调参、改激活函数提高模型性能已经见怪不改了。最近Google Brain的首席Quoc发布了一个搜索框架,能够自动搜索高效率的Transformer变体,并找到一些有效的模型Primer,其中ReLU加个平方竟然能提升最多性能!
目前自然语言处理领域发展的红利都来自于大型的、基于Transformer的语言模型,但这些语言模型的训练成本、推理成本都高到劝退平民炼金术师。
而当模型参数量大到一定程度的时候,研究人员也在考虑如何在缩小模型的情况下,保持性能不变。
Google Brain团队最近在arxiv 上传了一篇论文,目标是通过寻找更高效的Transformer 变体来降低训练和推理成本。
与之前的方法相比,新提出的方法在更低级别上执行搜索,在Tensorflow 程序的原语上定义和搜索 Transformer。并提出了一种名为 Primer 的模型架构,训练成本比原始 Transformer 和用于自回归语言建模的其他模型变体要更小。

https://arxiv.org/abs/2109.08668
论文的作者是大神 Quoc V. Le,在斯坦福读博期间导师是吴恩达教授,目前是谷歌的研究科学家,Google Brain 的创始成员之一;seq2seq的作者之一;谷歌AutoML的奠基人,提出包括神经架构等方法;EfficientNet的作者等。
研究人员使用TensorFlow(TF)中的操作来构造Transformer 变体的搜索空间。在这个搜索空间中,每个程序定义了自回归语言模型的可堆叠解码器块。给定输入张量是一个长度为n且嵌入长度为d的序列,程序能够返回相同形状的张量。
堆叠时,其输出表示每个序列位置的下一个token的预测embedding,并且程序只指定模型架构,没有其他内容。换句话说,输入和输出embedding矩阵本身以及输入预处理和权重优化不在这个程序的任务范围内。
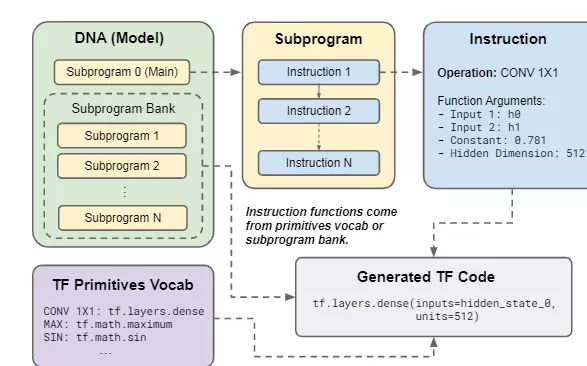
解码器模型程序(DNA, decoder model program)定义了一个自回归语言模型,每个DNA都有一组子程序,其中子程序0是MAIN函数的入口点。每个子程序都由指令组成,这些指令被转换为TensorFlow代码行。
指令操作映射到原语词汇表中的基本TensorFlow库函数或父DNA子程序之一,原语词汇表由简单的原语TF函数组成,如ADD、LOG、MATMUL等等,但像self-attention这样的高级构建块不是搜索空间中的操作,自注意力可以从低级操作中构建出来的。
DNA的子程序库由附加程序组成,这些程序可以通过指令作为函数执行。每个子程序只能调用子程序库中索引较高的子程序,这样就消除了循环的可能性。
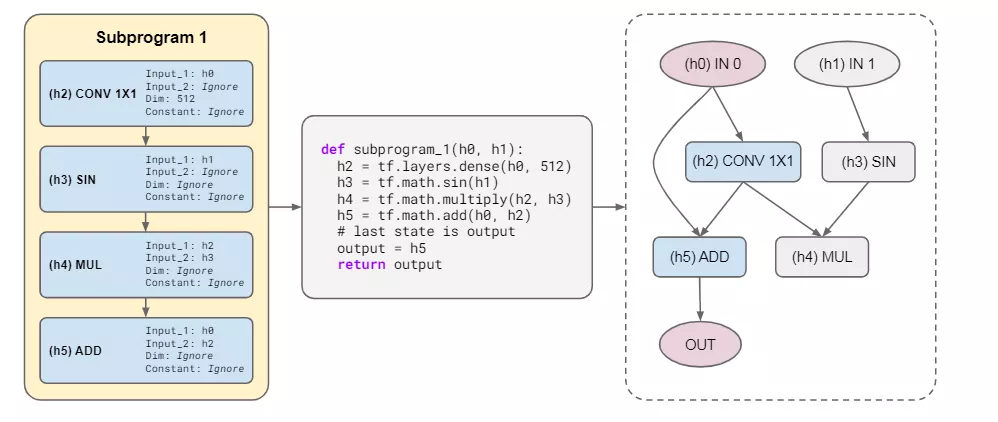
使用父指令的参数集填充操作的参数,该参数集包含所有潜在操作参数的值,参数包括Input 1( 用作第一个tensor输入的隐藏状态的索引)、Input 2(第二个tensor输入的隐藏状态的索引)、Constant(实值常数,可以用于MAX等函数)、Dimensionsize(用来表示输出维度大小的整数)。特定操作中没有使用的参数就直接被省略掉。
研究人员还提出进化搜索(evolutionary search),目标是在搜索空间中找到最有效的模型架构。主要方法是设计一个固定的训练预算(使用TPUv2限时24小时),并将其适应性指标定义为Tensor2Tensor中One Billion Words Benchmark (LM1B)上的困惑度。
这些架构搜索工作的明确目标是在优化效率时减少训练或推理步骤时间,在搜索过程中,可以发现将步长时间增加一倍、采样效率提高三倍是一个不错的修改方案,因为它最终使模型架构的计算效率更高。还可以将ReLUs平方化,并在注意力上增加深度卷积,从而增加训练步长时间。
这些操作极大地提高了模型的采样效率,通过大幅减少达到目标质量所需的训练步骤数量,减少了达到目标性能所需的总计算量。
通过这个搜索程序找到的模型被研究人员命名为Primer,也就是原语搜索Transformer(PRIMitives searched transformER)。
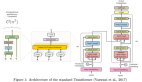
Primer 的改进主要有平方 ReLU 激活并在自注意力中的每个 Q、K 和 V 投影后添加一个深度卷积层。
最有效的修改是将变Transformer前馈块中的ReLU激活改进为平方ReLU激活函数,这也是第一次证明这种整流多项式激活在Transformer 中有用。并且高阶多项式的有效性也可以在其他Transfomer 非线性激活函数中观察到,例如GLU 的各种变体,ReGLU、近似GELU等。然而平方ReLU与最常用的激活功能相比 ReLU、GELU和Swish 具有截然不同的渐近性。
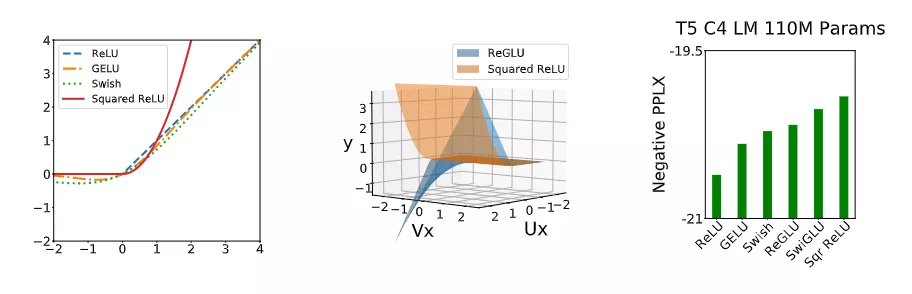
平方ReLU确实与ReGLU有显著重叠,事实上,当ReGLU的U和V权重矩阵相同时,平方ReLU与ReLU是等效的。并且平方ReLU在更简单的同时,也能获得GLU变体的好处,且无需额外参数,并提供更好的质量。
研究人员使用三个Transformer 变体与Primer 进行对比:
1、Vanilla Transformer: 原始Transformer,使用ReLU激活和layer normalization。
2、Transformer+GELU: Transformer的常用变体,使用GELU近似激活函数
3、Transformer++: 使用RMS归一化、Swish激活和GLU乘法分支在前馈反向瓶颈(SwiGLU)中。这些修改在T5 中进行了基准测试,并被表明是有效的。
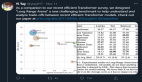
实验表明,随着计算规模的增长,Primer 相对于 Transformer 的收益会增加,并且在最佳模型大小下遵循与质量相关的幂律。
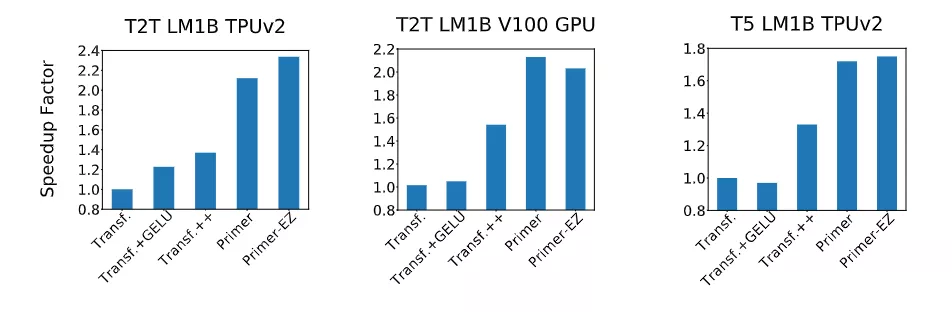
研究人员还凭经验验证了 Primer 可以放入不同的代码库,发现可以显著加快训练速度,而无需额外调整。例如,在 500M 的参数大小下,Primer 在 C4 自回归语言建模上改进了原始 T5 架构,将训练成本降低了 4 倍。
此外,降低的训练成本意味着 Primer 需要更少的计算来达到目标one shot性能。例如,在类似于 GPT-3 XL 的 1.9B 参数配置中,Primer 使用 1/3 的训练计算来实现与 Transformer 相同的一次性性能。
研究人员已经开源了模型,以帮助提论文可重复性。