随着神经网络模型和训练数据规模的增长,训练效率正成为深度学习的一个重要焦点。
GPT-3 在小样本学习中表现出卓越的能力,但它需要使用数千个 GPU 进行数周的训练,因此很难重新训练或改进。
相反,如果可以设计出更小、更快、但更准确的神经网络会怎样?
Google 就提出了两类通过神经架构和基于模型容量和泛化性的原则性设计方法(principled design methodology)得到的神经网络模型用来图像识别。
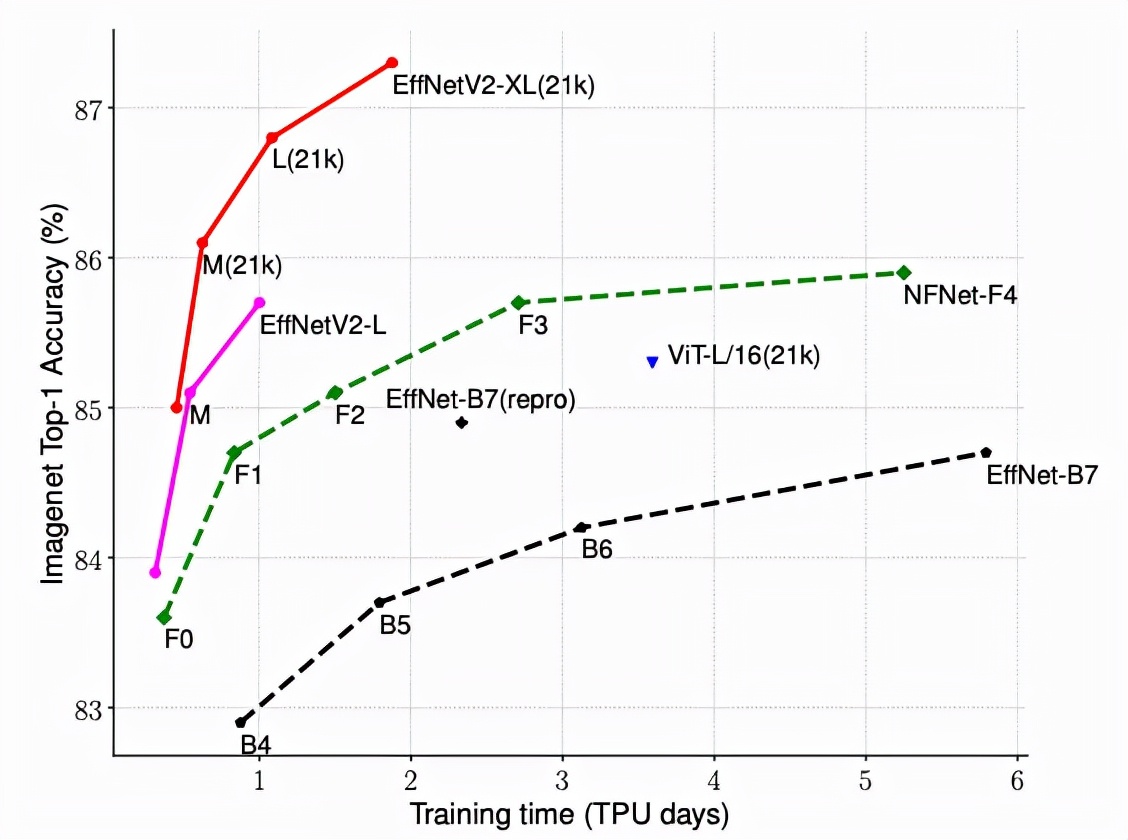
第一个是ICML 2021上提出的EfficientNetV2,主要由卷积神经网络组成,旨在为相对较小的数据集(如ImageNet1k,有128万张图像)提供更快的训练速度。

EfficientNet V2基于以前的EfficientNet架构,为了改进原有的方法,Google 研究团队系统地研究了现代模型TPU/GPU上的训练速度瓶颈,有几个发现:
1、使用非常大的图像进行训练会导致更高的内存使用率,从而导致TPU/GPU上的训练速度通常较慢;
2、广泛使用的深度卷积在TPU/GPU上效率低下,因为它们的硬件利用率较低;
3、常用的uniform compound scaling将卷积网络的每个阶段平均放大,但这并不是最优方法。
为了解决这些问题,研究人员提出了一种面向训练感知的神经架构搜索(train-aware NAS),其中训练速度也包含在优化目标中,并且使用一种以非均匀方式在不同阶段进行缩放,模型代码也已开源。
文章的第一作者是Mingxing Tan,
训练感知 NAS 的架构基于之前的平台感知 platform-aware NAS,但与原方法主要关注推理速度不同,训练感知 NAS 同时优化模型精度、模型大小和训练速度。
模型还扩展了原始搜索空间以包含更多对加速器有利的操作,例如 FusedMBConv 通过删除不必要的操作(例如 平均池化和最大池化)来简化搜索空间。
由此产生的 EfficientNetV2 网络在所有以前的模型上都实现了更高的准确性,同时速度更快,体积缩小了 6.8 倍。
为了进一步加快训练过程,研究人员还提出了一种增强的渐进学习方法(progressive learning),该方法在训练过程中逐渐改变图像大小和正则化幅度。
渐进式训练已用于图像分类、GANs和语言模型,并取得了不错的效果。该方法侧重于图像分类,但与以前的方法不同的是,之前的方法通常以精度换取更高的训练速度,它可以略微提高精度,同时显著减少训练时间。
改进方法的关键思想是根据图像大小自适应地改变正则化强度,如dropout 的概率或数据增强程度。对于相同的网络,较小的图像大小导致网络容量较低,因此需要弱正则化;反之亦然,较大的图像大小需要更强的正则化来防止过度拟合。

在 ImageNet 和一些迁移学习数据集上,例如 CIFAR-10/100、Flowers 和 Cars 来评估 EfficientNetV2 模型。在 ImageNet 上,EfficientNetV2 显着优于以前的模型,训练速度提高了约 5-11 倍,模型尺寸缩小了 6.8 倍,准确率没有任何下降。
第二类是CoAtNet,一种结合了卷积和自注意的混合模型,其目标是在大规模数据集上实现更高的精度,如ImageNet21(有1300万张图像)和JFT(有数十亿张图像)。

虽然EfficientNetV2仍然是一个典型的卷积神经网络,但最近对视觉Transformer(visual Transformer, ViT)的研究表明,基于注意的Transfomer 模型在JFT-300M等大规模数据集上的性能优于卷积神经网络。
受这一观察结果的启发,研究人员进一步将研究范围扩展到卷积神经网络之外,以期找到更快、更准确的视觉模型。
研究者系统地研究如何结合卷积和自注意力来开发用于大规模图像识别的快速准确的神经网络。工作结果基于一个观察结论,即卷积由于其归纳偏差(inductive bias)通常具有更好的泛化能力(即训练和评估之间的性能差距),而自注意力Transformer由于其对全局建模的能力更强,所以往往具有更强大的概括能力(即适应大规模训练的能力) 。
通过结合卷积和自注意力,得到的混合模型可以实现更好的泛化和更大的容量。
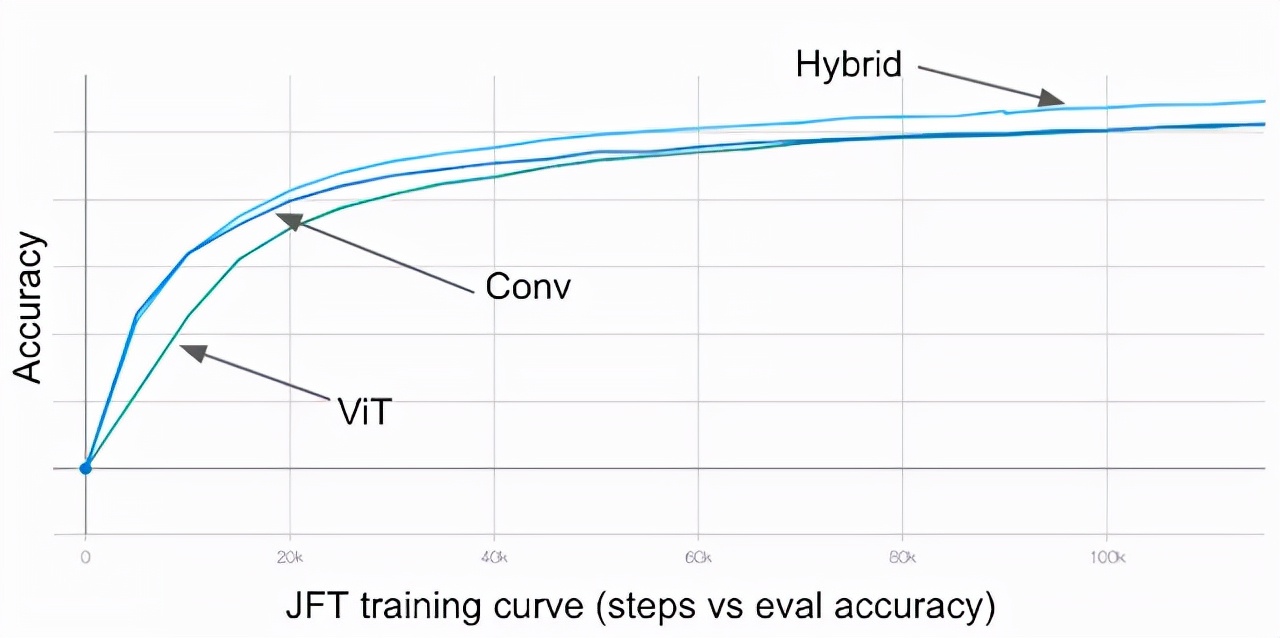
深度卷积和自注意力可以通过简单的相对注意力自然地统一起来,并且垂直堆叠卷积层和注意力层,可以同时考虑到每个阶段所需的容量和计算能力,从而提高泛化性、容量和效率。
在 CoAtNet 架构中,给定大小为 HxW 的输入图像,首先在第一个stem阶段 (S0) 应用卷积并将大小减小到 H/2 x W/2。尺寸随着每个阶段继续减小。Ln 是指层数。前两个阶段(S1和S2)主要采用深度卷积组成的MBConv构建块。后两个阶段(S3和S4)主要采用具有relative self-attention的Transformer块。与之前 ViT 中的 Transformer 块不同,这里使用阶段之间的池化,类似于 Funnel Transformer。最后,我们分类头来生成类别预测概率。

CoAtNet 模型在许多数据集(例如 ImageNet1K、ImageNet21K 和 JFT)中始终优于 ViT 模型及其变体。与卷积网络相比,CoAtNet 在小规模数据集 (ImageNet1K) 上表现出相当的性能,并且随着数据大小的增加(例如在 ImageNet21K 和 JFT 上)取得了可观的收益。
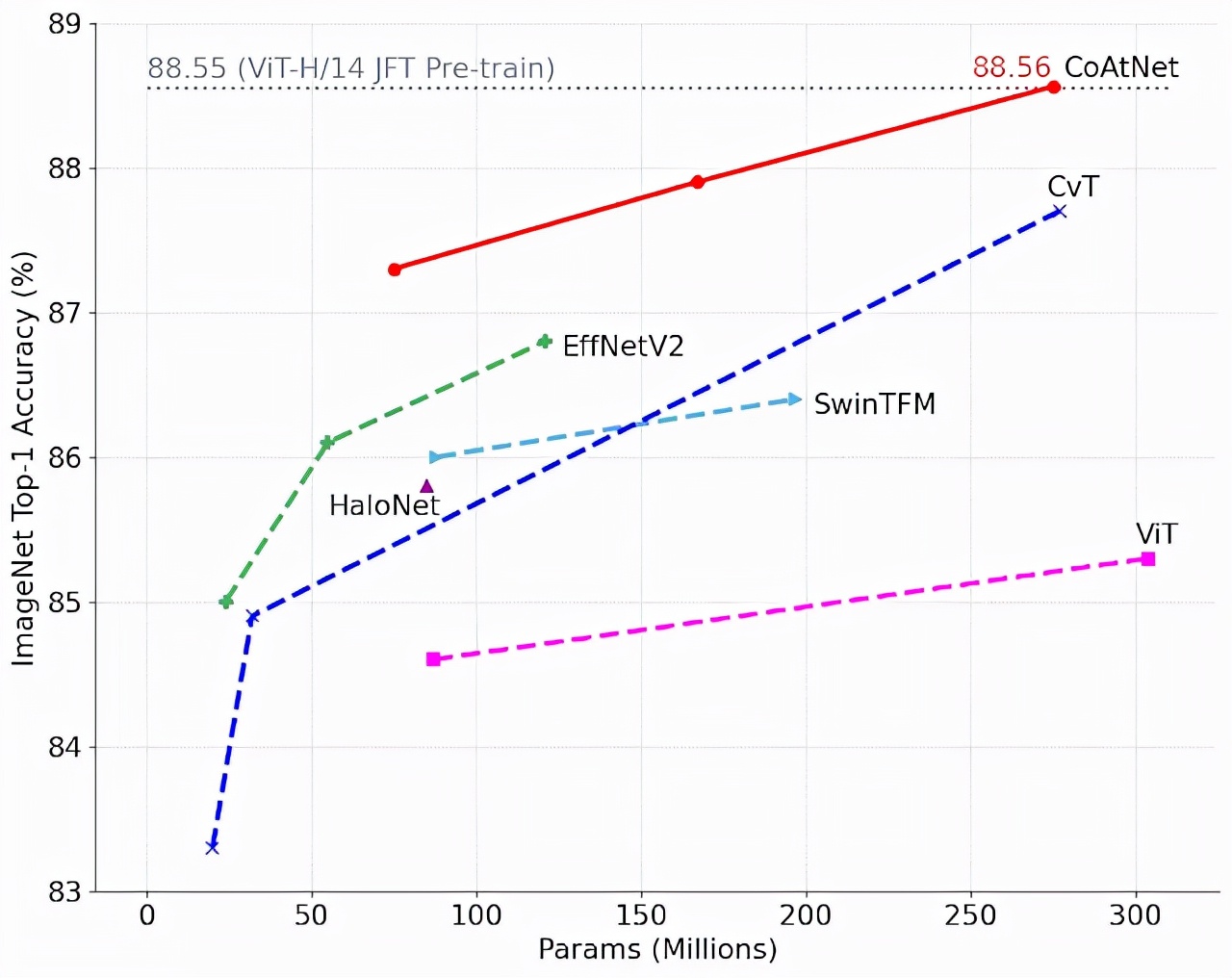
研究人员还在大规模 JFT 数据集上评估了 CoAtNets。为了达到类似的准确度目标,CoAtNet 的训练速度比以前的 ViT 模型快 4 倍,更重要的是,在 ImageNet 上达到了 90.88% 的新的最先进的 top-1 准确度。
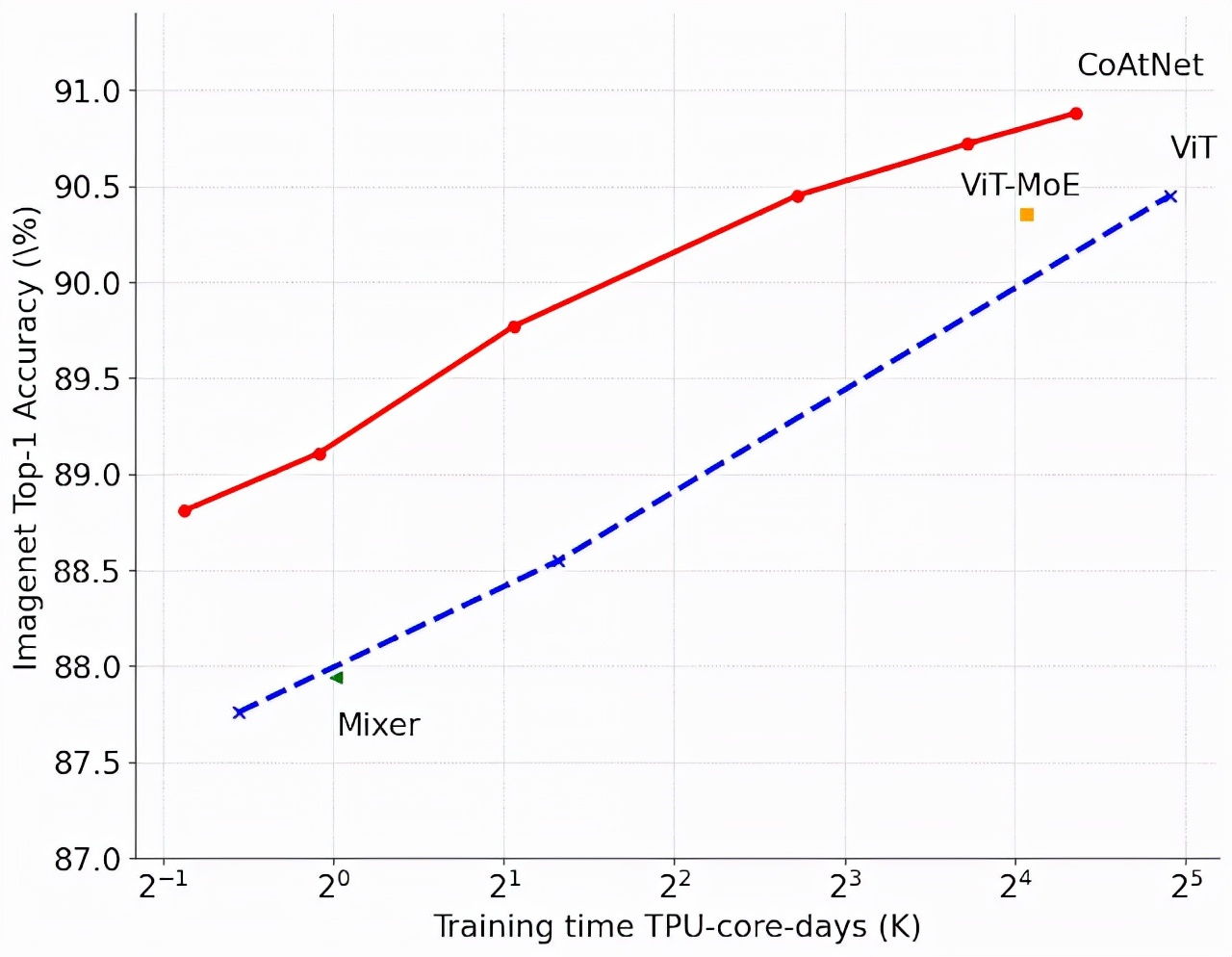
与以前的结果相比,新提出的模型速度快了4-10倍,同时在完善的ImageNet数据集上实现了最先进的90.88%top-1精度。