大家好,我卡颂。
React源码内部在实现不同模块时用到了多种算法与数据机构(比如调度器使用了小顶堆)。
今天要聊的是数据缓存相关的LRU算法。内容包含四方面:
- 介绍一个React特性
- 这个特性和LRU算法的关系
- LRU算法的原理
- React中LRU的实现
可以说是从入门到实现都会讲到,所以内容比较多,建议点个赞收藏慢慢食用。
一切的起点:Suspense
在React16.6引入了Suspense和React.lazy,用来分割组件代码。
对于如下代码:
- import A from './A';
- import B from './B';
- function App() {
- return (
- <div>
- <A/>
- <B/>
- </div>
- )
- }
经由打包工具打包后生成:
chunk.js(包含A、B、App组件代码)
对于首屏渲染,如果B组件不是必需的,可以将其代码分割出去。只需要做如下修改:
- // 之前
- import B from './B';
- // 之后
- const B = React.lazy(() => import('./B'));
经由打包工具打包后生成:
- chunk.js(包含A、App组件代码)
- b.js(包含B组件代码)
这样,B组件代码会在首屏渲染时以jsonp的形式被请求,请求返回后再渲染。
为了在B请求返回之前显示占位符,需要使用Suspense:
- // 之前,省略其余代码
- return (
- <div>
- <A/>
- <B/>
- </div>
- )
- // 之后,省略其余代码
- return (
- <div>
- <A/>
- <Suspense fallback={<div>loading...</div>}>
- <B/>
- </Suspense>
- </div>
- )
B请求返回前会渲染<div>loading.。.</div>作为占位符。
可见,Suspense的作用是:
在异步内容返回前,显示占位符(fallback属性),返回后显示内容
再观察下使用Suspense后组件返回的JSX结构,会发现一个很厉害的细节:
- return (
- <div>
- <A/>
- <Suspense fallback={<div>loading...</div>}>
- <B/>
- </Suspense>
- </div>
- )
从这段JSX中完全看不出组件B是异步渲染的!
同步和异步的区别在于:
- 同步:开始 -> 结果
- 异步:开始 -> 中间态 -> 结果
Suspense可以将包裹在其中的子组件的中间态逻辑收敛到自己身上来处理(即Suspense的fallback属性),所以子组件不需要区分同步、异步。
那么,能不能将Suspense的能力从React.lazy(异步请求组件代码)推广到所有异步操作呢?
答案是可以的。
resource的大作为
React仓库是个monorepo,包含多个库(比如react、react-dom),其中有个和Suspense结合的缓存库 —— react-cache,让我们看看他的用处。
假设我们有个请求用户数据的方法fetchUser:
- const fetchUser = (id) => {
- return fetch(`xxx/user/${id}`).then(
- res => res.json()
- )
- };
经由react-cache的createResource方法包裹,他就成为一个resource(资源):
- import {unstable_createResource as createResource} from 'react-cache';
- const userResource = createResource(fetchUser);
resource配合Suspense就能以同步的方式编写异步请求数据的逻辑:
- function User({ userID }) {
- const data = userResource.read(userID);
- return (
- <div>
- <p>name: {data.name}</p>
- <p>age: {data.age}</p>
- </div>
- )
- }
可以看到,userResource.read完全是同步写法,其内部会调用fetchUser。
背后的逻辑是:
- 首次调用userResource.read,会创建一个promise(即fetchUser的返回值)
- throw promise
- React内部catch promise后,离User组件最近的祖先Suspense组件渲染fallback
- promise resolve后,User组件重新render
- 此时再调用userResource.read会返回resolve的结果(即fetchUser请求的数据),使用该数据继续render
从步骤1和步骤5可以看出,对于一个请求,userResource.read可能会调用2次,即:
- 第一次发送请求、返回promise
- 第二次返回请求到的数据
所以userResource内部需要缓存该promise的值,缓存的key就是userID:
- const data = userResource.read(userID);
由于userID是User组件的props,所以当User组件接收不同的userID时,userResource内部需要缓存不同userID对应的promise。
如果切换100个userID,就会缓存100个promise。显然我们需要一个缓存清理算法,否则缓存占用会越来越多,直至溢出。
react-cache使用的缓存清理算法就是LRU算法。
LRU原理
LRU(Least recently used,最近最少使用)算法的核心思想是:
如果数据最近被访问过,那么将来被访问的几率也更高
所以,越常被使用的数据权重越高。当需要清理数据时,总是清理最不常使用的数据。
react-cache中LRU的实现
react-cache的实现包括两部分:
- 数据的存取
- LRU算法实现
数据的存取
每个通过createResource创建的resource都有一个对应map,其中:
- 该map的key为resource.read(key)执行时传入的key
- 该map的value为resource.read(key)执行后返回的promise
在我们的userResource例子中,createResource执行后会创建map:
- const userResource = createResource(fetchUser);
userResource.read首次执行后会在该map中设置一条userID为key,promise为value的数据(被称为一个entry):
- const data = userResource.read(userID);
要获取某个entry,需要知道两样东西:
- entry对应的key
- entry所属的resource
LRU算法实现
react-cache使用「双向环状链表」实现LRU算法,包含三个操作:插入、更新、删除。
插入操作
首次执行userResource.read(userID),得到entry0(简称n0),他会和自己形成环状链表:
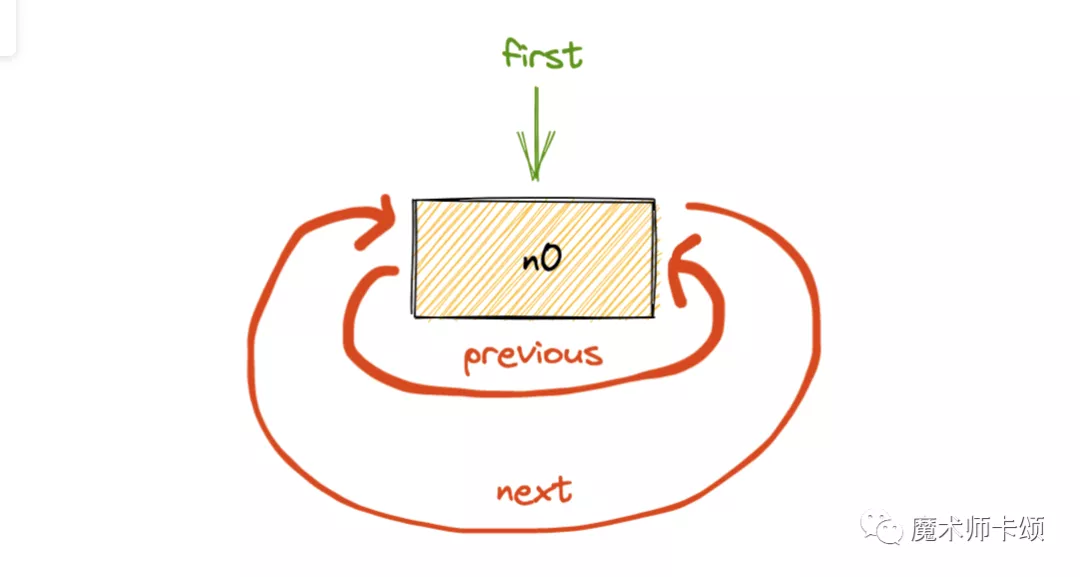
此时first(代表最高权重)指向n0。
改变userID props后,执行userResource.read(userID),得到entry1(简称n1):
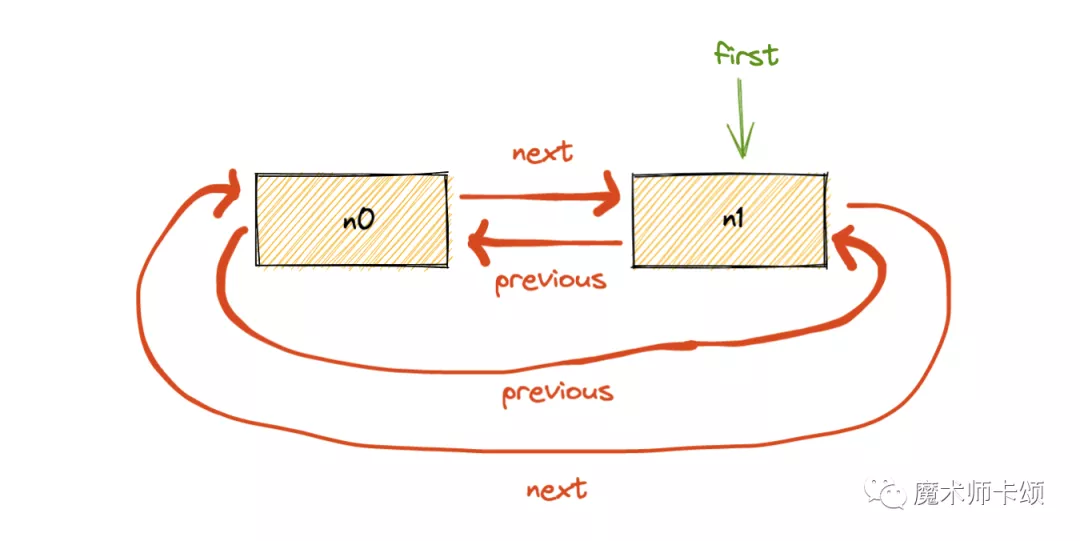
此时n0与n1形成环状链表,first指向n1。
如果再插入n2,则如下所示:
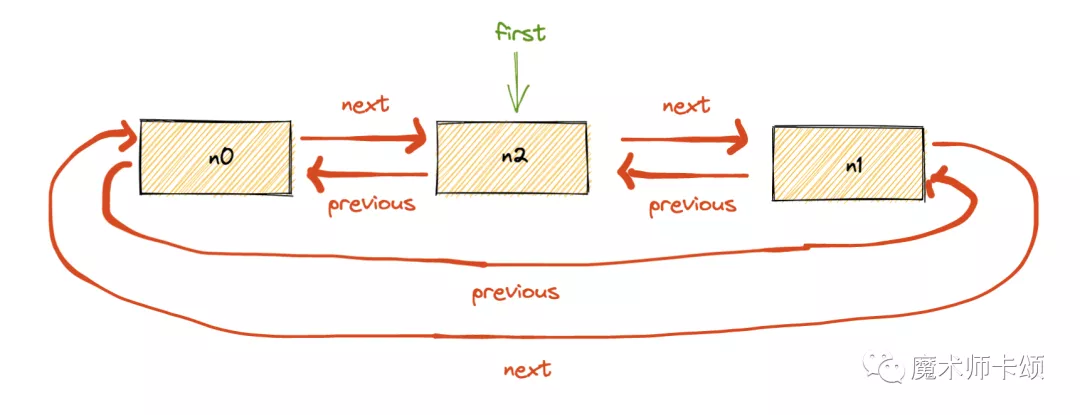
可以看到,每当加入一个新entry,first总是指向他,暗含了LRU中新的总是高权重的思想。
更新操作
每当访问一个entry时,由于他被使用,他的权重会被更新为最高。
对于如下n0 n1 n2,其中n2权重最高(first指向他):
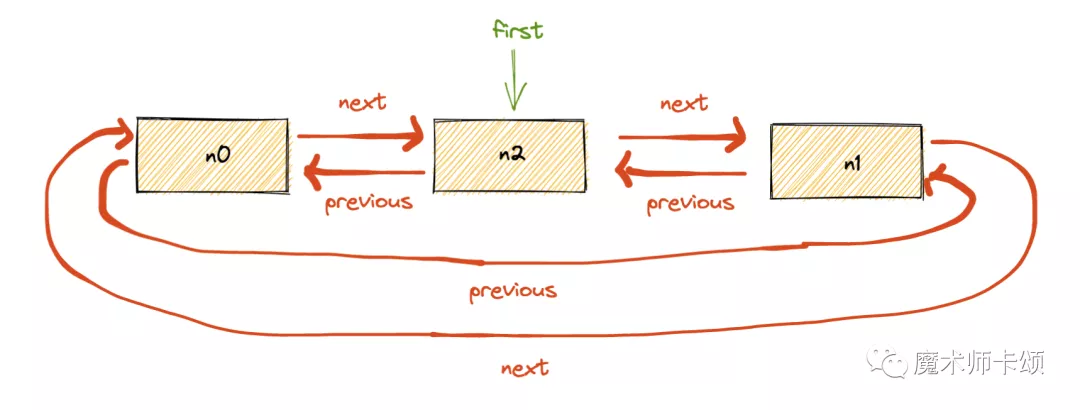
当再次访问n1时,即调用如下函数时:
- userResource.read(n1对应userID);
n1会被赋予最高权重:
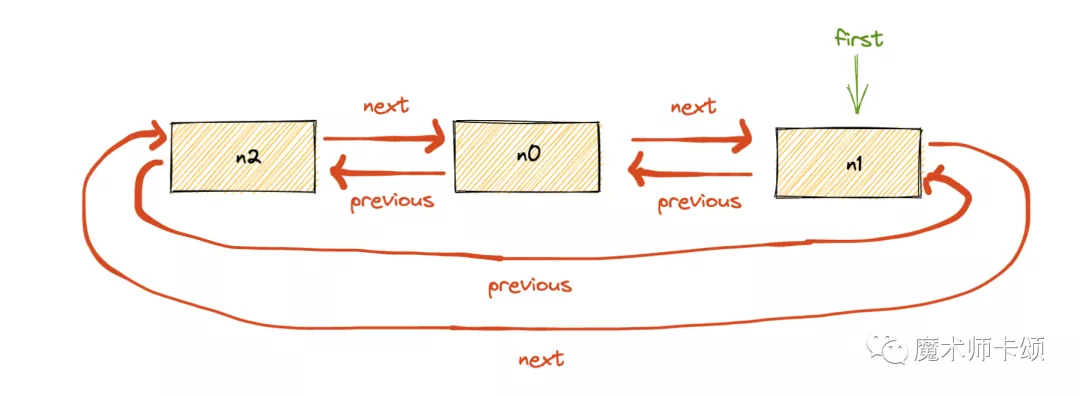
删除操作
当缓存数量超过设置的上限时,react-cache会清除权重较低的缓存。
对于如下n0 n1 n2,其中n2权重最高(first指向他):
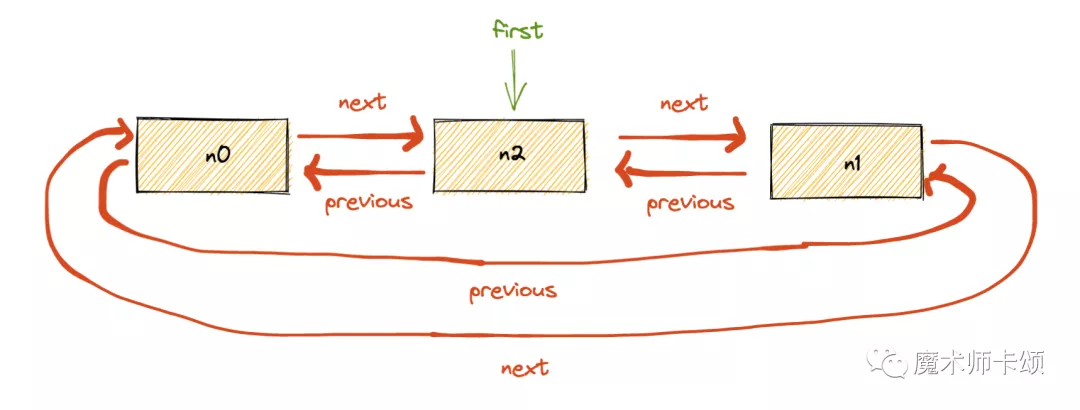
如果缓存最大限制为1(即只缓存一个entry),则会迭代清理first.previous,直到缓存数量为1。
即首先清理n0:
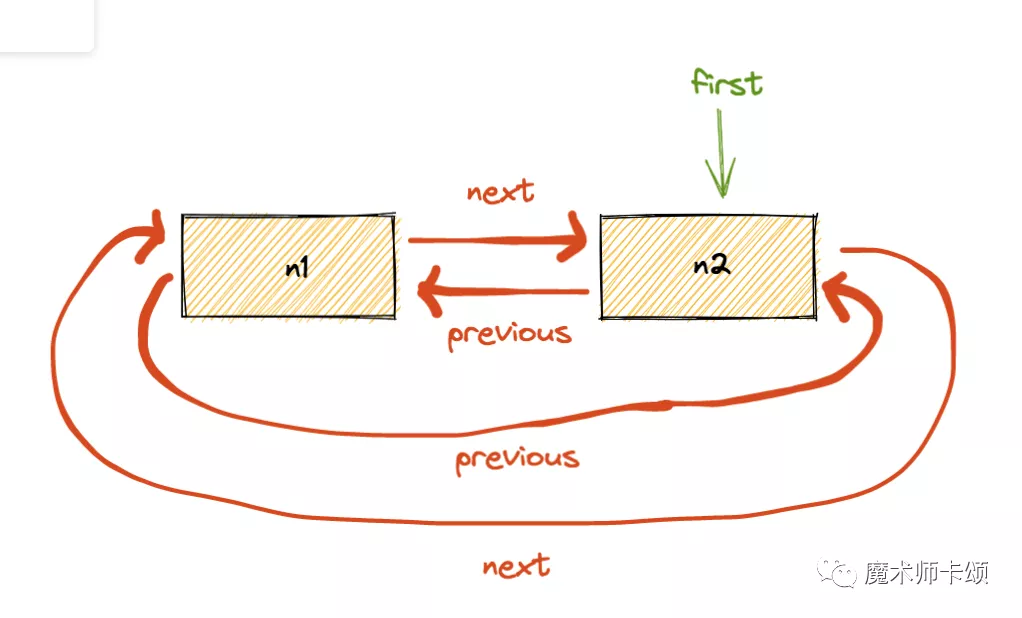
接着清理n1:
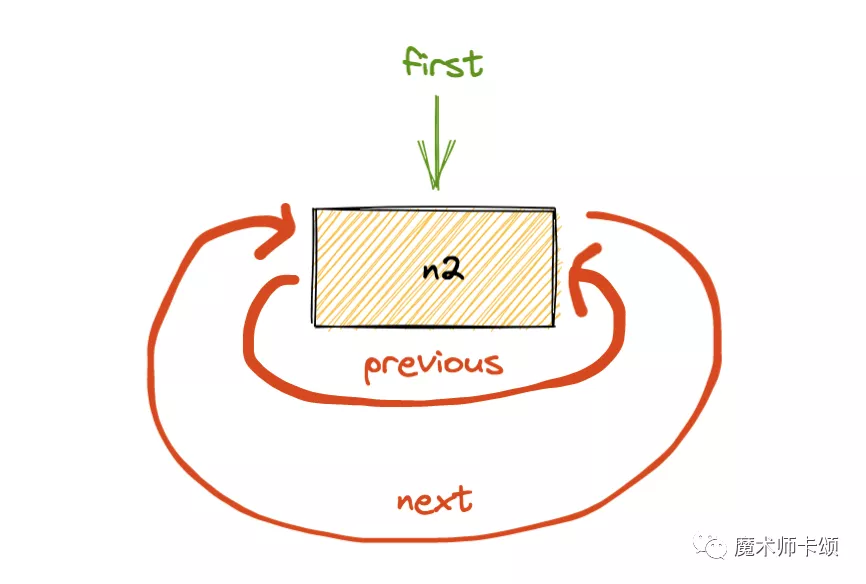
每次清理后也会将map中对应的entry删掉。
完整LRU实现见react-cache LRU
总结
除了React.lazy、react-cache能结合Suspense,只要发挥想象力,任何异步流程都可以收敛到Suspense中,比如React Server Compontnt、流式SSR。
随着底层React18在年底稳定,相信未来这种同步写法的开发模式会逐渐成为主流。
不管未来React开发出多少新奇玩意儿,底层永远是这些基础算法与数据结构。
真是朴素无华且枯燥......