












本文转载自微信公众号「数仓宝贝库」,作者范钢 孙玄 。转载本文请联系数仓宝贝库公众号。
前面部分是对数据的采集,然后经过ETL过程,最终存入数据仓库。这部分是通过一切手段收集数据,然而它的建设与数据应用需求无关。因为数据仓库存储的是过去数年的数据,而数据应用需求总是在变。如果数据应用需求一变化,就需要修改数据仓库的表结构,那么这数年的数据都必须要重新计算,系统就会始终处于一种十分不稳定的状态,维护成本极高。所以,只有数据仓库的建设与数据应用需求无关,才能保证需求变更对数据仓库没有影响,才能让系统稳定运行。
后面部分是根据不同的数据分析需求,从数据仓库中获取数据,完成各自的数据分析,将最终的分析结果写入数据集市。数据集市的建设是与各自的数据分析的需求息息相关的,每次需求变更时,变更的是各自的数据集市,而不是数据仓库。
01多维数据建模
经过前面一系列的ETL过程(什么是ETL?一文掌握ETL设计过程),我们最终将数据装载到数据仓库中。数据仓库是按照多维数据模型的思路进行建设的。在多维数据模型中,动态数据就转化为了事实表,静态数据就转化为了维度表。进项发票事实表、销项发票事实表都是事实表,但从其中关联出来了日期维度表、纳税人维度表、税务机关维度表、地域维度表与行业维度表。
多维数据模型的设计有两种思路:雪花模型与星形模型,如下图所示。
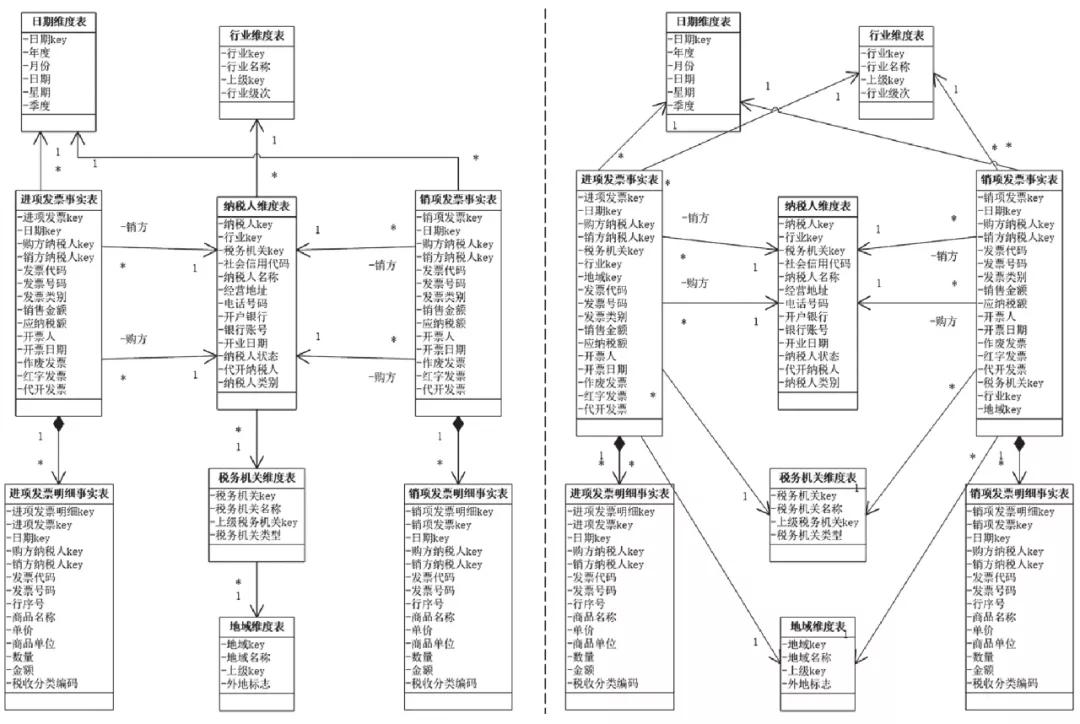
雪花模型与星形模型
左图是雪花模型的设计,它最大的特点是在维度表上还要关联维度表,如在纳税人维度表的基础上还要关联行业维度表。这样设计比较容易理解,但会造成频繁的join操作,在海量数据中降低查询性能。譬如,要对进项发票进行地域的统计,就需要将进项发票事实表与纳税人维度表相关联,再关联税务机关维度表、地域维度表,才能完成,这极大影响了系统性能。因此,为了提升查询性能,基于空间换时间的思想,我们又提出了星形模型。
右图是星形模型的设计,它最大的特点是不会再有维度与维度的关联,而是所有维度表都只与事实表关联。譬如对进项发票进行地域分析,只需要进项发票事实表关联地域维度表就可以了,在海量数据中的性能将得到极大的提升。
接着,在以上事实表的基础上,还可以从不同的维度与粒度对数据进行汇总,形成聚合表。譬如,对进项发票事实表按照行业进行汇总,或者按照地域进行汇总,形成“进项发票行业聚合表”与“进项发票地域聚合表”,等等。
以上的分析都是在“开票主题域”中进行的,但是按照业务流程,还有“申报主题域”“征收主题域”“稽查主题域”等,如下图所示。这样,数据中台就按照业务模块划分为了多个主题域,然后在各个主题域进行多维建模,形成数据仓库。但各个主题域可以拥有共同的维度表,如纳税人维度表、税务机关维度表等。

主题域模型
02数据中台的分层
数据中台的建设,除了按照主题域进行纵向划分,还要通过分层进行横向划分。数据中台通过分层,划分为原始数据层(STAGE)、细节数据层(ODS/DWD)、轻度综合层(MID/DWS)与数据集市层(DM),如下图所示。每一层的数据都存储在Hive数据库中,然后通过Schema划分出不同的层次。
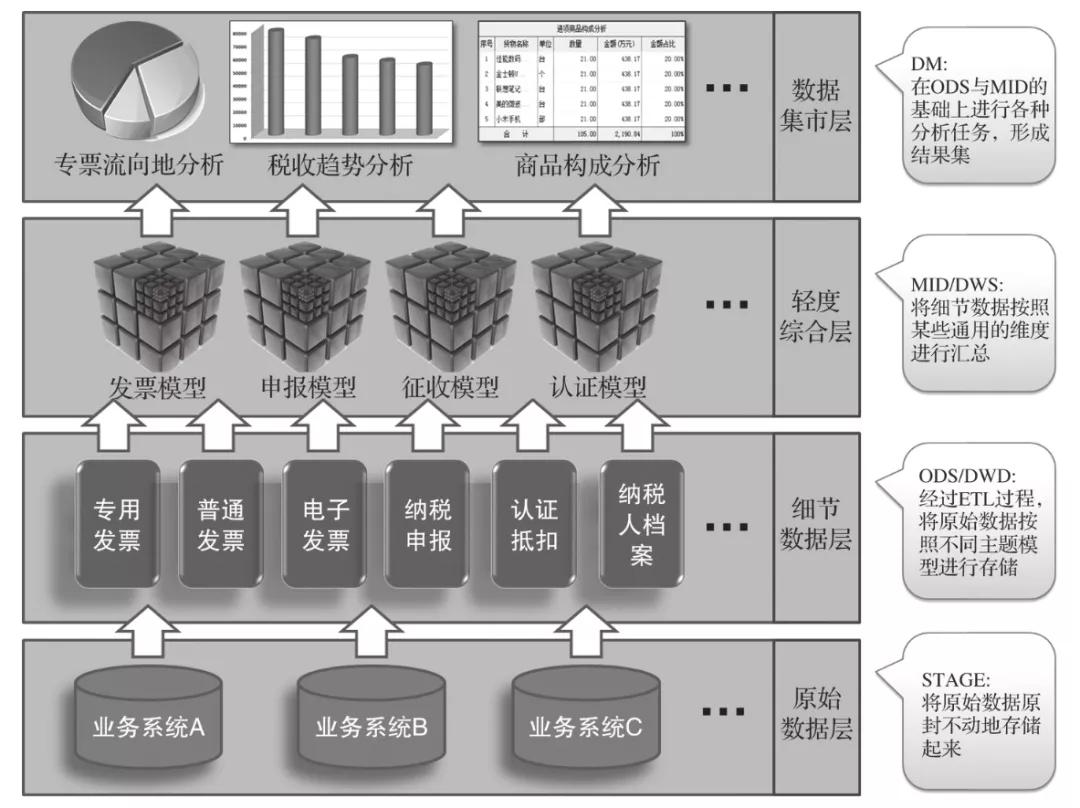
数据中台的系统分层
最底层是原始数据层(STAGE)。所有的原始数据都在这里,通过Schema进行划分,来自哪个数据来源就存储在哪个Schema中,并且表名与原始库的表名一致。
接着是细节数据层(ODS/DWD),它是经过ETL过程以后导入数据仓库的事实表与维度表。ETL过程的中间临时表存入名为etl的Schema,数据仓库的事实表与维度表存入名为dw的Schema。同时,制订命名规范,事实表以dw_fact_xxx命名,如订单事实表dw_fact_order,维度表以dw_dim_xxx命名,如日期维度表dw_dim_date。
紧接着是轻度综合层(MID/DWS),它是在事实表的基础上按照不同维度与粒度形成的聚合表。聚合表以dw_agg_xxx命名,如进项发票按纳税人聚合表dw_agg_jxfp_nsr、进项发票按税务机关聚合表dw_agg_jxfp_swjg等。
最后,是在数据仓库之上的数据集市层(DM),它通过抽取前两层中的事实表与聚合表的数据,按照不同的用户需求进行数据分析,最后形成数据结果。数据集市既包括最终结果表,也包括中间结果表。数据集市以dw_dm_xxx命名,如“购车人未缴纳车辆购置税预警”属于“机动车消费税”分析模块,它需要计算出应免税数据dw_dm_jdcxfs_ms,然后计算出未缴税数据dw_dm_jdcxfs_wjs。大多数常规数据分析就是这样通过SparkSQL进行的。
本书摘编自《架构真意:企业级应用架构设计方法论与实践》,经出版方授权发布。



















