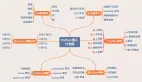
collections 库是标准库的一部分,里面有很多数据结构,在列表、字典、元组的基础上做了很多修改和提升。
今天就来说说最有用的几个。
1、deque
它实现了两端都可以操作的队列,相当于双端队列,与可以指定最多存储多少个元素,与 Python 的基本数据类型列表很相似。
- from collections import deque
- a = deque(maxlen=3)
上述代码定义了大小为 3 的双端队列,当你插入第 4 个元素时,队列的第一个元素会被删除。
- a = deque(maxlen=3)
- a.append(1) # a = [1]
- a.append(2) # a = [1, 2]
- a.append(3) # a = [1, 2, 3] FULL
- a.append(4) # a = [2,3,4]
因为这是一个双端队列,你可以在队列的首位插入元素,也可以在首尾删除元素,它们的时间复杂度都是 O(1):
- append(x) 在队列尾部插入 x
- appendleft(x) 在队列头部插入 x
- pop() 在队列尾部删除一个元素,并返回
- popleft() 在队列头部删除一个元素,并返回
- a = deque(maxlen = 10)
- a.append(1) # a = [1]
- a.append(2) # a = [1, 2] 在队列尾部插入 2
- a.appendleft(3)# a = [3, 1, 2] 在队列头部插入 3
- x = a.pop() # a = [3, 1], x = 2 删除队列尾部元素 2
- y = a.popleft() # a = [1], y = 3 删除队列头部元素 3
2、namedtuple
这个库提供了命名的元组,可以通过指定的名称来访问,例如:
- from collections import namedtuple
- Point = namedtuple("Point", ['x','y','z'])
- p = Point(3,4,5)
- print(p.x, p.y, p.z) #Output: 3, 4, 5
namedtuple 函数把第一个参数作为新元组的名称,第二个参数就是元组内元素的名称映射,可以是一个字符串列表,也可以是空格或逗号分割的字符串。
- Point = namedtuple("Point", "x y z")
- Point = namedtuple("Point", "x,y,z")
也可以这样初始化,非常灵活:
- p1 = Point(3,4,5)
- p2 = Point(x=3, y=4, z=5)
- p3 = Point._make([3,4,5])
还可以使用 namedtuple 来设置默认值:
- PointDef = namedtuple("PointDef", "x, y, z", defaults = [0,0,0])
- p = PointDef(x=1) # p is (1,0,0)
如果你定义了三个名称,却提供了两个默认值,那么只有最后两个会被赋予默认值:
- Point = namedtuple("Point", "x y z",defaults ="[0, 0])
- print(Point._field_defaults)
- # output: {“y”: 0, “z”: 0}
3、Counter
计数器 Counter 非常有用,尤其当你需要统计列表或可迭代对象中元素的数量时:
- from collections import Counter
- c = Counter(“aaabbccdaaa”)
- print(c)
- #Output: Counter({'a': 6, 'b': 2, 'c': 2, 'd': 1})
还可以方便的统计频率前几大,比如统计出现频率最高的两个元素:
- print(c.most_common(2))
- #output: [('a', 6), ('b', 2)]
还可以动态增删字符串,然后统计:
- c = Counter("abbc") # {"a":1, "b":2, "c":1}
- c.update("bccd") # {"a":1, "b":3, "c":3, "d":1}
- c.subtract("bbc") # {"a":1, "b":1, "c":2, "d":1}
4、defaultdict
defaultdict 和 dict 差不多,但是可以提供 dict 的 values 的默认数据类型,比如:
- from collections import defaultdict
- toAdd =[("key1", 3), ("key2", 5), ("key3", 6), ("key2", 7)]
- d = defaultdict(list)
- for key, val in toAdd:
- d[key].append(val)
- print(d) # {"key1":[3], "key2":[5, 7], "key3":[6]}
如果你用 dict,可能要这样写:
- d = dict()
- for key, val in toAdd:
- if key in d:
- d[key].append(val)
- else:
- d[key] = [val]
或者是这样的:
- d = dict()
- for key, val in toAdd:
- d.setdefault(key, []).append(val)
总之,defaultdict 是简单和快捷的。