欢迎来到我们关于全栈开发人员分布式跟踪(Distributed Tracing)的系列的第 1 部分。在本系列中,我们将学习分布式跟踪的细节,以及它如何帮助您监控全栈应用程序日益复杂的需求。
在 Web 的早期,编写 Web 应用程序很简单。开发人员使用 PHP 等语言在服务器上生成 HTML,与 MySQL 等单一关系数据库进行通信,大多数交互性由静态 HTML 表单组件驱动。虽然调试工具很原始,但理解代码的执行流程很简单。
在今天的现代 web 栈中,它什么都不是。全栈开发人员需要编写在浏览器中执行的 JavaScript,与多种数据库技术互操作,并在不同的服务器架构(例如:serverless)上部署服务器端代码。如果没有合适的工具,了解浏览器中的用户交互如何关联到服务器堆栈深处的 500 server error 几乎是不可能的。Enter:分布式跟踪。
我试图解释 2021 年我的 web 堆栈中的瓶颈。
分布式跟踪(Distributed tracing)是一种监控技术,它将多个服务之间发生的操作和请求联系起来。这允许开发人员在端到端请求从一个服务移动到另一个服务时“跟踪(trace)”它的路径,让他们能够查明对整个系统产生负面影响的单个服务中的错误或性能瓶颈。
在这篇文章中,我们将了解有关分布式跟踪概念的更多信息,在代码中查看端到端(end-to-end)跟踪示例,并了解如何使用跟踪元数据为您的日志记录和监控工具添加有价值的上下文。完成后,您不仅会了解分布式跟踪的基础知识,还会了解如何应用跟踪技术来更有效地调试全栈 Web 应用程序。
但首先,让我们回到开头:什么是分布式追踪?
分布式追踪基础
分布式跟踪是一种记录多个服务的连接操作的方法。通常,这些操作是由从一个服务到另一个服务的请求发起的,其中“请求(request)”可以是实际的 HTTP 请求,也可以是通过任务队列或其他一些异步方式调用的工作。
跟踪由两个基本组件组成:
- Span 描述发生在服务上的操作或 “work”。Span 可以描述广泛的操作——例如,响应 HTTP 请求的 web 服务器的操作——也可以描述单个函数的调用。
- trace 描述了一个或多个连接 span 的端到端(end-to-end)旅程。如果 trace 连接在多个服务上执行的 span(“work”),则该 trace 被认为是分布式跟踪。
让我们看一个假设的分布式跟踪示例。
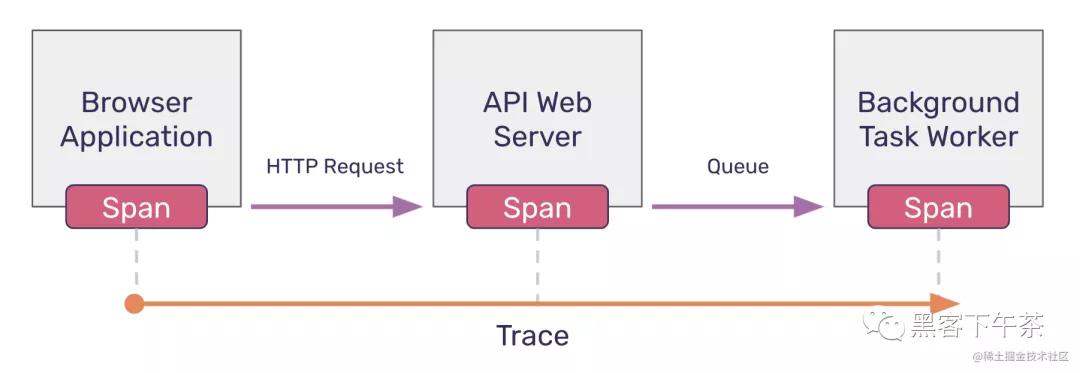
上图说明了 trace 如何从一个服务(一个在浏览器上运行的 React 应用程序)开始,并通过调用 API Web Server 继续,甚至进一步调用后台任务 worker。此图中的 span 是在每个服务中执行的 work,每个 span 都可以“追溯到(traced)”由浏览器应用程序启动的初始工作(initial work)。最后,由于这些操作发生在不同的服务上,因此该跟踪被认为是分布式的。
描述广泛操作的跨度(例如:响应 HTTP request 的 Web server 的完整生命周期)有时被称为事务跨度(transaction spans),甚至只是事务。我们将在本系列的第 2 部分中更多地讨论事务与跨度(transactions vs. spans)。
跟踪和跨度标识符
到目前为止,我们已经确定了跟踪的组件,但我们还没有描述这些组件是如何链接在一起的。
首先,每个跟踪都用跟踪标识符(trace identifier)唯一标识。这是通过在根跨度(root span)中创建一个唯一的随机生成值(即 UUID)来完成的——这是启动整个跟踪的初始操作。在我们上面的示例中,根跨度出现在浏览器应用程序中。
其次,每个 span 首先需要被唯一标识。这通过在跨度开始其操作时创建唯一的跨度标识符(或 span_id)来完成。这个 span_id 创建应该发生在 trace 内发生的每个 span(或操作)处进行。
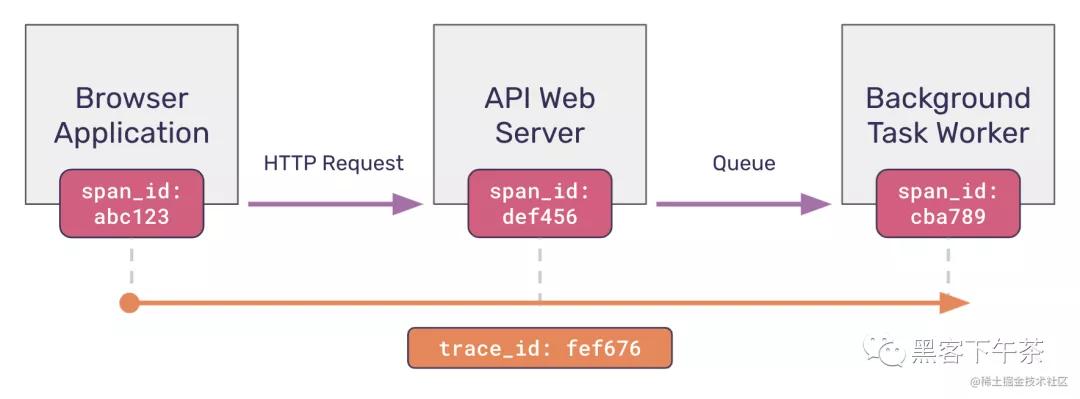
让我们重新审视我们假设的跟踪示例。在上图中,您会注意到跟踪标识符唯一地标识了跟踪,并且该跟踪中的每个跨度也拥有一个唯一的跨度标识符。
然而,生成 trace_id 和 span_id 是不够的。要实际连接这些服务,您的应用程序必须在从一个服务向另一个服务发出请求时传播所谓的跟踪上下文(trace context)。
跟踪上下文
跟踪上下文(trace context)通常仅由两个值组成:
- 跟踪标识符(或 trace_id):在根跨度中生成的唯一标识符,用于标识整个跟踪。这与我们在上一节中介绍的跟踪标识符相同;它以不变的方式传播到每个下游服务。
- 父标识符(或 parent_id):产生当前操作的“父”跨度的 span_id。
下图显示了在一个服务中启动的请求如何将跟踪上下文传播到下游的下一个服务。您会注意到 trace_id 保持不变,而 parent_id 在请求之间发生变化,指向启动最新操作的父跨度。
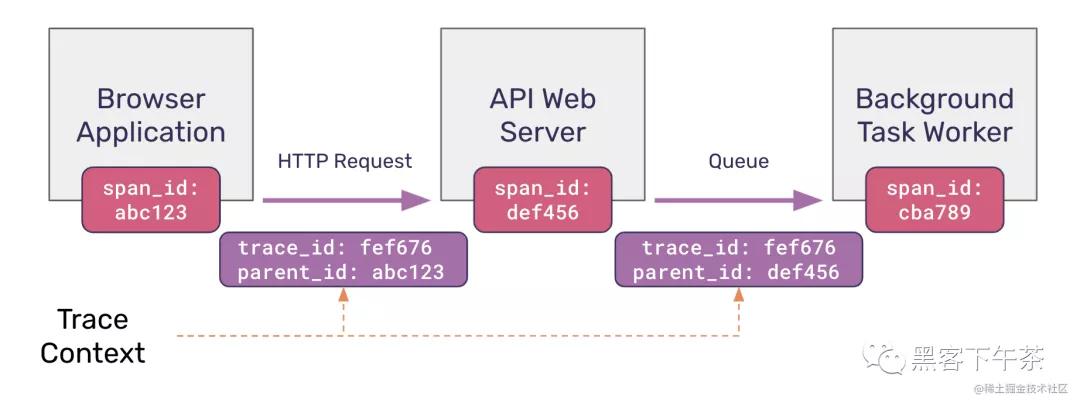
有了这两个值,对于任何给定的操作,就可以确定原始(root)服务,并按照导致当前操作的顺序重建所有父/祖先(parent/ancestor)服务。
工作示例(代码演示)
示例源码:
- https://github.com/getsentry/distributed-tracing-examples
为了更好地理解这一点,让我们实际实现一个基本的跟踪实现,其中浏览器应用程序是由跟踪上下文连接的一系列分布式操作的发起者。
首先,浏览器应用程序呈现一个表单:就本示例而言,是一个“邀请用户(invite user)”表单。表单有一个提交事件处理程序,它在表单提交时触发。让我们将此提交处理程序视为我们的根跨度(root span),这意味着当调用处理程序时,会生成 trace_id 和 span_id。
接下来,完成一些工作以从表单中收集用户输入的值,然后最后向我们的 Web 服务器发出一个到 /inviteUser API 端点的 fetch 请求。作为此 fetch 请求的一部分,跟踪上下文作为两个自定义 HTTP header 传递:trace-id 和 parent-id(即当前 span 的 span_id)。
- // browser app (JavaScript)
- import uuid from 'uuid';
- const traceId = uuid.v4();
- const spanId = uuid.v4();
- console.log('Initiate inviteUser POST request', `traceId: ${traceId}`);
- fetch('/api/v1/inviteUser?email=' + encodeURIComponent(email), {
- method: 'POST',
- headers: {
- 'trace-id': traceId,
- 'parent-id': spanId,
- }
- }).then((data) => {
- console.log('Success!');
- }).catch((err) => {
- console.log('Something bad happened', `traceId: ${traceId}`);
- });
请注意,这些是用于说明目的的非标准 HTTP header。作为 W3C traceparent 规范的一部分,正在积极努力标准化 tracing HTTP header,该规范仍处于 “Recommendation” 阶段。
- https://www.w3.org/TR/trace-context/
在接收端,API web server 处理请求并从 HTTP 请求中提取跟踪元数据(tracing metadata)。然后它会排队一个 job 以向用户发送电子邮件,并将跟踪上下文作为 job 描述中“meta”字段的一部分附加。最后,它返回一个带有 200 状态 code 的响应,表明该方法成功。
请注意,虽然服务器返回了成功的响应,但实际的“工作”直到后台任务 worker 拿起新排队的 job 并实际发送电子邮件后才完成。
在某个点上,队列处理器开始处理排队的电子邮件作业。再一次,跟踪(trace)和父标识符(parent identifier)被提取出来,就像它们在 web server 中的早些时候一样。
- // API Web Server
- const Queue = require('bull');
- const emailQueue = new Queue('email');
- const uuid = require('uuid');
- app.post("/api/v1/inviteUser", (req, res) => {
- const spanId = uuid.v4(),
- traceId = req.headers["trace-id"],
- parentId = req.headers["parent-id"];
- console.log(
- "Adding job to email queue",
- `[traceId: ${traceId},`,
- `parentId: ${parentId},`,
- `spanId: ${spanId}]`
- );
- emailQueue.add({
- title: "Welcome to our product",
- to: req.params.email,
- meta: {
- traceId: traceId,
- // the downstream span's parent_id is this span's span_id
- parentId: spanId,
- },
- });
- res.status(200).send("ok");
- });
- // Background Task Worker
- emailQueue.process((job, done) => {
- const spanId = uuid.v4();
- const { traceId, parentId } = job.data.meta;
- console.log(
- "Sending email",
- `[traceId: ${traceId},`,
- `parentId: ${parentId},`,
- `spanId: ${spanId}]`
- );
- // actually send the email
- // ...
- done();
- });
分布式系统 Logging
您会注意到,在我们示例的每个阶段,都会使用 console.log 进行 logging 调用,该调用还发出当前 trace、span 和 parent 标识符。在完美的同步世界中——每个服务都可以登录到同一个集中式 logging 工具——这些日志语句中的每一个都会依次出现:

如果在这些操作过程中发生异常或错误行为,使用这些或额外的日志语句来查明来源将相对简单。但不幸的现实是,这些都是分布式服务,这意味着:
Web 服务器通常处理许多并发请求。Web 服务器可能正在执行归因于其他请求的工作(并发出日志记录语句)。
网络延迟会影响操作顺序。从上游服务发出的请求可能不会按照它们被触发的顺序到达目的地。
后台 worker 可能有排队的 job。在到达此跟踪中排队的确切 job 之前,worker 可能必须先完成先前排队的 job。
在一个更现实的例子中,我们的日志调用可能看起来像这样,它反映了同时发生的多个操作:

如果不跟踪 metadata,就不可能了解哪个动作调用哪个动作的拓扑结构。但是通过在每次 logging 调用时发出跟踪 meta 信息,可以通过过滤 traceId 快速过滤跟踪中的所有 logging 调用,并通过检查 spanId 和 parentId 关系重建确切的顺序。
这就是分布式跟踪的威力:通过附加描述当前操作(span id)、产生它的父操作(parent id)和跟踪标识符(trace id)的元数据,我们可以增加日志记录和遥测数据以更好地理解 分布式服务中发生的事件的确切顺序。
在真实的分布式跟踪环境中
在本文的过程中,我们一直在使用一个有点人为的示例。在真正的分布式跟踪环境中,您不会手动生成和传递所有的跨度和跟踪标识符。您也不会依赖 console.log(或其他日志记录)调用来自己发出跟踪元数据。您将使用适当的跟踪库来为您处理检测和发送跟踪数据。
OpenTelemetry
OpenTelemetry 是一组开源工具、API 和 SDK,用于检测、生成和导出正在运行的软件中的遥测数据。它为大多数流行的编程语言提供了特定于语言的实现,包括浏览器 JavaScript 和 Node.js。
- https://opentelemetry.io/
- https://github.com/open-telemetry/opentelemetry-js
Sentry
Sentry 以多种方式使用这种遥测。例如,Sentry 的性能监控功能集使用跟踪数据生成瀑布图,说明跟踪中分布式服务操作的端到端延迟。
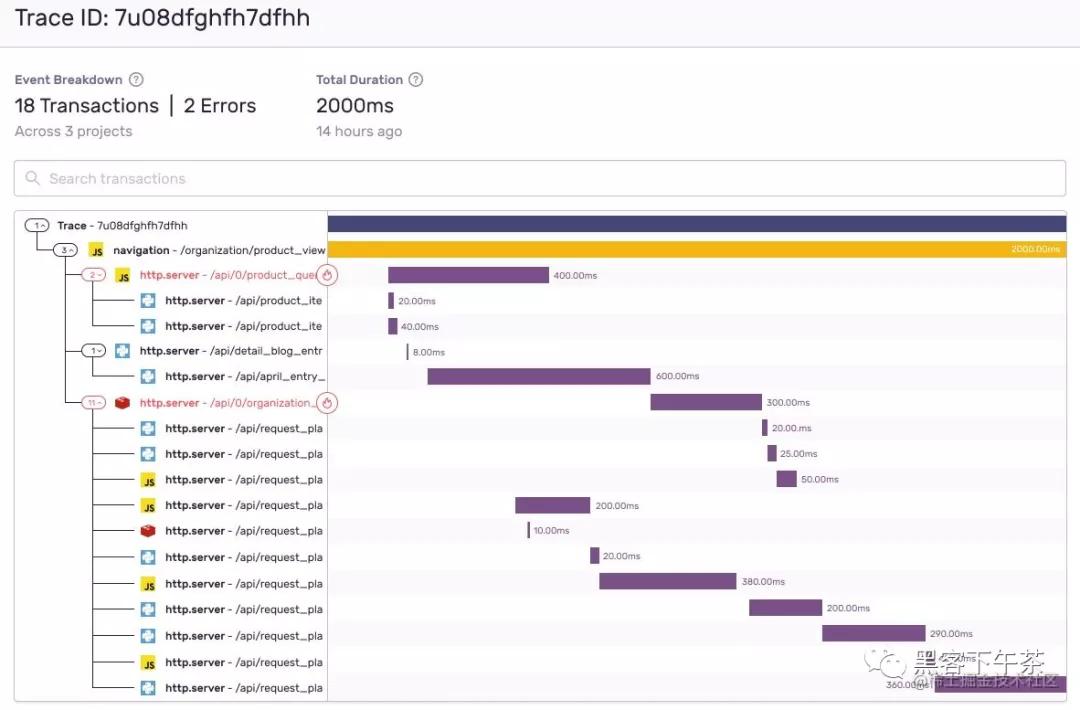
Sentry 还使用跟踪元数据来增强它的错误监控功能,以了解在一个服务(如服务器后端)中触发的错误如何传播到另一个服务(如前端)中的错误。