












在日常数据查询时,绝大多数情况是将表格关联起来进行查询的,而不仅仅是对一张表格的数据进行查询,常用的数据拼接有两种方法,一种是以行为单位纵向连接,另一种是以列为单位横向拼接,纵向连接使用的函数是UNION,水平拼接使用的函数是JOIN,本节使用pandasql库借助SQL语句进行表格连接,下面一起来学习。
- 示例工具:anconda3.7
- 本文讲解内容:pandasql库的使用、SQL连接
- 适用范围:在Python中实现多表连接
数据表创建
本节因为案例需要,所以事先用 pandas创建3个表,数据表内容包含用户ID、日期、城市、年龄、性别等字段,三个表的共同字段都是用户ID,所以,可以作为连接的主键,使用pandas构建数据表结果如下。
构建第一张表作为基础表,以用户ID作为主键,进行连接。
- import pandas as pd
- import datetime
- #构造数据集df1
- df1 = pd.DataFrame({'用户ID':[1001,1002,1003,1004,1005,1006],
- '日期':pd.date_range(datetime.datetime(2021,3,26),periods=6),
- '城市':['北京', '上海', '广州', '上海', '杭州', '北京'],
- '年龄':[23,44,54,32,34,32],
- '性别':['F','M','M','F','F','F'],
- '成交量':[3200,1356,2133,6733,2980,3452]},
- columns =['用户ID','日期','城市','年龄','性别','成交量'])
- df1
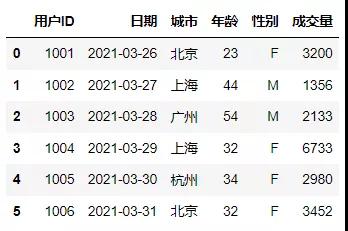
构建第二张表,用于数据表的横向连接。
- #构造数据集df2
- df2 = pd.DataFrame({'用户ID':[1007,1008,1009],
- '日期':pd.date_range(datetime.datetime(2021,3,1),periods=3),
- '城市':['北京', '上海', '广州'],
- '年龄':[33,34,34,],
- '性别':['F','M','F'],
- '成交量':[4200,3356,2633]},
- columns =['用户ID','日期','城市','年龄','性别','成交量'])
- df2
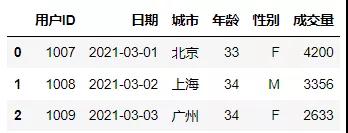
构建第三张表,以用户ID为主键,用于数据表的横向连接。
- #构造构造列名不同的df3
- df3 = pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006,1007,1008,1009,1010],
- "平台":['京东','淘宝','京东','天猫','唯品会','苏宁','天猫','淘宝','美团','拼多多'],
- "收入额":[100000,320000,240000,445000,340000,640000,300000,460000,540000,230000]},
- columns =['id','平台','收入额'])
- df3
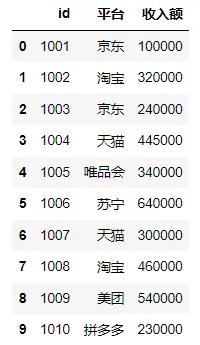
横向连接
首先是表的横向连接,顾名思义,就是在原基础表,往下一空行复制粘贴新的数据,要求两张表的列标题都是一样的,才能正常连接,这里使用UNION ALL进行连接,表示将列标题相同的两张表连接起来,如果是使用UNION连接,两张中相同的两行只会保留一行连接。
- #导入pandasql库
- import pandasql as sql
- #表的横向连接
- sql.sqldf("""select * from df1
- union all
- select * from df2""")
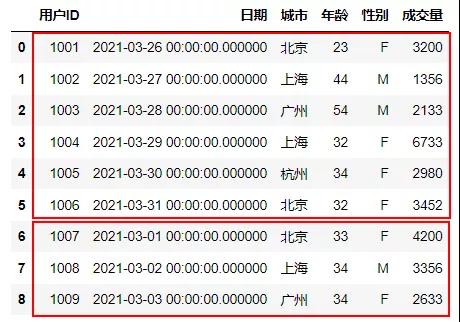
纵向连接No.1内连接
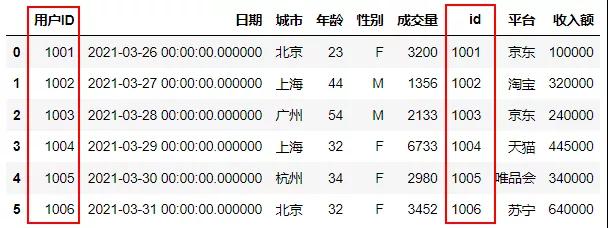
纵向连接是表格连接中使用最广泛的连接,纵向连接又可以分为内连接和外连接,内连接,连接表都匹配的记录才会出现在最终的结果集,并且连接顺序无关,这里内连接的第一种办法是使用WHERE语句,当两个表的ID相同时进行连接。
- #内连接
- sql.sqldf("""select * from df1,df3
- where df1.用户ID=df3.id;""")
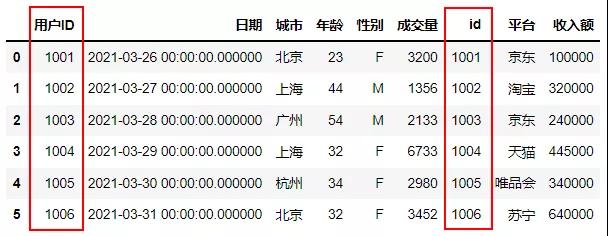
除了使用WHERE语句进行内连接,还可以使用INNER JOIN函数进行内连接,当两个表的ID相同时进行连接。
- #内连接
- sql.sqldf("""select * from df1
- inner join df3
- on df1.用户ID=df3.id;""")
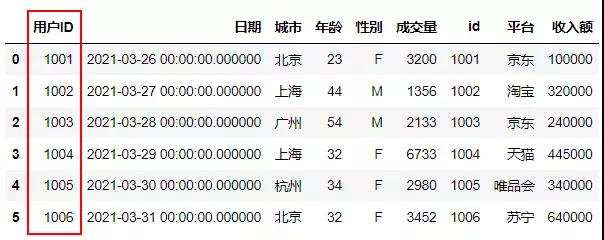
纵向连接No.2外连接
外连接以其中一张表为驱动表,与另张表的每条记录进行匹配如果能够匹配则进行关联并展示;如果不能匹配则以null展示,与连接顺序有关,这里演示的LEFT JOIN函数,当右边的表与左边的基础表的ID一致时,进行连接,类似于EXCEL函数中的VLOOKUP功能。
- #左外连接
- sql.sqldf("""select * from df1
- left join df3
- on df1.用户ID=df3.id;""")
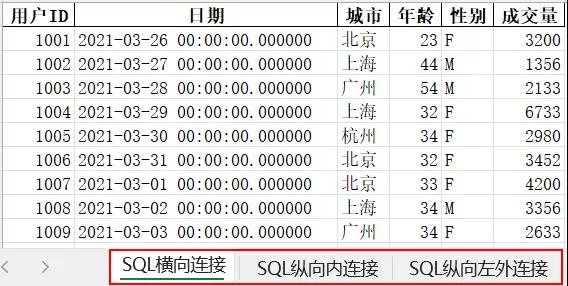
在日常工作使用左外连接的次数会很多,一般都是将多个表进行多次左外连接,这个知识点需要熟练掌握,将上面的连接结果分别赋值变量,然后导出,结果如下。
- #数据导出
- write=pd.ExcelWriter(r'C:\Users\尚天强\Desktop'+'\\SQL连接查询结果'+'.xlsx')
- sqltable1.to_excel(write,sheet_name='SQL横向连接',index=False)
- sqltable2.to_excel(write,sheet_name='SQL纵向内连接',index=False)
- sqltable3.to_excel(write,sheet_name='SQL纵向左外连接',index=False)
- write.save()
- write.close()
本文转载自微信公众号「大话数据分析」,可以通过以下二维码关注。转载本文请联系大话数据分析公众号。




















