斯优化形成一个代理函数,通常用高斯过程表示,它近似于搜索空间的流形。在代理函数值的指导下,贝叶斯优化算法在探索和开发的权衡中决定是从流形中的有希望的区域中采样更多(开发),还是从搜索空间中不可见的区域中采样更多(勘探)。然后,优化算法使用这些新采样点并进一步更新代理函数以更好地对目标搜索空间进行建模。Vizier 将预期改进作为其核心获取功能。在这里,我们使用Vizier (safe),这是一种约束优化的变体,它指导优化过程避免建议不满足给定约束的试验。
3.Evolutionary:使用k 个个体的种群 执行进化搜索,其中每个个体的基因组对应于一系列离散化的加速器配置。通过使用锦标赛选择从种群中为每个个体选择两个父母,以某种交叉率重组他们的基因组,并以某种概率突变重组的基因组,从而产生新个体。
4.基于种群的黑盒优化(P3BO):使用一组优化方法,包括进化和基于模型,已被证明可以提高样本效率和稳健性。采样数据在集成中的优化方法之间交换,优化器根据其性能历史进行加权以生成新的配置。在我们的研究中,我们使用 P3BO 的变体,其中优化器的超参数使用进化搜索动态更新。
加速器搜索空间嵌入
为了更好地可视化每个优化策略在加速器搜索空间导航中的有效性,我们使用t 分布随机邻居嵌入 (t-SNE) 将探索的配置映射到优化范围内的二维空间。所有实验的目标(奖励)定义为每个加速器区域的吞吐量(推理/秒)。在下图中,x轴和y轴表示嵌入空间的 t-SNE 组件(嵌入 1 和嵌入 2)。星形和圆形标记分别显示不可行(零奖励)和可行设计点,可行点的大小与其奖励相对应。
正如预期的那样,随机策略以均匀分布的方式搜索空间,最终在设计空间中找到很少的可行点。
与随机抽样方法相比,Vizier默认优化策略在探索搜索空间和找到具有更高奖励的设计点(1.14 对 0.96)之间取得了很好的平衡。然而,这种方法往往会陷入不可行的区域,虽然它确实找到了一些具有最大回报的点(由红十字标记表示),但它在最后一次探索迭代中几乎找不到可行的点。
另一方面,进化优化策略在优化的早期找到可行的解决方案,并在它们周围组装可行点的集群。因此,这种方法主要导航可行区域(绿色圆圈)并有效地避开不可行点。此外,进化搜索能够找到更多具有最大奖励(红色十字)的设计选项。具有高回报的解决方案的这种多样性为设计师探索具有不同设计权衡的各种架构提供了灵活性。
最后,基于群体的优化方法 (P3BO) 以更有针对性的方式(具有高奖励点的区域)探索设计空间,以找到最佳解决方案。P3BO 策略在具有更严格约束(例如,大量不可行点)的搜索空间中找到具有最高奖励的设计点,显示其在具有大量不可行点的搜索空间中导航的有效性。
不同设计约束下的架构探索
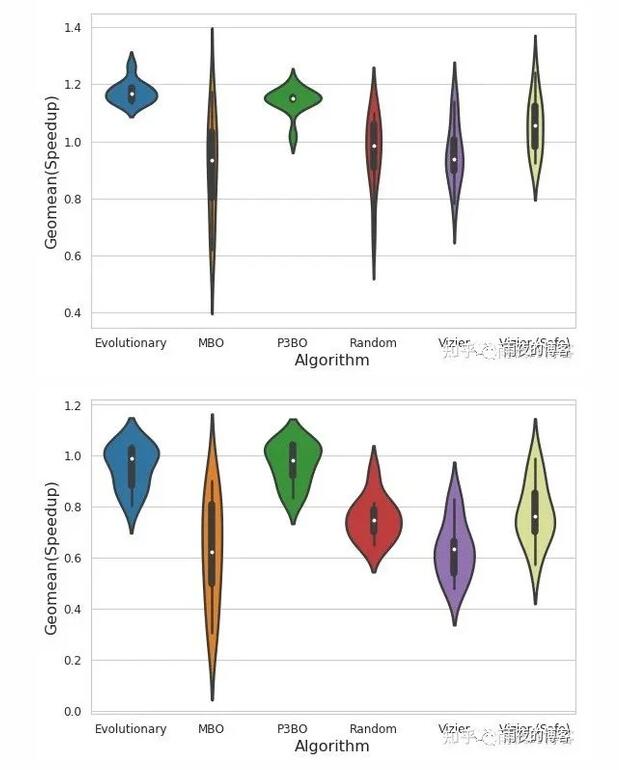
我们还研究了每种优化策略在不同面积预算约束(6.8 mm 2、5.8 mm 2和4.8 mm 2 )下的优势。以下小提琴图显示了优化结束时(每次运行 4K 次运行 10 次后)在所研究的优化策略中最大可实现奖励的完整分布。较宽的部分代表在特定给定奖励下观察可行架构配置的可能性更高。这意味着我们倾向于在具有更高奖励(更高性能)的点上产生增加宽度的优化算法。
架构探索的两个表现最佳的优化策略是进化和 P3BO,两者都提供具有高回报和跨多次运行稳健性的解决方案。查看不同的设计约束,我们观察到随着面积预算约束的收紧,P3BO 优化策略会产生更高性能的解决方案。例如,当面积预算约束设置为 5.8 mm 2 时,P3BO 发现奖励(吞吐量/加速器面积)为 1.25 的设计点优于所有其他优化策略。当面积预算约束设置为 4.8 mm 2 时,观察到相同的趋势,在多次运行中发现具有更高稳健性(更少可变性)的稍微更好的奖励。
小提琴图显示了在 6.8 mm 2的面积预算下经过 4K 试验评估后,在 10 个优化策略中运行的最大可实现奖励的完整分布。P3BO 和 Evolutionary 算法产生了更多的高性能设计(更宽的部分)。x 轴和 y 轴分别表示研究的优化算法和基准加速器上加速(奖励)的几何平均值。
结论
虽然Apollo为更好地理解加速器设计空间和构建更高效的硬件迈出了第一步,但发明具有新功能的加速器仍然是一个未知领域和新领域。我们相信,这项研究是一条令人兴奋的前进道路,可以进一步探索用于跨计算堆栈的架构设计和协同优化(例如编译器、映射和调度)的 ML 驱动技术,从而为下一代开发具有新功能的高效加速器。应用程序。