背景
先讲一下背景,再说原因
大多数库都会在日志中使用chalk库为console的内容进行上色
被chalk处理后,其原本的内容会被‘\x1B...’所包裹
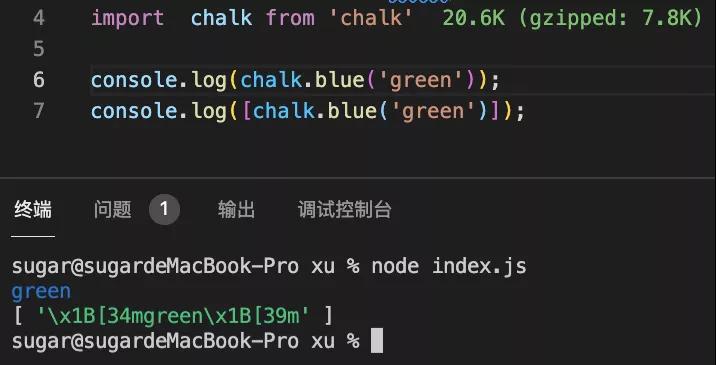
- console.log(chalk.blue('green'));
- console.log([chalk.blue('green')]);
图片
在开发vite-plugin-monitor[1]时,为了获取原始的日志内容(上色之前),需要将上色后的字符串还原
- \x1B[34mgreen\x1B[39m => green
在使用正则处理内容的时候发现了一个问题
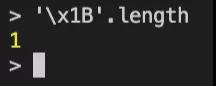
- '\x1B'.replace(/\\x/,'') // 结果??
通过.length查看其长度,结果就如标题所示
原因
反斜杠"\"通常标识转义字符,如\n(换行符),\t(制表符)
而\x就标识16进制,后面跟上两位16进制数
与此同时还有\u也是标识16进制,但其后面需跟上4位16进制数
因此这里的\x1B实际上就是一个字符
- '\x41' === 'A' // true
- 'A' === '\u0041' // true
\x
\xhh匹配一个以两位十六进制数(\x00-\xFF)表示的字符
主要用于ASCII码[2]的表示
- '\x41' === ‘A’
- 'A' === String.fromCharCode(65)
- '\x61' === ‘a’
- 'a' === String.fromCharCode(97)
\x后必须跟着两位16进制的字符,否则会报错,其中 A-F 不区分大小写
- '\x1' // Uncaught SyntaxError: Invalid hexadecimal escape sequence
- '\xfg' // Uncaught SyntaxError: Invalid hexadecimal escape sequence
\u
\uhhhh匹配一个以四位十六进制数(\u0000-\uFFFF)表示的 Unicode 字符。
在正则表达式中常见于匹配中文字符
- const r = /[\u4e00-\u9fa5]/
- r.test('中文') // true
- r.test('English') // false
常规字符与Unicode字符互转
str2Unicode
使用String.prototype.charCodeAt获取指定位置的 Unicode 码点(十进制表示)
使用String.prototype.toString将其转为十六进制字符,转为16进制字符不会自动补0
通过String.prototype.padStart进行补0
编写的通用处理方法如下
- function str2Unicode(str) {
- let s = ''
- for (const c of str) {
- s += `\\u${c.charCodeAt(0).toString(16).padStart(4, '0')}`
- }
- return s
- }
- str2Unicode('1a中文') // '\\u0031\\u0061\\u4e2d\\u6587'
unicode2Str
通过正则/\\u[\da-f]{4}/g匹配出所有的unicode字符
- 使用Number将0x${matchStr}转换为10进制数
- 使用String.fromCodePoint将unicode码点转为字符
- 使用String.prototype.replace进行逐字符的转换
- function str2Unicode(str) {
- let s = ''
- for (const c of str) {
- s += `\\u${c.charCodeAt(0).toString(16).padStart(4, '0')}`
- }
- return s
- }
- str2Unicode('1a中文') // '\\u0031\\u0061\\u4e2d\\u6587'
还原chalk处理后的字符串
自己从0-1写一个正则难免会有许多边界情况考虑不周全,于是在chalk的README中找到了chalk/ansi-regex[3]这个库
可以将色值相关的 ANSI转义码 匹配出来
- import ansiRegex from 'ansi-regex';
- '\u001B[4mcake\u001B[0m'.match(ansiRegex());
- //=> ['\u001B[4m', '\u001B[0m']
- '\u001B[4mcake\u001B[0m'.match(ansiRegex({onlyFirst: true}));
- //=> ['\u001B[4m']
编写一下处理方法
- function resetChalkStr(str) {
- return str.replace(ansiRegex(), '')
- }
测试
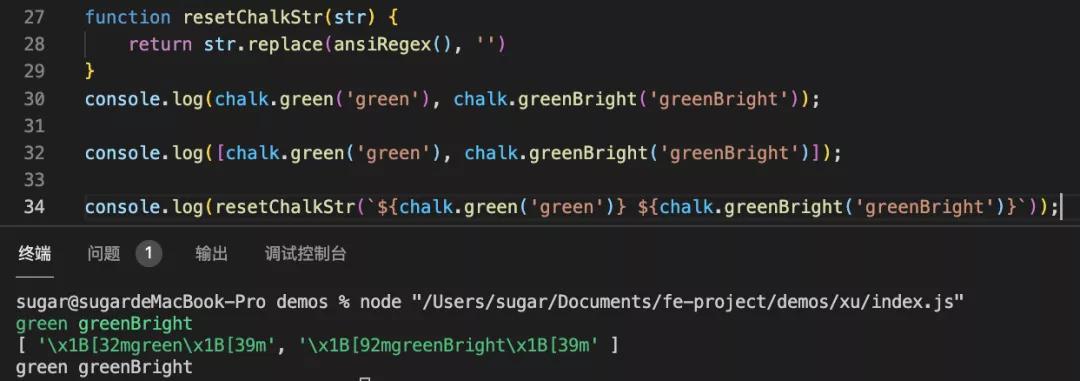
- console.log(chalk.green('green'), chalk.greenBright('greenBright'));
- console.log([chalk.green('green'), chalk.greenBright('greenBright')]);
- console.log(resetChalkStr(`${chalk.green('green')} ${chalk.greenBright('greenBright')}`));
总结
重拾了一下\x与\u相关的内容,突然额外想到一个点,使用\u去做字符串的加解密(下来再捋一捋)
解决了一个chalk相关的问题“还原终端中的彩色内容”
参考资料
[1]vite-plugin-monitor: https://github.com/ATQQ/vite-plugin-monitor
[2]ASCII码: https://tool.oschina.net/commons?type=4
[3]chalk/ansi-regex: https://github.com/chalk/ansi-regex