刚刚,微软打造的最新图灵通用语言表示模型 T-ULRv5 模型再次成为 SOTA 模型,并在 Google XTREME 公共排行榜上位列榜首。
这项研究由 Microsoft Turing 团队和 Microsoft Research 合作完成,T-ULRv5 XL 模型具有 22 亿参数,以 1.7 分的平均分优于当前性能第二的模型(VECO)。这也是该系列模型在排行榜上的四个子类别任务中最新技术。
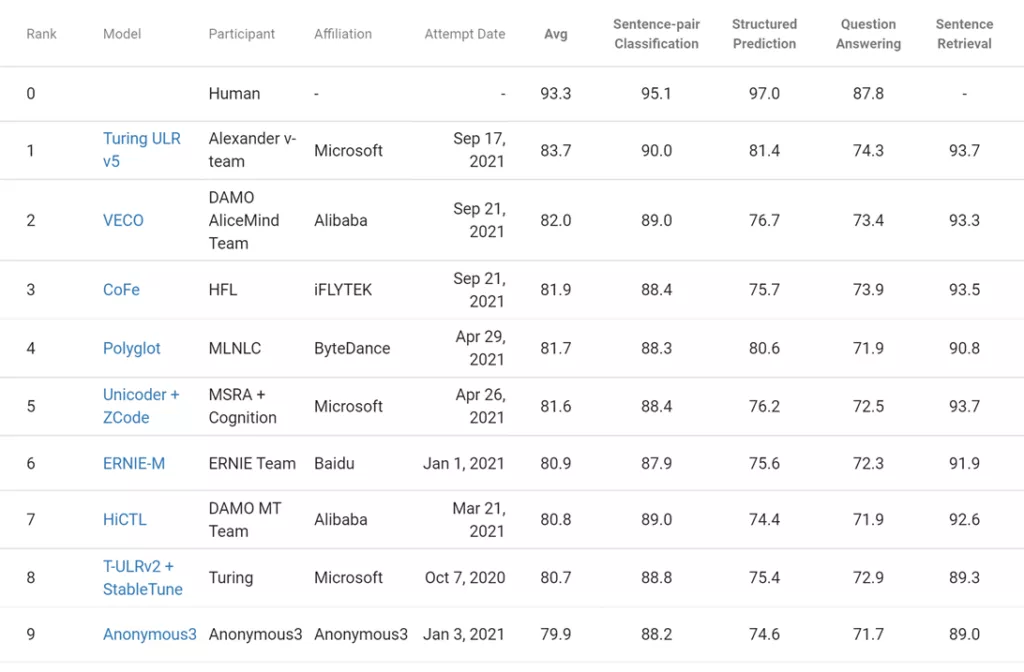
XTREME 排行榜:T-ULRv5 位居榜首。
这些结果证明了 T-ULRv5 具有强大的能力,此外,其训练速度比前几代模型快 100 倍。
这一结果标志着微软重返排行榜榜首,此前微软的 T-ULRv2 模型也曾位居 XTREME 排行榜首。为了实现这一最新结果,研究人员将 XLM-E 模型扩大到具有 22 亿参数的 XL 模型,并将其与数据、架构和优化策略方面的突破相结合,以生成最终的预训练模型。此外,研究人员还部署了称为 XTune 的先进微调技术。
XTREME(Cross-lingual TRansfer Evaluation of Multilingual Encoders)基准涵盖 40 种类型不同的语言,跨越 12 个语言家族,包括九个任务,这些任务需要对不同层次的语法或语义进行推理。之所以选择 XTREME 的语言作为基准,是为了最大限度地增加语言的多样性、现有任务的覆盖面和训练数据的可用性。
XTREME 包含的任务涵盖了一系列的范例,包括句子文本分类、结构化预测、句子检索和跨语言问答。因此,要使模型在 XTREME 基准测试中取得成功,模型必须学习适用于标准跨语言迁移设置的表示。
有关基准测试、语言和任务的完整描述,请参阅论文《 XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization 》。
T-ULRv5:高质量且高效的模型
T-ULRv5 是 Turing 模型家族的最新成员,是微软在大规模 AI 方面的代表作。这一跨语言模型结合了微软近期对 XLM-E 的研究,它能够编码来自 94 种语言的文本,并在共享向量空间中表示。大规模神经网络模型领域的前沿研究有很多条探索路线,其中之一就是模型大小,一般大模型往往比小模型表现更好。
在没有其他方面创新的情况下增加模型大小通常会导致对高成本计算的低效使用,比如更好的词汇量、更高质量的数据、新的训练任务和目标、创新的网络架构和训练优化等等。这一次,研究者在这些方面引入并整合了突破性创新,使得 T-ULRv5 成为高质量且高效的模型。
此外,T-ULRv5 还引入了一些重要创新,与其他训练的多语言模型区分开来,使得 SOTA 模型的训练效率大大提高。
模型架构、预训练和任务
T-ULRv5 同为 transformer 架构,该架构在新兴的基础模型和多语言模型(如 mBERT、mT5、XLM-R 和之前版本的 T-ULRv2)中很受欢迎。具体而言,这次预训练的最大变体 T-ULRv5 XL 具有 48 个 transformer 层、1536 个 hidden dimension size、24 个注意力头、500000 个 token 的多语言词汇量,以及参数量总共为 22 亿。
与此前的 InfoXLM 有所不同,T-ULRv5 背后的技术 XLM-E 是启发于 ELECTRA 的。它没有选择 InfoXLM 的 MMLM(多语言掩码语言建模)和 TLM(翻译语言建模)预训练任务,而是采用了两个新任务 MRTD(多语言替换 token 检测)和 TRTD(翻译替换 token 检测),目标是区分真实输入 token 和损坏的 token。
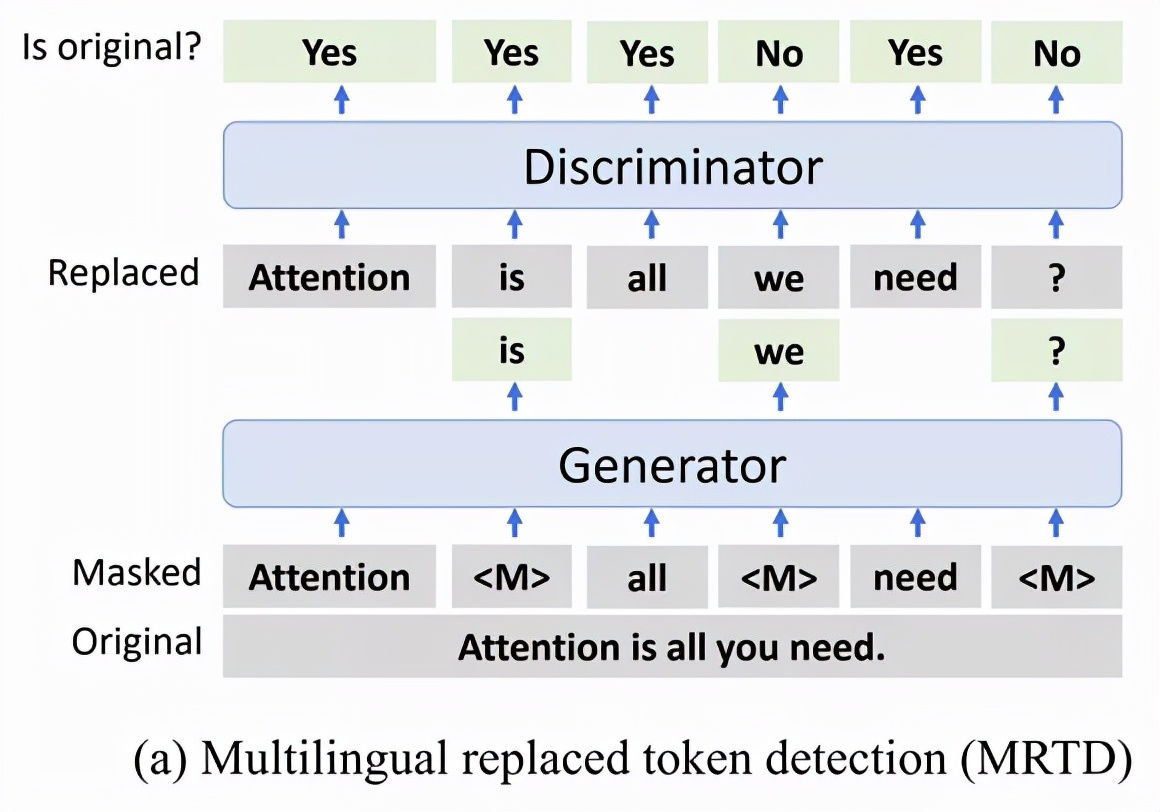
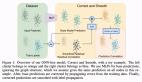
图 2:MRTD 预训练任务。生成器预测输入中的掩码 tokens,鉴别器预测每个 token 是否被生成器样本替换。
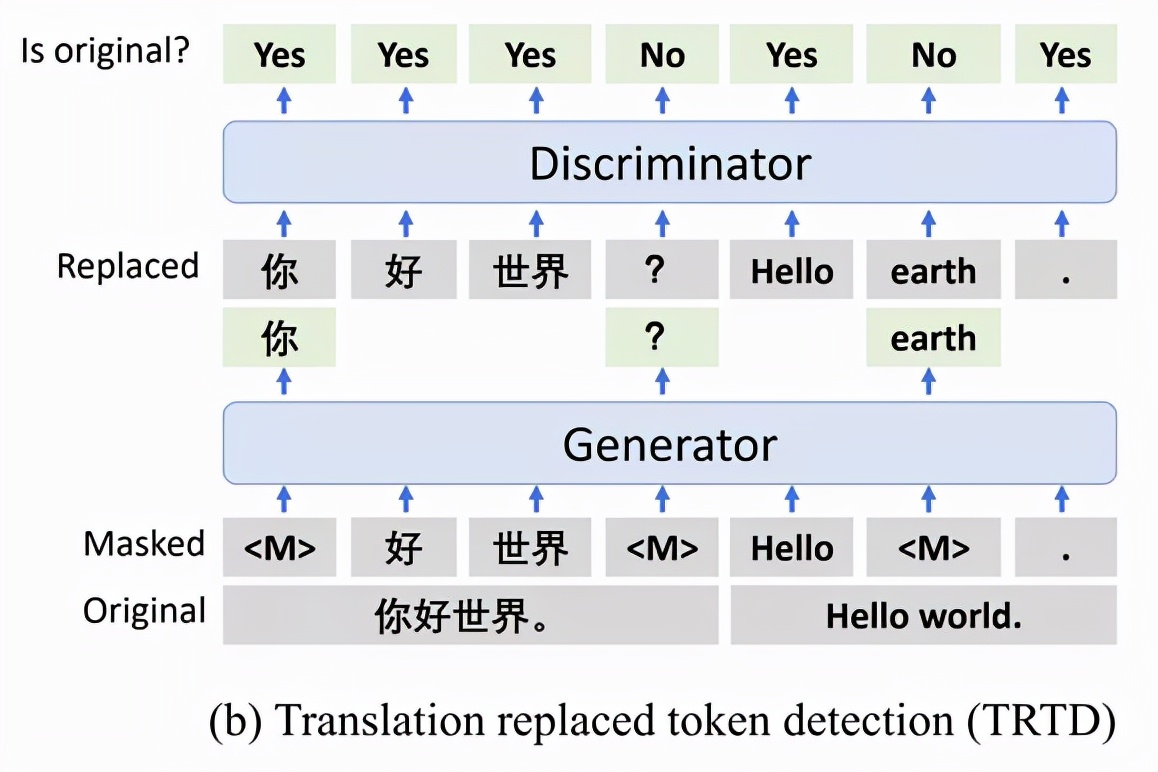
图 3:TRTD 预训练任务。生成器预测输入中翻译对上的掩码 tokens,鉴别器预测每个 token 是否被生成器样本替换。
和 ELECTRA 一样,T-ULRv5 的训练涉及两个 transformer 编码器,分别用作生成器和鉴别器。但和仅在英语数据集上训练的 ELECTRA 不同,T-ULRv5 在大规模多语言数据集上进行了训练,包括平行文本语料库。
研究者让模型通过使生成器预测单语输入和翻译对上的掩码 tokens,以更好地学习跨语言对齐和共享表征。完成预训练后,仅使用鉴别器作为文本编码器对下游任务进行微调。
训练效率提高 100 倍
现有的基于掩码语言建模 (MLM) 的跨语言预训练方法通常需要大量计算资源,成本非常昂贵。相比之下,XLM-E 的训练速度明显更快,它在各种跨语言理解任务上的表现优于基线模型,而且计算成本要低得多。例如,使用相同的语料库、代码库和模型大小(12 层),研究者将 XLM-E(在图 4 中用红线表示)与 Facebook 多语言 XLM-R 模型的内部版本进行了比较翻译语言建模(XLM-R + TLM,在图 4 中用蓝线表示)。
可以观察到, XLM-E 的训练速度提高了 130 倍以达到相同的 XNLI 精度。12 层的 XLM-E 基础模型在 64 个 NVIDIA A100 GPU 上仅用了 1.7 天就完成了训练。
在 22 亿参数的情况下,性能最佳的 T-ULRv5 XL 模型受益于 XLM-E 显著提高的训练效率,用不到两周的时间在 256 个 NVIDIA A100 GPU 上完成了训练。引入新的 TRTD 任务与 RTD 任务以及网络架构的变化相结合,提升了模型的收敛速度和质量。
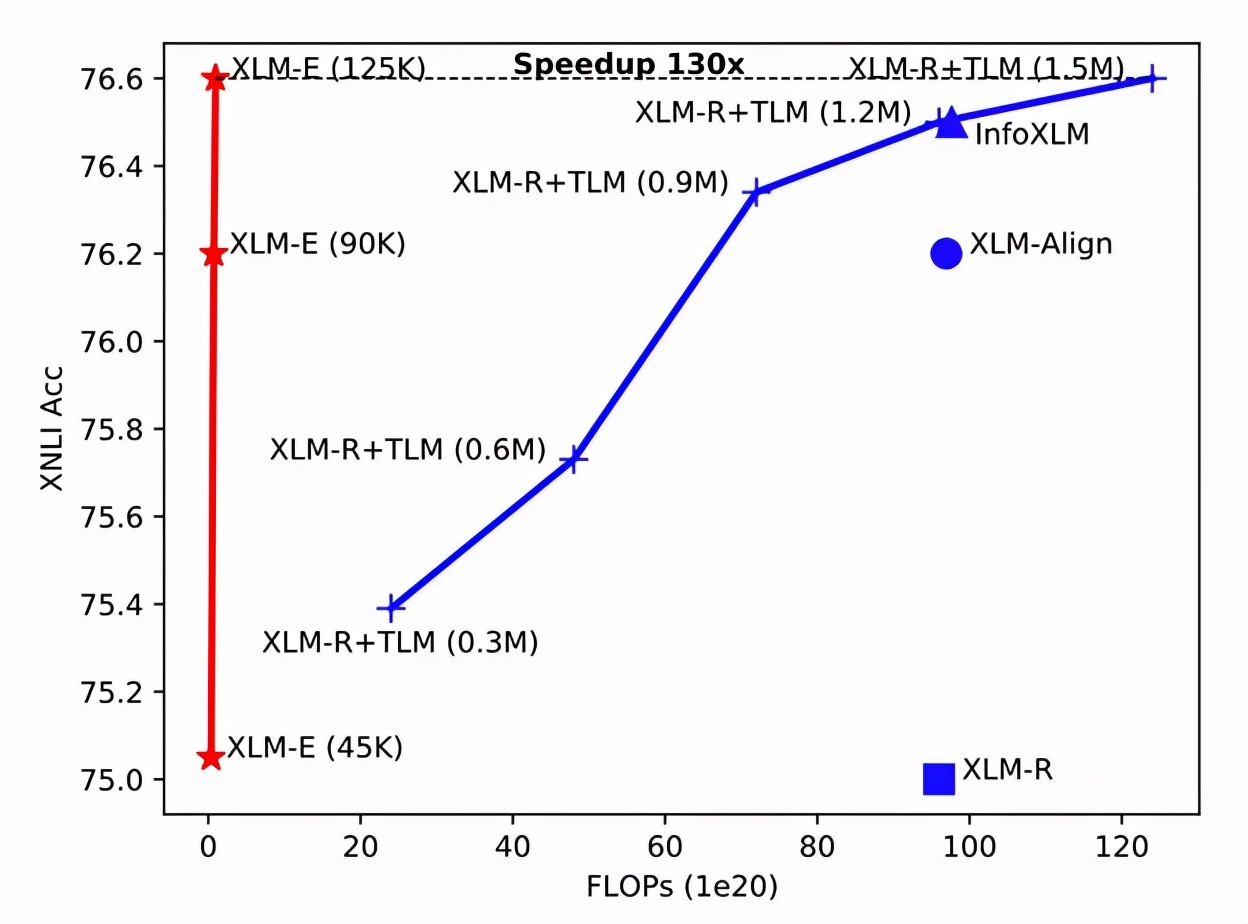
图 4。
多语言训练数据
T-ULRv5 性能的改进,一部分来自更好的训练数据和更大的词汇量。训练一个支持 94 种语言、具有 22 亿参数的模型,需要高数量、高质量的数据集。在多语言语料库中,许多语料是来自网络,从而使得语料库在高资源语言和低资源语言之间存在很大的表示差异,特别是在数据量、清洁度和多样性方面。研究人员在数据工程和清理步骤上投入了大量精力,以大规模生成高质量的数据集来支持 T-ULRv5 训练。
扩大词汇量
随着数据集的更新,研究者还构建了一个包含 500000 个 token 的新词汇表,比 T-ULRv2 大两倍,这进一步提高了 T-ULRv5 模型在语言上的性能。关于词汇扩展的工作,感兴趣的读者,可以参考论文《Allocating Large Vocabulary Capacity for Cross-lingual Language Model Pre-training》获得更多细节。

微软表示,研究人员正在探索多语言技术,通过解决诸如缺乏训练数据、语言建模的高成本以及多语言系统的复杂性等障碍来帮助实现人工智能的简单化。T-ULRv5 是一个重要里程碑,因为其跨语言可迁移性和 zero-shot 应用程序范式为开发跨语言系统提供了一个更高效和可扩展的框架。