













本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
小人不断跳跃到实时生成的平台上、最后到达终点……
你以为这是个类似于微信“跳一跳”的小游戏?

但它的真实身份,其实是游戏大厂EA(美国艺电公司)最新研究出的游戏测试AI。
和普通只会打游戏的AI不同,这次EA提出的新模型不仅要让小人成功跳到终点,还要自己实时生成平台来“为难”自己。
为什么要设计成这种“相爱相杀”的关系呢?
因为,此前的许多游戏测试AI往往会对训练中的地图过拟合,这导致它们在测试新地图时的表现很差。
由此,在强化学习的基础上,EA研究人员受到GAN的启发,提出了这种新方法ARLPCG (Adversarial Reinforcement Learning for Procedural Content Generation)。
目前,该方法的相关论文已被IEEE Conference on Games 2021接收。
用博弈论解决过拟合
其实,把AI用到游戏测试,已经不是一件新鲜事了。
此前许多游戏测试AI都用到了强化学习。
它的特点是基于环境而行动,根据从环境中获得的奖励或惩罚(比如获得积分、掉血等等)不断学习,从而制定出一套最佳的行动策略。
不过研究人员发现,强化学习对于固定场景的泛化能力很差,往往会出现过拟合的现象。
比如在同样的场景中,只用强化学习训练的情况下,小人遇到陌生路径,就会发生“集体自杀”事件:

这对于测试游戏地图哪里出现错误而言,真的非常糟糕。
为此,EA的研究人员参考了GAN的原理来设计模型,让AI内部自己对抗、优化。
具体来看,他们提出的方法ARLPCG主要由两个强化学习智能体组成。
第一个智能体生成器 (Generator)主要负责生成游戏地图,它使用了程序内容生成(Procedural Content Generation),这是一种可以自动生成游戏地图或其他元素的技术。
第二个智能体是解算器 (Solver),它负责完成生成器所创建的关卡。
其中,解算器完成关卡后会获得一定的奖励;生成器生成具有挑战性且可通过的地图时,也会获得奖励。
训练过程中,两个智能体之间会相互提供反馈,让双方都能拿到奖励。
最终生成器将学会创建各种可通过的地图,解算器也能在测试各种地图时变得更加通用。
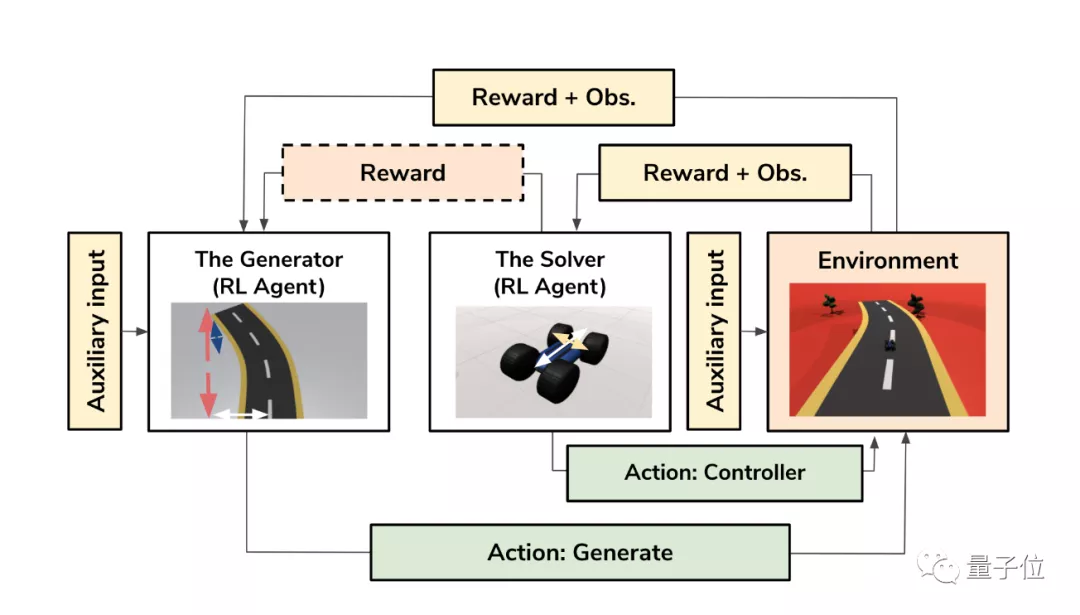
与此同时,为了能够调节关卡难度,研究人员还在模型中引入了辅助输入 (Auxiliary input)。
通过调节这个值的大小,他们就能控制游戏的通过率。
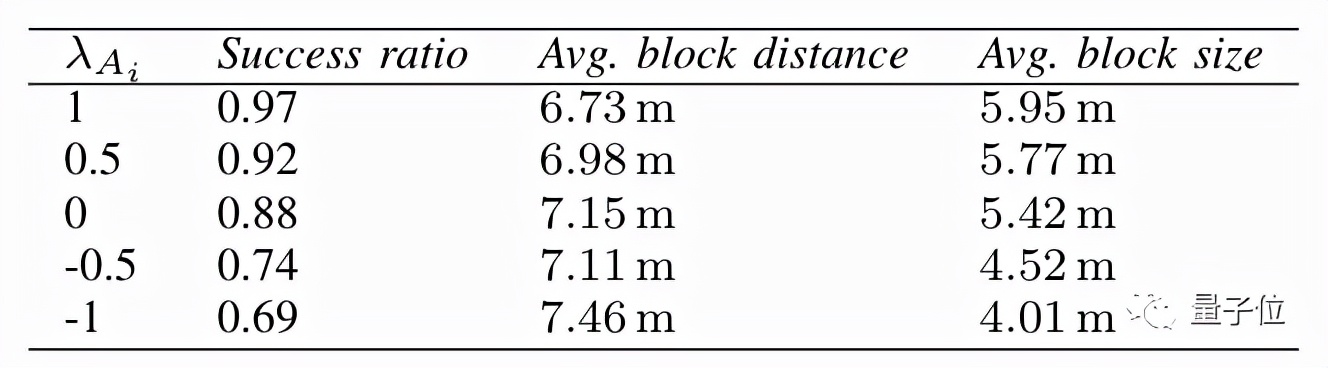
比如,将生成器的辅助输入设为1时,它生成的平台就会更大、间距更近,小人跳跃的难度也就更低。

当辅助输入为-1时,生成的平台就会变小、间距也会拉开,能够通关的小人随之变少。

结果显示,在生成器的辅助输入从1降至-1过程中,成功率从97%降低到了69%。
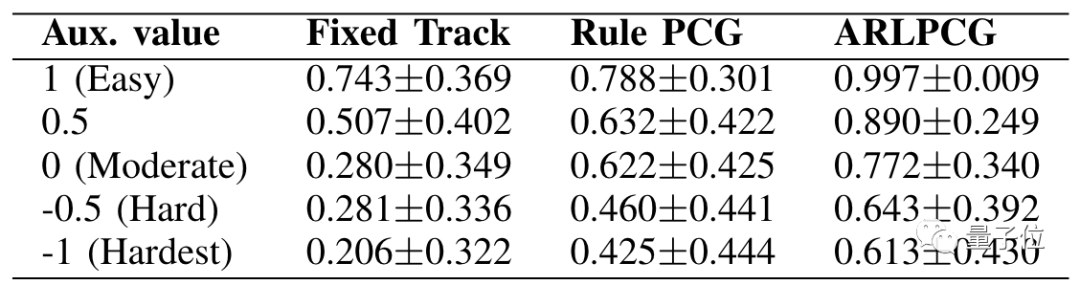
此外,也能通过调节解算器的辅助输入值控制通过率。
在固定路径、规则生成路径和对抗化生成路径几种情况下,通过率都随着辅助输入的降低而降低。
其中,对抗强化生成路径的通过率明显高于其他两种。
此外,因为具有对未知环境泛化的能力,这个AI训练好后还可以被用于实时测试。
它可以在未知路段中构建出合理的通过路线,并能反馈路径中的障碍或其他问题的位置。

此外,这个AI还能被用于不同的游戏环境,在这篇论文中,EA还展示了它在赛车游戏环境中的表现情况。

在这个场景下,生成器可以创建不同长度、坡度、转弯的路段,解算器则变成了小车在上面行驶。
如果在生成器中添加光线投射,还能在现有环境中导航。
在这种情况下,我们看到生成器在不同障碍物之间创建行驶难度低的轨道,从而让小车到达终点(图中紫色的球)。

为测试大型开放游戏
论文一作Linus Gisslén表示,开放世界游戏和实时服务类游戏是现在发展的大势所趋,当游戏中引入很多可变动的元素时,会产生的bug也就随之增多。
因此游戏测试变得非常重要。
目前常用的测试方法主要有两种:一种是用脚本自动化测试,另一种是人工测试。
脚本测试速度快,但是在复杂问题上的处理效果不好;人工测试刚好相反,虽然可以发现很多复杂的问题,但是效率很低。
而AI刚好可以把这两种方法的优点结合起来。

事实上,EA这次提出的新方法非常轻便,生成器和求解器只用了两层具有512个单元的神经网络。
Linus Gisslén解释称,这是因为具有多个技能会导致模型的训练成本非常高,所以他们尽可能让每个受过训练的智能体只会一个技能。
他们希望之后这个AI可以不断学习到新的技能,让人工测试员从无聊枯燥的普通测试中解放出来。
此外EA表示,当AI、机器学习逐渐成为整个游戏行业使用的主流技术时,EA也会有充分的准备。
论文链接:
https://arxiv.org/abs/2103.04847
参考链接:
[1]https://venturebeat.com/2021/10/07/reinforcement-learning-improves-game-testing-ai-team-finds/
[2]https://www.youtube.com/watch?v=z7q2PtVsT0I
























