自从彻底搞懂 Self_Attention 机制之后,笔者对 Transformer 模型的理解直接从地下一层上升到大气层,任督二脉呼之欲出。夜夜入睡之前,那句柔情百转的"Attention is all you need"时常在耳畔环绕,情到深处不禁拍床叫好。于是在肾上腺素的驱使下,笔者熬了一个晚上,终于实现了 Transformer 模型。
1. 模型总览
代码讲解之前,首先放出这张经典的模型架构图。下面的内容中,我会将每个模块的实现思路以及笔者在Coding过程中的感悟知无不答。没有代码基础的读者不要慌张,笔者也是最近才入门的,所写Pytorch代码没有花里胡哨,所用变量名词尽量保持与论文一致,对新手十分友好。
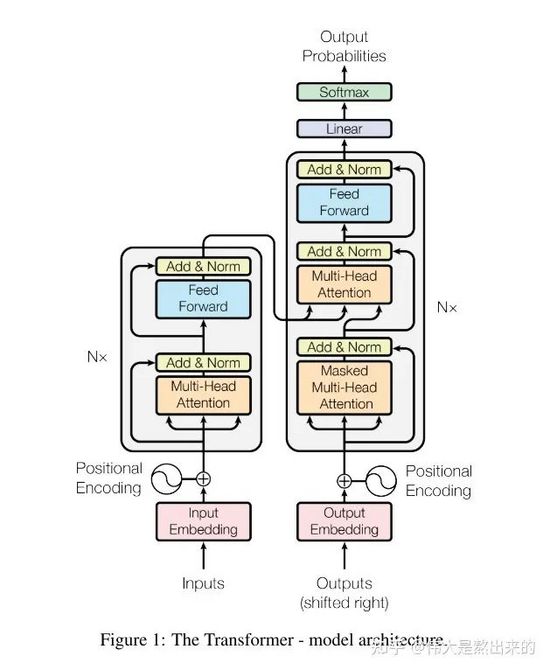
我们观察模型的结构图,Transformer模型包含哪些模块?笔者将其分为以下几个部分:
接下来我们首先逐个讲解,最后将其拼接完成模型的复现。
2. config
下面是这个Demo所用的库文件以及一些超参的信息。 单独实现一个Config类保存的原因是,方便日后复用。直接将模型部分复制,所用超参保存在新项目的Config类中即可 。这里不过多赘述。
- import torch
- import torch.nn as nn
- import numpy as np
- import math
- class Config(object):
- def __init__(self):
- self.vocab_size = 6
- self.d_model = 20
- self.n_heads = 2
- assert self.d_model % self.n_heads == 0
- dim_k = d_model % n_heads
- dim_v = d_model % n_heads
- self.padding_size = 30
- self.UNK = 5
- self.PAD = 4
- self.N = 6
- self.p = 0.1
- config = Config()
3. Embedding
Embedding部分接受原始的文本输入(batch_size*seq_len,例:[[1,3,10,5],[3,4,5],[5,3,1,1]]),叠加一个普通的Embedding层以及一个Positional Embedding层,输出最后结果。
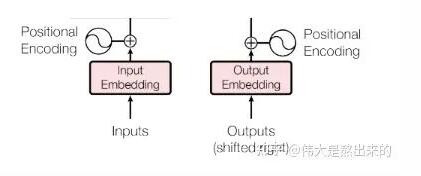
在这一层中,输入的是一个list: [batch_size * seq_len],输出的是一个tensor:[batch_size * seq_len * d_model]
普通的 Embedding 层想说两点:
- torch.nn.Embedding
- torch.nn.Embedding
- padding_idx
在padding过程中,短补长截
- class Embedding(nn.Module):
- def __init__(self,vocab_size):
- super(Embedding, self).__init__()
- # 一个普通的 embedding层,我们可以通过设置padding_idx=config.PAD 来实现论文中的 padding_mask
- self.embedding = nn.Embedding(vocab_size,config.d_model,padding_idx=config.PAD)
- def forward(self,x):
- # 根据每个句子的长度,进行padding,短补长截
- for i in range(len(x)):
- if len(x[i]) < config.padding_size:
- x[i].extend([config.UNK] * (config.padding_size - len(x[i]))) # 注意 UNK是你词表中用来表示oov的token索引,这里进行了简化,直接假设为6
- else:
- x[i] = x[i][:config.padding_size]
- x = self.embedding(torch.tensor(x)) # batch_size * seq_len * d_model
- return x
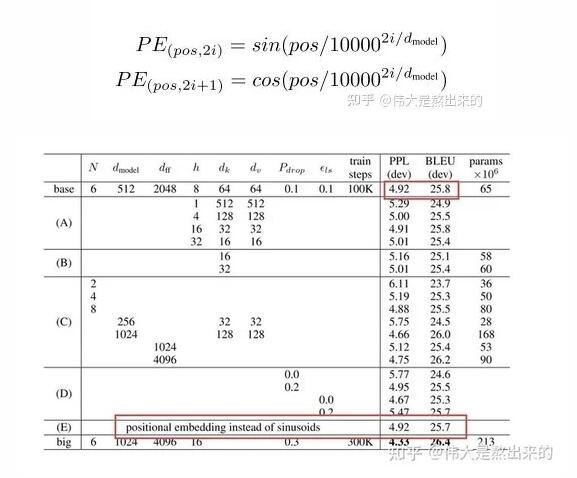
关于Positional Embedding,我们需要参考论文给出的公式。说一句题外话,在作者的实验中对比了Positional Embedding与单独采用一个Embedding训练模型对位置的感知两种方式,模型效果相差无几。
- class Positional_Encoding(nn.Module):
- def __init__(self,d_model):
- super(Positional_Encoding,self).__init__()
- self.d_model = d_model
- def forward(self,seq_len,embedding_dim):
- positional_encoding = np.zeros((seq_len,embedding_dim))
- for pos in range(positional_encoding.shape[0]):
- for i in range(positional_encoding.shape[1]):
- positional_encoding[pos][i] = math.sin(pos/(10000**(2*i/self.d_model))) if i % 2 == 0 else math.cos(pos/(10000**(2*i/self.d_model)))
- return torch.from_numpy(positional_encoding)
4. Encoder
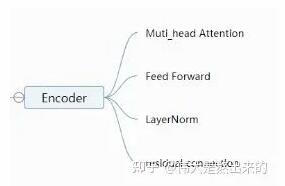
Muti_head_Attention
这一部分是模型的核心内容,理论部分就不过多讲解了,读者可以参考文章开头的第一个传送门,文中有基础的代码实现。
Encoder 中的 Muti_head_Attention 不需要Mask,因此与我们上一篇文章中的实现方式相同。
为了避免模型信息泄露的问题,Decoder 中的 Muti_head_Attention 需要Mask。这一节中我们重点讲解Muti_head_Attention中Mask机制的实现。
如果读者阅读了我们的上一篇文章,可以发现下面的代码有一点小小的不同,主要体现在 forward 函数的参数。
-
requires_mask:是否采用Mask机制,在Decoder中设置为True
- class Mutihead_Attention(nn.Module):
- def __init__(self,d_model,dim_k,dim_v,n_heads):
- super(Mutihead_Attention, self).__init__()
- self.dim_v = dim_v
- self.dim_k = dim_k
- self.n_heads = n_heads
- self.q = nn.Linear(d_model,dim_k)
- self.k = nn.Linear(d_model,dim_k)
- self.v = nn.Linear(d_model,dim_v)
- self.o = nn.Linear(dim_v,d_model)
- self.norm_fact = 1 / math.sqrt(d_model)
- def generate_mask(self,dim):
- # 此处是 sequence mask ,防止 decoder窥视后面时间步的信息。
- # padding mask 在数据输入模型之前完成。
- matirx = np.ones((dim,dim))
- mask = torch.Tensor(np.tril(matirx))
- return mask==1
- def forward(self,x,y,requires_mask=False):
- assert self.dim_k % self.n_heads == 0 and self.dim_v % self.n_heads == 0
- # size of x : [batch_size * seq_len * batch_size]
- # 对 x 进行自注意力
- Q = self.q(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.n_heads) # n_heads * batch_size * seq_len * dim_k
- K = self.k(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.n_heads) # n_heads * batch_size * seq_len * dim_k
- V = self.v(y).reshape(-1,y.shape[0],y.shape[1],self.dim_v // self.n_heads) # n_heads * batch_size * seq_len * dim_v
- # print("Attention V shape : {}".format(V.shape))
- attention_score = torch.matmul(Q,K.permute(0,1,3,2)) * self.norm_fact
- if requires_mask:
- mask = self.generate_mask(x.shape[1])
- attention_score.masked_fill(mask,value=float("-inf")) # 注意这里的小Trick,不需要将Q,K,V 分别MASK,只MASKSoftmax之前的结果就好了
- output = torch.matmul(attention_score,V).reshape(y.shape[0],y.shape[1],-1)
- # print("Attention output shape : {}".format(output.shape))
- output = self.o(output)
- return output
Feed Forward

这一部分实现很简单,两个Linear中连接Relu即可,目的是为模型增添非线性信息,提高模型的拟合能力。
- class Feed_Forward(nn.Module):
- def __init__(self,input_dim,hidden_dim=2048):
- super(Feed_Forward, self).__init__()
- self.L1 = nn.Linear(input_dim,hidden_dim)
- self.L2 = nn.Linear(hidden_dim,input_dim)
- def forward(self,x):
- output = nn.ReLU()(self.L1(x))
- output = self.L2(output)
- return output
Add & LayerNorm
这一节我们实现论文中提出的残差连接以及LayerNorm。
论文中关于这部分给出公式:

代码中的dropout,在论文中也有所解释,对输入layer_norm的tensor进行dropout,对模型的性能影响还是蛮大的。
代码中的参数 sub_layer ,可以是Feed Forward,也可以是Muti_head_Attention。
- class Add_Norm(nn.Module):
- def __init__(self):
- self.dropout = nn.Dropout(config.p)
- super(Add_Norm, self).__init__()
- def forward(self,x,sub_layer,**kwargs):
- sub_output = sub_layer(x,**kwargs)
- # print("{} output : {}".format(sub_layer,sub_output.size()))
- x = self.dropout(x + sub_output)
- layer_norm = nn.LayerNorm(x.size()[1:])
- out = layer_norm(x)
- return out
OK,Encoder中所有模块我们已经讲解完毕,接下来我们将其拼接作为Encoder
- class Encoder(nn.Module):
- def __init__(self):
- super(Encoder, self).__init__()
- self.positional_encoding = Positional_Encoding(config.d_model)
- self.muti_atten = Mutihead_Attention(config.d_model,config.dim_k,config.dim_v,config.n_heads)
- self.feed_forward = Feed_Forward(config.d_model)
- self.add_norm = Add_Norm()
- def forward(self,x): # batch_size * seq_len 并且 x 的类型不是tensor,是普通list
- x += self.positional_encoding(x.shape[1],config.d_model)
- # print("After positional_encoding: {}".format(x.size()))
- output = self.add_norm(x,self.muti_atten,y=x)
- output = self.add_norm(output,self.feed_forward)
- return output
5.Decoder
在 Encoder 部分的讲解中,我们已经实现了大部分Decoder的模块。Decoder的Muti_head_Attention引入了Mask机制,Decoder与Encoder 中模块的拼接方式不同。以上两点读者在Coding的时候需要注意。
- class Decoder(nn.Module):
- def __init__(self):
- super(Decoder, self).__init__()
- self.positional_encoding = Positional_Encoding(config.d_model)
- self.muti_atten = Mutihead_Attention(config.d_model,config.dim_k,config.dim_v,config.n_heads)
- self.feed_forward = Feed_Forward(config.d_model)
- self.add_norm = Add_Norm()
- def forward(self,x,encoder_output): # batch_size * seq_len 并且 x 的类型不是tensor,是普通list
- # print(x.size())
- x += self.positional_encoding(x.shape[1],config.d_model)
- # print(x.size())
- # 第一个 sub_layer
- output = self.add_norm(x,self.muti_atten,y=x,requires_mask=True)
- # 第二个 sub_layer
- output = self.add_norm(output,self.muti_atten,y=encoder_output,requires_mask=True)
- # 第三个 sub_layer
- output = self.add_norm(output,self.feed_forward)
- return output
6.Transformer
至此,所有内容已经铺垫完毕,我们开始组装Transformer模型。论文中提到,Transformer中堆叠了6个我们上文中实现的Encoder 和 Decoder。这里笔者采用 nn.Sequential 实现了堆叠操作。
Output模块的 Linear 和 Softmax 的实现也包含在下面的代码中
- class Transformer_layer(nn.Module):
- def __init__(self):
- super(Transformer_layer, self).__init__()
- self.encoder = Encoder()
- self.decoder = Decoder()
- def forward(self,x):
- x_input,x_output = x
- encoder_output = self.encoder(x_input)
- decoder_output = self.decoder(x_output,encoder_output)
- return (encoder_output,decoder_output)
- class Transformer(nn.Module):
- def __init__(self,N,vocab_size,output_dim):
- super(Transformer, self).__init__()
- self.embedding_input = Embedding(vocab_size=vocab_size)
- self.embedding_output = Embedding(vocab_size=vocab_size)
- self.output_dim = output_dim
- self.linear = nn.Linear(config.d_model,output_dim)
- self.softmax = nn.Softmax(dim=-1)
- self.model = nn.Sequential(*[Transformer_layer() for _ in range(N)])
- def forward(self,x):
- x_input , x_output = x
- x_input = self.embedding_input(x_input)
- x_output = self.embedding_output(x_output)
- _ , output = self.model((x_input,x_output))
- output = self.linear(output)
- output = self.softmax(output)
- return output
完整代码
- # @Author:Yifx
- # @Contact: Xxuyifan1999@163.com
- # @Time:2021/9/16 20:02
- # @Software: PyCharm
- """
- 文件说明:
- """
- import torch
- import torch.nn as nn
- import numpy as np
- import math
- class Config(object):
- def __init__(self):
- self.vocab_size = 6
- self.d_model = 20
- self.n_heads = 2
- assert self.d_model % self.n_heads == 0
- dim_k = self.d_model // self.n_heads
- dim_v = self.d_model // self.n_heads
- self.padding_size = 30
- self.UNK = 5
- self.PAD = 4
- self.N = 6
- self.p = 0.1
- config = Config()
- class Embedding(nn.Module):
- def __init__(self,vocab_size):
- super(Embedding, self).__init__()
- # 一个普通的 embedding层,我们可以通过设置padding_idx=config.PAD 来实现论文中的 padding_mask
- self.embedding = nn.Embedding(vocab_size,config.d_model,padding_idx=config.PAD)
- def forward(self,x):
- # 根据每个句子的长度,进行padding,短补长截
- for i in range(len(x)):
- if len(x[i]) < config.padding_size:
- x[i].extend([config.UNK] * (config.padding_size - len(x[i]))) # 注意 UNK是你词表中用来表示oov的token索引,这里进行了简化,直接假设为6
- else:
- x[i] = x[i][:config.padding_size]
- x = self.embedding(torch.tensor(x)) # batch_size * seq_len * d_model
- return x
- class Positional_Encoding(nn.Module):
- def __init__(self,d_model):
- super(Positional_Encoding,self).__init__()
- self.d_model = d_model
- def forward(self,seq_len,embedding_dim):
- positional_encoding = np.zeros((seq_len,embedding_dim))
- for pos in range(positional_encoding.shape[0]):
- for i in range(positional_encoding.shape[1]):
- positional_encoding[pos][i] = math.sin(pos/(10000**(2*i/self.d_model))) if i % 2 == 0 else math.cos(pos/(10000**(2*i/self.d_model)))
- return torch.from_numpy(positional_encoding)
- class Mutihead_Attention(nn.Module):
- def __init__(self,d_model,dim_k,dim_v,n_heads):
- super(Mutihead_Attention, self).__init__()
- self.dim_v = dim_v
- self.dim_k = dim_k
- self.n_heads = n_heads
- self.q = nn.Linear(d_model,dim_k)
- self.k = nn.Linear(d_model,dim_k)
- self.v = nn.Linear(d_model,dim_v)
- self.o = nn.Linear(dim_v,d_model)
- self.norm_fact = 1 / math.sqrt(d_model)
- def generate_mask(self,dim):
- # 此处是 sequence mask ,防止 decoder窥视后面时间步的信息。
- # padding mask 在数据输入模型之前完成。
- matirx = np.ones((dim,dim))
- mask = torch.Tensor(np.tril(matirx))
- return mask==1
- def forward(self,x,y,requires_mask=False):
- assert self.dim_k % self.n_heads == 0 and self.dim_v % self.n_heads == 0
- # size of x : [batch_size * seq_len * batch_size]
- # 对 x 进行自注意力
- Q = self.q(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.n_heads) # n_heads * batch_size * seq_len * dim_k
- K = self.k(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.n_heads) # n_heads * batch_size * seq_len * dim_k
- V = self.v(y).reshape(-1,y.shape[0],y.shape[1],self.dim_v // self.n_heads) # n_heads * batch_size * seq_len * dim_v
- # print("Attention V shape : {}".format(V.shape))
- attention_score = torch.matmul(Q,K.permute(0,1,3,2)) * self.norm_fact
- if requires_mask:
- mask = self.generate_mask(x.shape[1])
- # masked_fill 函数中,对Mask位置为True的部分进行Mask
- attention_score.masked_fill(mask,value=float("-inf")) # 注意这里的小Trick,不需要将Q,K,V 分别MASK,只MASKSoftmax之前的结果就好了
- output = torch.matmul(attention_score,V).reshape(y.shape[0],y.shape[1],-1)
- # print("Attention output shape : {}".format(output.shape))
- output = self.o(output)
- return output
- class Feed_Forward(nn.Module):
- def __init__(self,input_dim,hidden_dim=2048):
- super(Feed_Forward, self).__init__()
- self.L1 = nn.Linear(input_dim,hidden_dim)
- self.L2 = nn.Linear(hidden_dim,input_dim)
- def forward(self,x):
- output = nn.ReLU()(self.L1(x))
- output = self.L2(output)
- return output
- class Add_Norm(nn.Module):
- def __init__(self):
- self.dropout = nn.Dropout(config.p)
- super(Add_Norm, self).__init__()
- def forward(self,x,sub_layer,**kwargs):
- sub_output = sub_layer(x,**kwargs)
- # print("{} output : {}".format(sub_layer,sub_output.size()))
- x = self.dropout(x + sub_output)
- layer_norm = nn.LayerNorm(x.size()[1:])
- out = layer_norm(x)
- return out
- class Encoder(nn.Module):
- def __init__(self):
- super(Encoder, self).__init__()
- self.positional_encoding = Positional_Encoding(config.d_model)
- self.muti_atten = Mutihead_Attention(config.d_model,config.dim_k,config.dim_v,config.n_heads)
- self.feed_forward = Feed_Forward(config.d_model)
- self.add_norm = Add_Norm()
- def forward(self,x): # batch_size * seq_len 并且 x 的类型不是tensor,是普通list
- x += self.positional_encoding(x.shape[1],config.d_model)
- # print("After positional_encoding: {}".format(x.size()))
- output = self.add_norm(x,self.muti_atten,y=x)
- output = self.add_norm(output,self.feed_forward)
- return output
- # 在 Decoder 中,Encoder的输出作为Query和KEy输出的那个东西。即 Decoder的Input作为V。此时是可行的
- # 因为在输入过程中,我们有一个padding操作,将Inputs和Outputs的seq_len这个维度都拉成一样的了
- # 我们知道,QK那个过程得到的结果是 batch_size * seq_len * seq_len .既然 seq_len 一样,那么我们可以这样操作
- # 这样操作的意义是,Outputs 中的 token 分别对于 Inputs 中的每个token作注意力
- class Decoder(nn.Module):
- def __init__(self):
- super(Decoder, self).__init__()
- self.positional_encoding = Positional_Encoding(config.d_model)
- self.muti_atten = Mutihead_Attention(config.d_model,config.dim_k,config.dim_v,config.n_heads)
- self.feed_forward = Feed_Forward(config.d_model)
- self.add_norm = Add_Norm()
- def forward(self,x,encoder_output): # batch_size * seq_len 并且 x 的类型不是tensor,是普通list
- # print(x.size())
- x += self.positional_encoding(x.shape[1],config.d_model)
- # print(x.size())
- # 第一个 sub_layer
- output = self.add_norm(x,self.muti_atten,y=x,requires_mask=True)
- # 第二个 sub_layer
- output = self.add_norm(x,self.muti_atten,y=encoder_output,requires_mask=True)
- # 第三个 sub_layer
- output = self.add_norm(output,self.feed_forward)
- return output
- class Transformer_layer(nn.Module):
- def __init__(self):
- super(Transformer_layer, self).__init__()
- self.encoder = Encoder()
- self.decoder = Decoder()
- def forward(self,x):
- x_input,x_output = x
- encoder_output = self.encoder(x_input)
- decoder_output = self.decoder(x_output,encoder_output)
- return (encoder_output,decoder_output)
- class Transformer(nn.Module):
- def __init__(self,N,vocab_size,output_dim):
- super(Transformer, self).__init__()
- self.embedding_input = Embedding(vocab_size=vocab_size)
- self.embedding_output = Embedding(vocab_size=vocab_size)
- self.output_dim = output_dim
- self.linear = nn.Linear(config.d_model,output_dim)
- self.softmax = nn.Softmax(dim=-1)
- self.model = nn.Sequential(*[Transformer_layer() for _ in range(N)])
- def forward(self,x):
- x_input , x_output = x
- x_input = self.embedding_input(x_input)
- x_output = self.embedding_output(x_output)
- _ , output = self.model((x_input,x_output))
- output = self.linear(output)
- output = self.softmax(output)
- return output