在业务场景中,要想做到有备无患,最好是用集群,没有集群,至少也要做到主从,有了主从,当 master 挂掉的时候,让从库过来接管,服务就可以继续,否则 master 需要经过数据恢复和重启的过程,这就可能会拖很长的时间,影响线上业务的持续服务。在了解 Redis 集群实现之前需要了解redis 的主从复制,了解主从复制之前首先要了解分布式系统的理论基石 CAP 原理。
CAP
CAP是分布式存储的理论基石.
C:一致性;A:可用性;P:分区容忍性;原理:当网络分区发生时,一致性和可用性很难两全.
redis 满足可用性(AP);保证最终一致性。
Redis 保证「最终一致性」,从节点会努力追赶主节点,最终从节点的状态会和主节点
的状态将保持一致。如果网络断开了,主从节点的数据将会出现大量不一致,一旦网络恢
复,从节点会采用多种策略努力追赶上落后的数据,继续尽力保持和主节点一致。
关于同步
主从同步
Redis 同步支持主从同步和从从同步,从从同步功能是 Redis 后续版本增加的功能,为
了减轻主库的同步负担。后面为了描述上的方便,统一理解为主从同步。
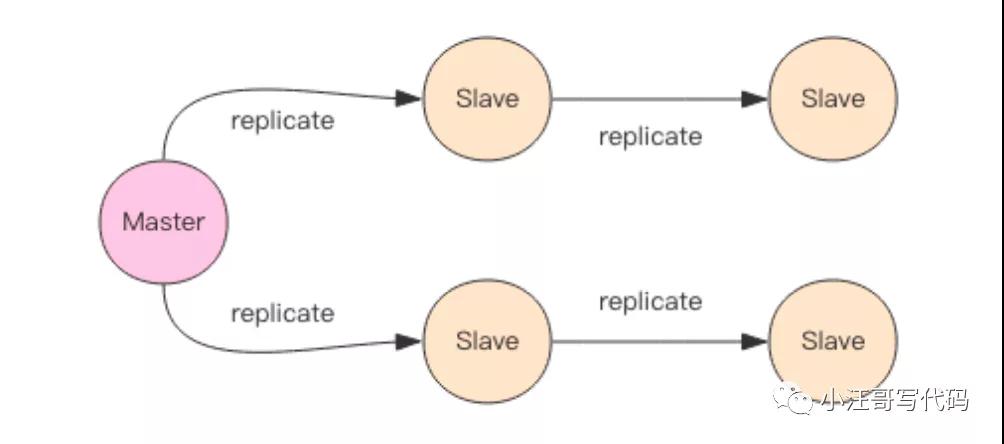
增量同步
同步是指令流,从节点一边同步指令流,一边反馈自己的偏移量,redis 的复制内存buffer是一个定长的环形数组;如果内存满了就会从头开始覆盖前面的内容。
快照同步
防止在网络不好,主从无法及时同步。造成指令覆盖,非常耗费资源的同步,在主节点上调用一次bgsave,将当前内存中的数据全部快照到磁盘中。然后将内容全部同步到从节点,从节点接收完文件后,立即进行一次全量加载,然后通知主节点同步buffer,如果复制buffer的大小过小,会造成快照同步死循环;务必配置合适的buffer大小.
无盘复制
Redis 2.8.18 版开始支持无盘复制。所谓无盘复制是指主服务器直接通过套接字将快照内容发送到从节点,生成快照是一个遍历的过程,主节点会一边遍历内存,一遍将序列化的内容发送到从节点,从节点还是跟之前一样,先将接收到的内容存储到磁盘文件中,再进行一次性加载。
wait 指令
redis 3.0 以后才有,命令wait n t,表示 t 时间内等待同步 n 个节点,如果t=0 出现网路分区,则redis 会丧失可用性。
sentinel 集群
可以将redis sentinel 集群看作是一个zookeeper集群,一般是由3-5个节点组成,Redis 主从采用异步复制,意味着当主节点挂掉时,从节点可能没有收到全部的同步消息,这部分未同步的消息就丢失了。如果主从延迟特别大,那么丢失的数据就可能会特别多。Sentinel 无法保证消息完全不丢失,但是也尽可能保证消息少丢失。它有两个选项可以
限制主从延迟过大。
- min-slaves-to-write 1
- min-slaves-max-lag 10
第一个参数表示主节点必须至少有一个从节点在进行正常复制,否则就停止对外写服务,丧失可用性。sentinel 的默认端口是26379,主节点挂掉,会断开所有连接,重新与新的主节点建立连接,所有update 操作会报错,捕获一个readOnlyError。
主从切换后,之前的主库被降级到从库,所有的修改性的指令都会抛出 ReadonlyError。
如果没有修改性指令,虽然连接不会得到切换,但是数据不会被破坏,所以即使不切换也没关系。
codis 集群
单实例redis 只用到了一个cpu,无法完成海量数据的存储和管理,codis 是redis 集群解决方案之一,是前豌豆荚团队开发的,项目负责人 刘奇 又开发了分布式数据库TiDB,使用go 语言,他是一个代理中间件;使用redis 协议对外服务。
分片原理
默认 1024个槽,可以调整,建议调整到2048、4096,slot 的计算方式:key->crc32 得到hash 值->hash%1024=slot,会在内存中维护slot 和redis 实例的关系。
不同codis 实例直接槽位关系同步
使用zk、etcd 存储槽位关系 从而实现共享槽位关系配置。
扩容
codis 对redis 进行了改造,增加了 slotsscan 命令可以遍历指定slot 下的所有的key,codis 接收到正在迁移的key,会强制迁移然后将请求打到 新的实例上。
缺点
- 不是亲儿子
- 单个key 不易过大
- 不支持事物
- 增加 代理层的网络开销
- 需要维护zk 集群
优点
- slot自动均衡
- 有很好的后台管理系统,qps 曲线,slot 状态,slot分到哪个实例 等等。
redis cluster 集群
RedisCluster 是 Redis 的亲儿子,它是 Redis 作者自己提供的 Redis 集群化方案。相对于 Codis 的不同,它是去中心化的。每个节点负责不同的数据,
Redis 集群节点采用 Gossip 协议来广播自己的状态以及自己对整个集群认知的改变。比如一个节点发现某个节点失联了 (PFail),它会将这条信息向整个集群广播,其它节点也就可以收到这点失联信息。如果一个节点收到了某个节点失联的数量 (PFail Count) 已经达到了集群的大多数,就可以标记该节点为确定下线状态 (Fail),然后向整个集群广播,强迫其它节点也接收该节点已经下线的事实,并立即对该失联节点进行主从切换。
默认分16384 个槽位,客户端会存储一份槽位配置信息。
槽位定位
- key->crc16得到hash值->hash%16384=slot
- 通过在key 字符串里嵌入tag 标记;
- 可以强制key所在的槽位;
跳转
当槽位发生迁移时,请求旧槽位 会返回一个MOVED 指令 后面跟一个目标节点地址,客户端收到MOVED 指令后,立刻纠正本地槽位映射表。
第二个 asking 指令和 moved 不一样,它是用来临时纠正槽位的。如果当前槽位正处于
迁移中,指令会先被发送到槽位所在的旧节点,如果旧节点存在数据,那就直接返回结果
了,如果不存在,那么它可能真的不存在也可能在迁移目标节点上。所以旧节点会通知客户
端去新节点尝试一下拿数据,看看新节点有没有。这时候就会给客户端返回一个 asking error
携带上目标节点的地址。客户端收到这个 asking error 后,就会去目标节点去尝试。客户端
不会刷新槽位映射关系表,因为它只是临时纠正该指令的槽位信息,不影响后续指令。
为了防止连续跳转,rt 过高,客户端设置重试次数。
迁移
一个槽一个槽的进行迁移,没有有很友好的UI。大致过程如下:
从源节点获取内容-》存到目标节点-》从源节点删除内容,整个过程是同步的,会造成阻塞。
集群变更感知
当服务器节点变更时,客户端应该即时得到通知以实时刷新自己的节点关系表。那客户端是如何得到通知的呢?这里要分 2 种情况:
目标节点挂掉了,客户端会抛出一个 ConnectionError,紧接着会随机挑一个节点来重试,这时被重试的节点会通过 moved error 告知目标槽位被分配到的新的节点地址。
运维手动修改了集群信息,将 master 切换到其它节点,并将旧的 master 移除集群。这时打在旧节点上的指令会收到一个 ClusterDown 的错误,告知当前节点所在集群不可用 (当前节点已经被孤立了,它不再属于之前的集群)。这时客户端就会关闭所有的连接,清空槽位映射关系表,然后向上层抛错。待下一条指令过来时,就会重新尝试初始化节点信息。
容错
每个主节点设置多个从节点,主节点挂了之后从某个从节点中提拔一个,没有可用从节点,可用设置cluster-require-full-coverage 允许部分错误,其他节点正常对外服务。
网络抖动
设置主从切换松弛系数和cluster-node-timeout ,防止网络抖动导致频繁的主从切换。