












最近Facebook发生史上最严重的宕机事件,导致其全球网络宕机6个多小时。
按道理,Facebook这种体量的公司,应该有一套完整的应急预案,不会出现长时间的宕机才对。可是,一连串狗血剧情的发生,让Facebook不得不接受这个事实。
首先是程序员敲错了一个命令,系统在审计命令的时候,应该不放行。巧的是,审计工具有bug,竟然放行了这条命令。
更要命的是,因为数据中心的安全设计,驻场工程师无法接触到服务器,只得“溜门撬锁”,费劲千辛万苦才修复完成。
修复完一上线又崩了一次,第二次才完全修复完毕,整个过程耗费整整6个小时,堪称史诗级灾难大片。
事件经过
一切都要从日常维护中的一条错误命令说起。
在日常维护基础设施时,工程师需要离线维护部分主干网,例如修理一条光纤线路、增加更多容量或者更新路由器本身的软件等等。
10月初,出于这一需要,工程师需使用一条命令,以评估网络状态,然而却误敲成清空路由表的命令。
按道理,审计工具应该拦截这条异常命令,结果因为工具本身的bug,这一条命令被放行。
在Facebook的系统设计中,Facebook所有域名服务器,会在服务器连接不上数据中心对应IP的情况下,停止DNS解析。这一设计的目的是如果IP不可达,那么网络存在问题,解析出来也没有太大的意义。这样一来,用户的请求仍然可以解析到其他IP上。
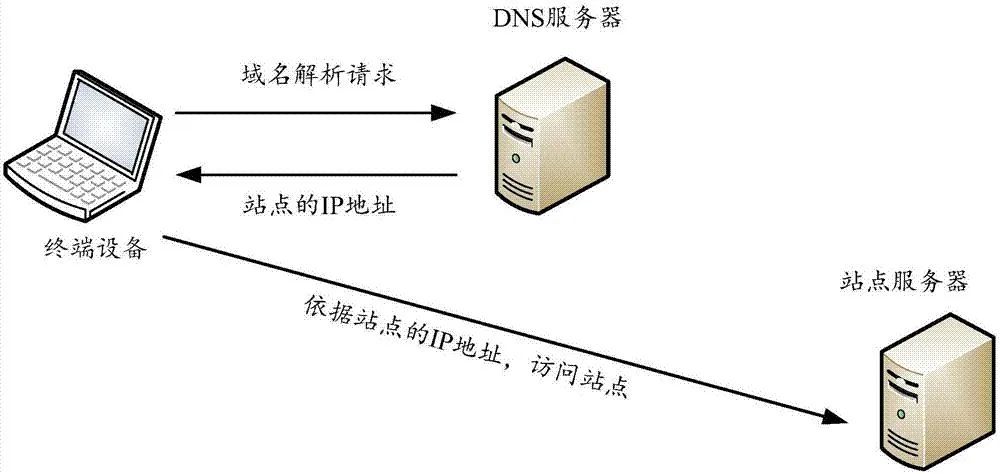
但是这一骚操作,直接将Facebook整套自有域名服务器瘫痪掉,即便其他服务器都没有问题,没有DNS指路,业务也无法顺利进行。
基础架构翻车、沟通协调不畅以及远程排除故障困难,是导致Facebook宕机6小时的主要原因。
另外一个原因有点让人哭笑不得。
数据中心有各式各样的安全设计,以防止数据盗窃以及其他安全事件的发生。然而因为这些设计上的问题,导致当天驻场工程师,无法第一时间接触到服务器,不得不强制清除一些“物理”障碍,修复时间一再推迟。
因为修复策略是一台一台恢复,导致先上线的少量服务器,无法顶住已经存在的巨大空转流量,而再次宕机。
最后拔了网线,将集群全部恢复起来,才最终完成修复。
后果
Facebook宕机事故丝毫不亚于前段时间“B站崩溃”事件,在国外引起了轩然大波。网友们纷纷围观,甚至调侃。
还有一些品牌借此次事件进行营销。

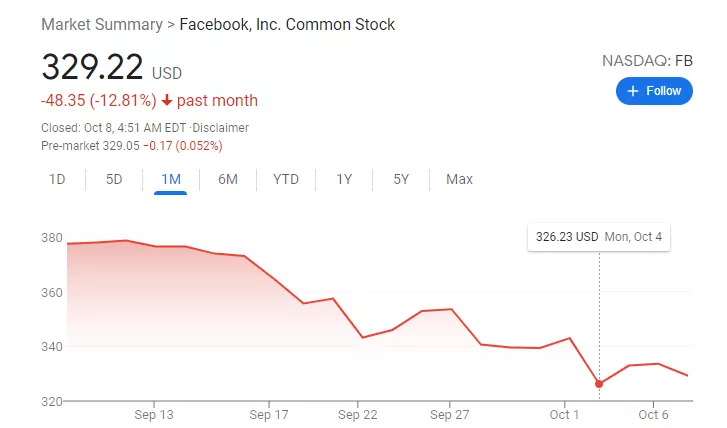
宕机事故发生后,Facebook股价暴跌6%,扎克伯格个人财富一日之间蒸发逾60亿美元。
事后Facebook工程师们对此次事故进行复盘,估计要被很多低级的错误蠢哭,不过话说回来,很多事情就是这样,事前死活想不到,事后复盘猪一样。一开始工程师们做架构规划的时候,可能死活也想不到一些低级的错误。
















