













室内环境的自监督深度估计向来比室外环境更具挑战性,OPPO提出了一种新颖的单目自监督深度估计模型:MonoIndoor,通过深度因子化模块和残差姿态估计模块,提高了室内环境中自监督单目深度估计的性能。目前,该成果已被ICCV 2021接收。ICCV是计算机视觉方向的三大顶级会议之一,今年论文接收率为25.9%。
根据单张图像估计深度信息是计算机视觉领域的经典问题,也是一项具有挑战的难题。由于单目图像的尺度不确定,传统方法无法计算深度值。
随着深度学习技术的发展,该范式已经成为了估计单目图像的深度信息的一种解决方案。早期的深度估计方法大多是有监督的,即要求数据集包含单目图像和对应的深度真值支撑网络模型训练。
要想让图像含深度真值非常困难,一般需要精密的深度测量设备和移动平台“捕获”。因此,高昂的成本导致数据集的数据量较小,也意味着有监督学习的深度估计方式不适用于大规模的工业场景。
近日,OPPO提出了一种新颖的单目自监督深度估计模型:MonoIndoor。该方法能够在训练深度网络时仅使用图像本身作为监督信息, 无需图像显式的目标深度值,在降低对训练数据集要求的同时, 提升了深度估计的适应性和鲁棒性。目前,该成果已被ICCV 2021接收,相关技术已申请专利。

论文地址:https://arxiv.org/pdf/2107.12429.pdf
具体而言,该论文研究了更具挑战性、场景更复杂的室内场景自监督深度估计,在三个公开数据集:EuRoC、NYUv2、7-Scenes上进行测试时,其性能优于Monodepth2等方法,达到了自监督深度估计领域内的最佳性能。
如何实现室内场景深度估计?
虽然对于自监督深度估计已经有了不少研究,其性能已经可以与有监督方法相媲美,但是这些自监督方法的性能评估要么只在户外进行,要么在室内表现不佳。
对于原因,OPPO研究院的研究员认为:同户外场景相比,室内场景通常缺少显著的局部或全局视觉特征。具体而言:
1. 室内场景景深变化剧烈,使得神经网络很难推演出一致的深度线索。
2. 室内场景下,相机运动通常会包含大量的旋转,从而给相机姿态网络造成困难。
基于以上观察,研究员提出两个新的模块尝试解决上述两个困难。其中,深度因子化模块(Depth Factorization)旨在克服景深剧烈变化给深度估计造成的困难;残差姿态估计模块(Residual Pose Estimation)能够提高室内场景下相机旋转的估计,进而提升深度质量。
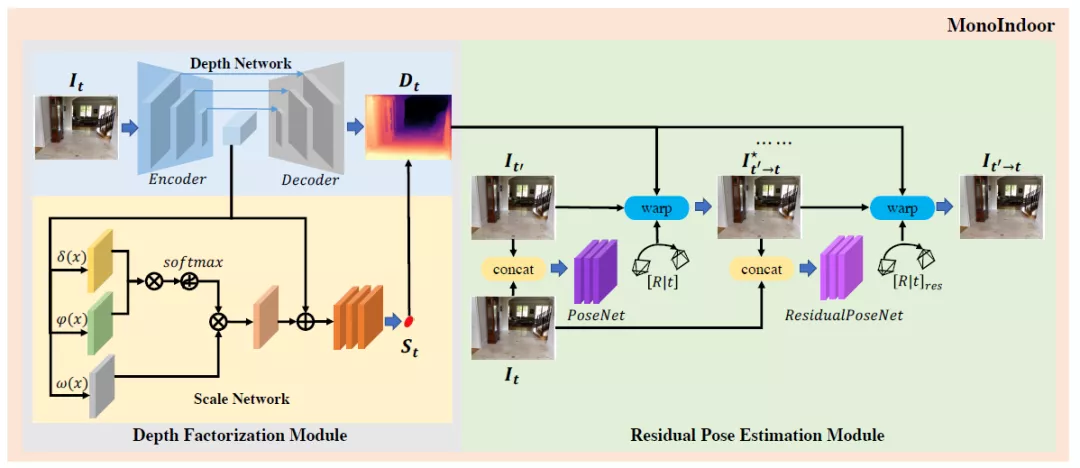
图注:MonoIndoor模型架构一览
模型工作原理如上图所示,深度因子化模块采用编解码器的深度网络来估计相对深度图,使用非局部标度网络(non-local scale network)估计全局标度因子(global scale factor);残差姿态估计模块用姿态网络估计一对帧的初始摄像机姿势,然后根据初始姿势,用残差姿态网络迭代估计残差相机姿势。
模型架构之深度因子化模块
深度因子化模块的骨干模型是Monodepth2,它的自动掩码机制可以忽略那些在单目训练中相对摄像机静止的像素;同时采用多尺度光度一致性损失,以输入分辨率执行所有图像采样,减少了深度失真。
在Monodepth2的基础上,研究员提出了自注意指导的标度回归网络(self-attention-guided scale regression network)对当前视点的全局尺度因子进行估计。
标度网络作为深度因子化模块的另一个分支,其以彩色图像为输入,全局标度因子为输出。由于全局标度因子和图像局部区域密切相关,研究员在网络中加入了自注意块,以期指导网络更多地“关注”某信息丰富的区域,从而推导出深度因子。公式如下,给定图像特征输入,输出为Query、键(key)、值(values)。
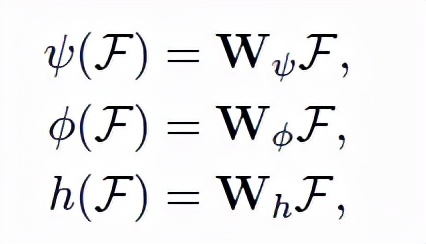
此外,为了稳定估计全局标度因子,研究员还在网络中添加了概率标度回归头(Probabilistic Scale Regression Head)。公式如下,全局标度是每一标度的加权概率求和:
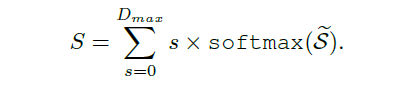
模型架构之残差姿态估计模块
与已有方法在数据预处理过程中专注于“去除”或“减少”旋转成分(rotational components)不同,OPPO研究员提出的残差姿态估计模块,可以用迭代的方式学习目标和源图像之间的相对相机姿态。
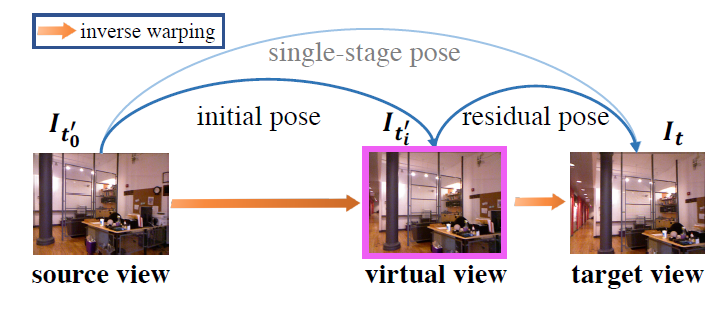
图注:一次姿态估计分解为两次姿态估计的示例
第一步:姿态网络将目标图像和源图像作为输入,并估计初始相机姿态。
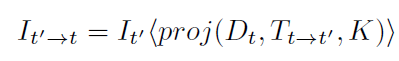
第二步:用上述公式从源图像进行双线性采样,重建一个虚拟视图。
第三步:利用残差姿态网络,将目标图像和合成视图作为输入,并输出残差相机姿态(residual camera pose)。其中,残差相机姿态指的是合成视图和目标图像之间的相机姿态。
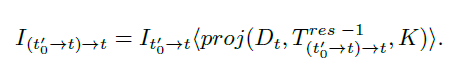
第四步,从合成图像进行双线性采样,公式如上↑。
最后,获得新合成视图之后,继续估计下一个的残差姿态。此时,双线性采样公式的一般化为↓:
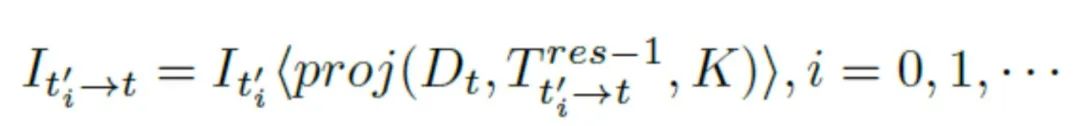
多次估计之后,残差姿态可以动态的写为↓:
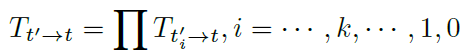
综上,通过迭代法估计残差姿态,能够获得更准确的相机姿态,更好的进行深度估计。具体实验效果如下一部分所述。
性能评估
为了说明模型MonoIndoor的效果,研究员在EuRoC MAV、NYUv2、RGBD 7-Scenes三个权威数据集上进行了评估。采用业界通用的单目深度估计量化指标:绝对相对差(AbsRel)、均方根误差(RMSE);以及三个常用的阈值thr=1.25,1.25^2,1.25^3下的准确度。
具体到实验配置,研究员使用PyTorch实现模型,每个实验用Adam优化器训练40个epochs,在前20个epochs学习率设置为10^-4,另外20个设置为10^-5;平滑项和consistency term分别设置为0.001和0.05。
实验结果之EuRoC MAV

将Monodepth2作为基线模型进行对比,结果如上表所示,深度因子化模块能够AbsRel从15.7%降低到14.9%;残差姿态估计模块将AbsRel降低到14.1%,整个模型在所有评估指标中都实现了最佳性能。

通过上图,我们可以定性的发现,MonoIndoor 做出的深度估计比Monoepth2要好得多。例如,在第一行中,MonoIndoor可以估计图片右下角的“洞区域”的精确深度,而Monoepth2显然无法估计。
实验结果之NYUv2
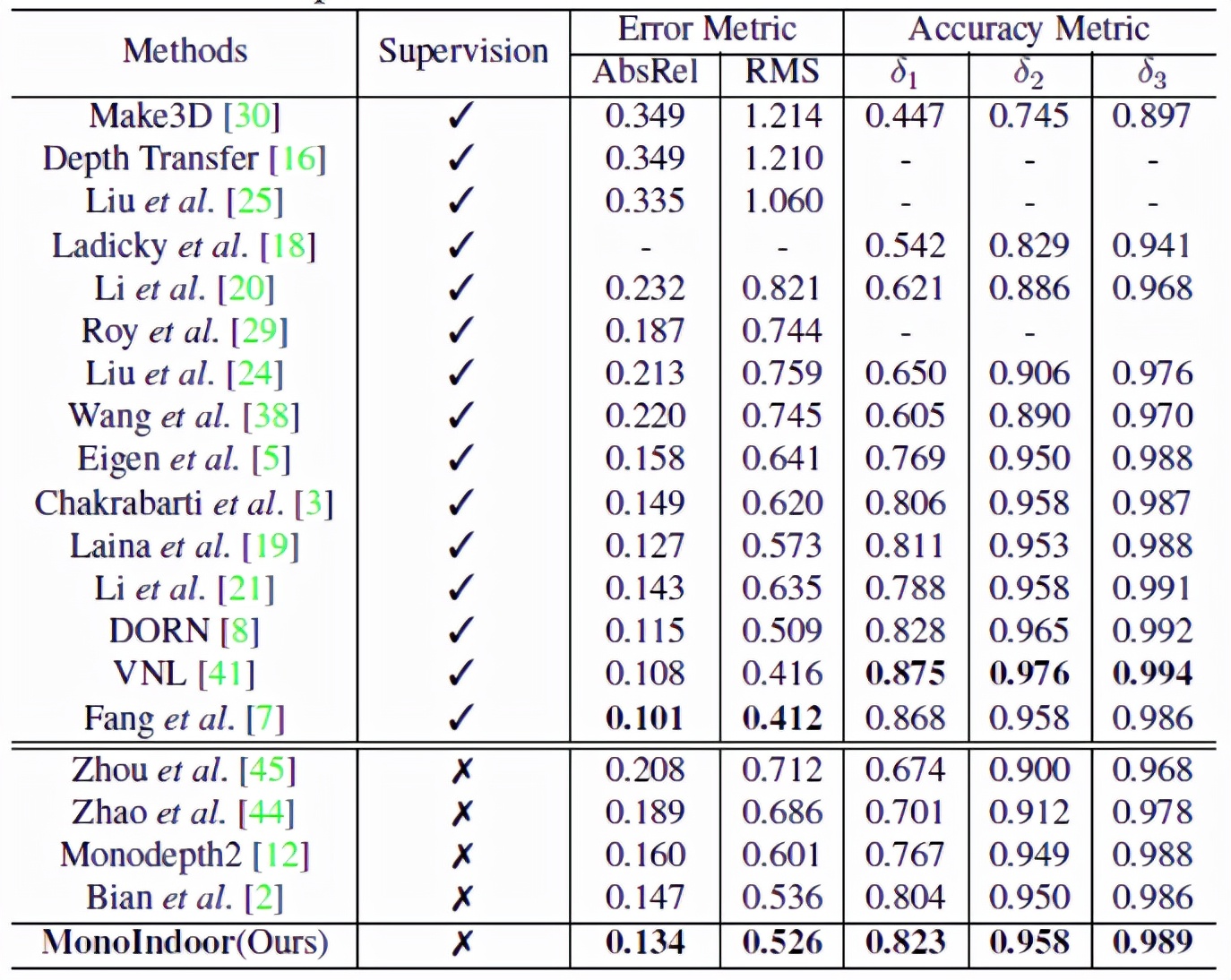
MonoIndoor 与最新的SOTA监督和自监督方法性能对比结果如上表所示,在自监督方面,能够在各项指标上达到最佳,在与有监督方法对比方面,也能够“打败”一组,从而缩小了自监督和有监督方法之间的差距。

上图可视化了NYUv2上的深度估计效果。与Monoepth2的结果相比,MonoIndoor的深度估计更加接近真实情况。例如,第一行的第三列,MonoIndoor对椅子区域的深度估计更加精准。
实验结果之RGB-D 7-Scenes
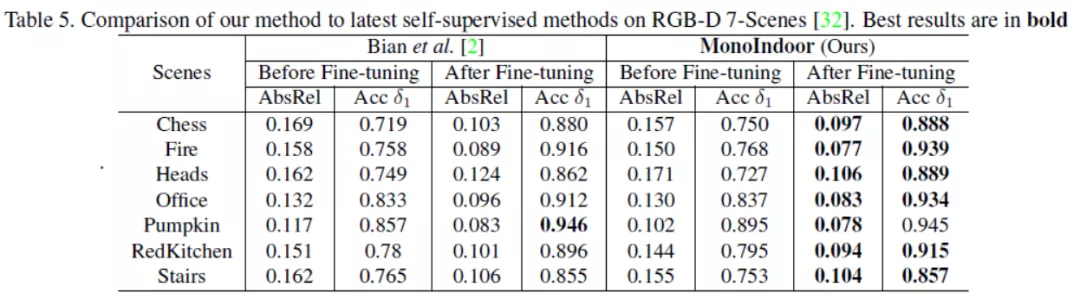
上表给出了MonoIndoor微调前与微调后在RGB-D 7-Scenes数据集上的测试结果,通过在各个场景给出的各个指标,显示了MonoIndoor更好的泛化能力和鲁棒性。例如,在场景“Fire”上,MonoIndoor减少了1.2%的AbsRel;在场景“Heads”上,MonoIndoor减少了1.8%的AbsRel。
结语
近年来,人工智能产品在各个行业迅猛发展,机器人学、三维重建、目标追踪等领域对深度估计技术的准确性和效率要求越来越高。然而目前主流的深度估计方法常由于外界环境或是成本原因,很难在工程上得以应用并达到相关需求。
另一方面,目前关于图像深度估计研究很多,可用的公共数据集却相对较少,且公共数据集中的场景相对不够丰富,大大限制了深度估计算法的泛化能力。
OPPO通过自研无监督算法,设计了适合室内场景的模型,能够在不依赖数据标注的情况下,显著提升神经网络在室内场景下的深度估计效果。这一方面体现了OPPO对人工智能应用场景的理解,也说明了它对人工智能前沿学术问题的独特把握。

























