首先,我们需要明确一下这几个名词出现的场景:分布式高并发环境。如果你的产品卖相不好,没人鸟它,那它就用不着这几个属性。不需要任何加成,低并发系统就能工作的很好。
分布式系统是一个整体,调用关系错综复杂,其中某个资源异常,大概率会造成级联故障。当系统处于超负荷的压力之下,容器或者宿主机,将表现的异乎寻常的脆弱。load飙升、拒绝响应,甚至于雪崩,造成的后果都比较严重。
鉴于分布式系统病娇娘样式的反应,我们有各种手段来处理这些异常状况。接下来,我们将简要介绍一下这些场景,还有常用的手段。
1. 限流
“我的贴子被限流了!” 即使不是互联网从业人员,也能言之凿凿的说出这样的话。当他这么说的时候,他并不是在说高并发中的限流,它只是逻辑意义上的。
web开发中,tomcat默认是200个线程池,当更多的请求到来,没有新的线程能够去处理这个请求,那这个请求将会一直等待在浏览器方。表现的形式是,浏览器一直在转圈(还没超过acceptCount),即使你请求的是一个简单的Hello world。
你可以把这个过程,也看作是限流。它在本质上,是设置一个资源数量上限,超出这个上限的请求,将被缓冲,或者直接失败。
对于高并发场景下的限流来说,它有特殊的含义:它主要是用来保护底层资源的。如果你想要调用某些服务,你需要首先获取调用它的许可。限流一般由服务提供方来提供,对调用方能够做事的能力进行限制。
比如,某个服务为A、B、C都提供了服务,但根据提前申请的流量预估,限制A服务的请求为1000/秒、B服务2000/秒,C服务1w/秒。在同一时刻,某些客户端可能会出现被拒绝的请求,而某些客户端能够正常运行,限流被看作是服务端的自我保护能力。
常见的限流算法有:计数器、漏桶、令牌桶等。但计数器算法无法实现平滑的限流,在实际应用中使用较少。
2. 熔断
通常来说,皇帝在微服务里想夜生活过得舒服,能够大刀阔斧单刀直入,不因私事丢江山,就不得不靠熔断大总管。熔断的作用,主要是为了避免服务的雪崩。
如图,A→B→C互相依次调用,但C项目很可能出现问题(流量过大或者报错等),就会引发线程一直进行等待,导致拖垮整个链路层,线程资源耗尽。
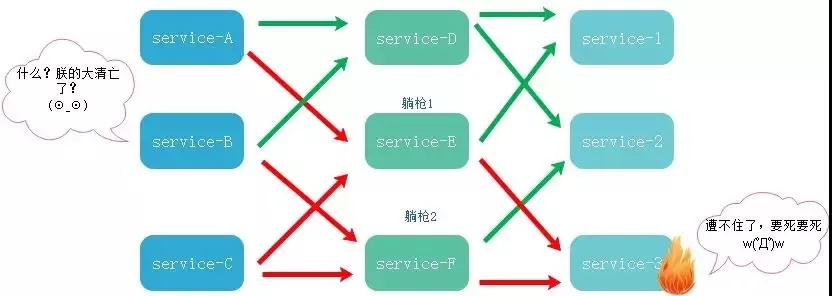
意如其名,熔断就像是保险丝,超过负载了保险丝就烧掉了。当然,当后端服务缓和的时候,我们还可以再把它接上。熔断功能一般由调用端提供,用在不太重要的旁路请求上,避免这些不重要的服务因为异常或者超时,影响正常的、重要的业务逻辑
在实现上,我们可以把熔断看作是一种代理模式。当熔断打开的时候,服务将暂停对其保护资源的访问,并返回固定的或者不产生远程调用的默认结果。
3. 降级
降级是一个比较模糊的说法。限流、熔断,在一定程度上,也可以看作是降级的一种。但通常所说的降级,切入的层次更加高级一些。
降级一般考虑的是分布式系统的整体性,从源头上切断流量的来源。比如在双11的时候,为了保证交易系统,将会暂停一些不重要的服务,以免产生资源争占。服务降级有人工参与,人为使得某些服务不可用,多属于一种业务降级方式。
在什么地方最适合做降级呢?就是入口。比如Nginx,比如DNS等。
在某些互联网应用中,会存在MVP(Minimum Viable Product)这个概念,意为最小化可行产品,它的SLA要求非常高。围绕着最小可行性产品,会有一系列的服务拆分操作,当然某些情况甚至需要重写。
比如,一个电商系统,在极端情况下,只需要把商品显示出来,把商品卖出去就行。其他一些支撑性的系统,比如评论、推荐等,都可以临时关掉。在物理部署和调用关系上,就要考虑这些情况。
4. 预热
请看下面一种情况。
一个高并发环境下的DB,进程死亡后进行重启。由于业务处在高峰期间,上游的负载均衡策略发生了重分配。刚刚启动的DB瞬间接受了1/3的流量,然后load疯狂飙升,直至再无响应。
原因就是:新启动的DB,各种Cache并没有准备完毕,系统状态与正常运行时截然不同。可能平常1/10的量,就能够把它带入死亡。
同理,一个刚刚启动的JVM进程,由于字节码并未被JIT编译器优化,在刚启动的时候,所有接口的响应时间都比较慢。如果调用它的负载均衡组件,并没有考虑这种刚启动的情况,1/n的流量被正常路由到这个节点,就很容易出现问题。
所以,我们希望负载均衡组件,能够依据JVM进程的启动时间,动态的慢慢加量,进行服务预热,直到达到正常流量水平。
5. 背压
考虑一下下面两种场景:
没有限流。请求量过高,有多少收多少,极容易造成后端服务崩溃或者内存溢出
传统限流。你强行规定了某个接口最大的承受能力,超出了直接拒绝,但此时后端服务是有能力处理这些请求的
如何动态的修改限流的值?这就需要一套机制。调用方需要知道被调用方的处理能力,也就是被调用方需要拥有反馈的能力。背压,英文Back Pressure,其实是一种智能化的限流,指的是一种策略。
背压思想,被请求方不会直接将请求端的流量直接丢掉,而是不断的反馈自己的处理能力。请求端根据这些反馈,实时的调整自己的发送频率。比较典型的场景,就是TCP/IP中使用滑动窗口来进行流量控制。
反应式编程(Reactive)是观察者模式的集大成者。它们大多使用事件驱动,多是非阻塞的弹性应用,基于数据流进行弹性传递。在这种场景下,背压实现就简单的多。
背压,让系统更稳定,利用率也更高,它本身拥有更高的弹性和智能。
总结
简单总结一下:
限流 规定一个上限,流量超过系统承载能力时,会直接拒绝服务
熔断 不因底层旁路应用的故障,造成系统雪崩。欲练此功,必先自宫
降级 从请求入口,大范围的灭掉过载请求
预热 给系统一些启动预热时间,加载缓存,避免资源死锁
背压 被调用方反馈自己的能力给调用方。温柔的调用,需要坚实的沟通
简单来讲,只要流量不进系统,什么都好说,降级是最威猛最霸道的手段;一旦流量进入系统,就要接受系统内一系列规则的制约,其中限流是最直接的手段,将请求拦在外面。虽然用户的请求失败了,但我的系统还能活;没有熔断的系统就很凶残,很容易让三流功能影响主要功能,所以要在合适的时候打开它;至于预热,不过是在爱情火花前的一系列前戏,直到服务的巅峰状态;当然,相对于请求扔出去就不管的模式,如果被调用方能够反馈自己的状态,那么请求方就可以根据需要加大或者缩减马力,这就是背压的思想。
这些手段,都是在有限的资源下,有效的处理手段。但如果公司有钱,有弹性处理手段,这些都会变成辅助手段。毕竟,当所有的服务,能够将自己的状态,反馈到监控中心,监控中心能够实现弹性扩容。只要服务拆分的满足水平扩展,我们只需要增加实例就够了。
作者简介:小姐姐味道 (xjjdog),一个不允许程序员走弯路的公众号。聚焦基础架构和Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。