













Facebook 近日宣布了 CompilerGym 项目,这是一个用于执行编译器优化任务的高性能、易于使用的强化学习 (Reinforcement Learning, RL) 环境库,用于解决生产环境中的编译器优化问题。
CompilerGym 由 Facebook 的 AI 团队在 OpenAI Gym 之上构建,并最终致力于帮助提高代码编译器的性能。他们在公告中表示:“CompilerGym 对重要的编译器优化问题进行了打包,并使它们看起来像强化学习问题。我们引入的编译器优化问题规模很大。例如搜索空间为 104461,远大于围棋的搜索空间。但另一方面,搜索空间又是无限的。得益于强化学习的最新进展,这种规模的问题第一次有可能取得进展。CompilerGym 让任何具有 ML 或编译器背景的人都可以轻松地直接投入并开始解决问题,而无需花费通常需要的数月繁琐配置时间。这是因为我们已经为你完成了这些工作!”
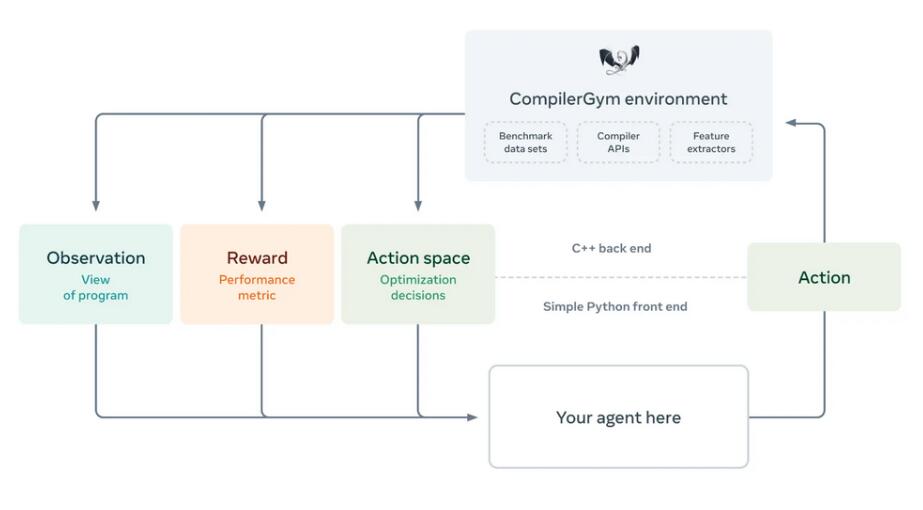
开发团队还补充道,“我们的目标是成为通过 ML 让编译器速度更快的催化剂,因为程序如果优化不当会非常慢,并且消耗过多的计算资源和能源,限制了节能边缘设备的应用,使数据中心不那么环保。”
据介绍,在此项目的第一个版本中,Facebook 为三个编译器问题提供了强化学习环境: 使用 LLVM 进行相位排序、使用 GCC 调整 flag,以及使用 CUDA 循环嵌套生成。他们还提供了用于训练的大量程序数据集、验证结果可重复性的脚本、公共记分榜和 Web 前端。随着时间的推移,他们计划为其他成熟的编译器问题提供支持,包括寄存器分配、窥孔优化 (peephole optimization) 和循环优化。开发团队还希望增加更多的任务、奖励、观察和行动,旨在通过这些举动让编译器和 ML 研究社区更加紧密地联系在一起。
本文转自OSCHINA
本文标题:Facebook 使用机器学习优化编译器
本文地址:https://www.oschina.net/news/163236/facebook-compiler-gym


















