近日,国防科技大学徐凯教授团队提出了基于随机优化求解快速移动下的在线 RGB-D 重建方法 ROSEFusion,在无额外硬件辅助的条件下,仅依靠深度信息,实现了最高 4 m/s 线速度、6 rad/s 角速度相机移动下的高精度在线三维重建。
自 2011 年 KinectFusion 问世以来,基于 RGB-D 相机的实时在线三维重建一直是 3D 视觉和图形领域的研究热点。10 年间涌现出了大量优秀的方法和系统。如今,在线 RGB-D 重建已在增强现实、机器人等领域广泛应用,已逐渐发展成为「人 - 机 - 物」 空间智能(Spatial AI)的重要使能技术。
在线 RGB-D 重建的底层技术是 RGB-D SLAM。其中,建图(mapping)部分采用专门适合于实时三维重建的深度图融合(depth fusion)技术。深度图融合一般有基于截断符号距离场(TSDF)的体融合(volumetric fusion)和基于表面片元(surfel)的点云融合(point-based fusion)两种基本方式。而相机跟踪(tracking)部分则一般分为 frame-to-frame 的帧注册方法(包括特征法和直接法)以及 frame-to-model 的 ICP 方法。
目前,一般的在线 RGB-D 重建方法只能处理相机移动较为慢速(如平均线速度 < 0.5 m/s,平均角速度 < 1 rad/s)的情况。过快的相机运动会导致相机跟踪失败,从而产生错误的重建结果。这就非常影响在线三维重建的效率:手持 RGB-D 相机的扫描者必须小心翼翼地移动相机,任何快速移动或抖动都可能让之前的扫描前功尽弃。不支持快速相机移动,也极大限制了在线 RGB-D 重建在机器人、无人机等领域中的实际应用。
快速相机移动下的在线 RGB-D 重建主要面临两个方面的挑战。首先,SO(3)中的相机姿态跟踪涉及非线性最小二乘优化,采用梯度下降法求解时,线性化近似的前提是前后两帧之间的旋转量较小,快速相机移动中的大角度旋转会增加问题的非线性程度,容易让优化陷入局部最优。其次,快速相机移动(特别是在光线昏暗条件下)会导致 RGB 图像产生严重的运动模糊,从而无法进行可靠的 RGB 特征(或像素)跟踪,这对基于 RGB 的相机跟踪方法(如 ORB-SLAM)是致命的。一个容易想到的办法是借助惯性测量单元(IMU)输出的高帧率的线加速度和角速度来辅助相机跟踪。但是,IMU 的初始化不是很鲁棒,读数会有漂移,更重要的是 IMU 需要与相机进行时间同步和空间标定,这些因素都会带来估计偏差和误差积累,同时也增加了系统的复杂性。
能否在不借助额外硬件的前提下,实现快速相机移动下的在线 RGB-D 重建?近日,国防科技大学徐凯教授团队提出了基于随机优化求解快速移动下的在线 RGB-D 重建方法 ROSEFusion,在无额外硬件辅助的条件下,仅依靠深度信息,实现了最高 4 m/s 线速度、6 rad/s 角速度相机移动下的高精度在线三维重建。
如下展示了快速相机移动情况下的实时在线重建效果(视频未加速)。可以看到,操作者非常快速的摇动相机,导致 RGB 图像运动模糊严重。在这样的情况下,ROSEFusion 仍然可以非常准确、稳定的跟踪相机位姿,并得到准确的三维重建。

ROSEFusion 在不加全局位姿优化和回环检测的情况下,在快速移动 RGB-D 序列上达到了 SOTA 的相机跟踪和三维重建精度,在普通速度序列上与以往性能最佳方法(包含全局位姿优化)的精度相当。该工作发表于 SIGGRAPH 2021。

- 论文链接:https://arxiv.org/abs/2105.05600
- 代码和数据集链接:https://github.com/jzhzhang/ROSEFusion
1、基本思想
该工作基于一个基本观察:快速相机移动虽然会带来 RGB 图像的运动模糊,但对深度图像的影响较小。快速移动对深度图的影响往往表现为在前景和背景过渡处的深度值过测量(overshoot)或欠测量(undershoot),而非全幅图像的像素深度值混合[1]。对于上述遮挡边界处的假信号,可以基于硬件很容易地检测和去除(很多深度相机已实现)[2],其结果呈现为:遮挡边界处的深度值为空(见图 1)。既然如此,很自然地考虑仅基于深度图实现相机跟踪。不过,面向深度图的特征点检测与匹配工作相对较少,因为深度图特征点的判别力和鲁棒性远不如 RGB 图像特征点。

图 1:快速相机移动导致 RGB 图像(左)出现严重运动模糊的情况下,对应的深度图(右)仅在遮挡边界处出现了空洞,但并未出现全幅图像的像素模糊。
在非线性优化求解相机位姿方面,既然梯度下降法不能很好地处理大角度旋转,ROSEFusion 采用随机优化方法。据了解,这是领域内首个基于随机优化的在线 RGB-D 重建方法。随机优化算法的基本过程就是不断地对解空间进行随机采样,评估每个采样解的最优性(也称适应性,fittness),再根据它们的适应性引导下一轮的采样。因此,适应性函数和采样策略是随机优化算法的两个重要方面。一个好的适应性函数应该对解的最优性判别力强且计算开销小。一个好的采样策略应该能让采样尽快覆盖最优解。
2、基于 depth-to-TSDF 的适应性函数
为了最小化运动模糊带来的影响,ROSEFusion 基于深度图实现相机跟踪。因此,适应性函数也要基于深度图计算。一种直观想法是计算相邻两帧的深度图的匹配和注册。然而,深度图往往带有噪声,深度图特征点的判别力和鲁棒性较低;而且快速相机移动下准确的重投影匹配关系难以计算,不利于进行帧间匹配和注册。ROSEFusion 采用 depth-to-TSDF 的适应性函数计算方法。给定当前深度图
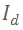
,深度相机的候选相机位姿
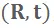
,对应的观察似然函数为:
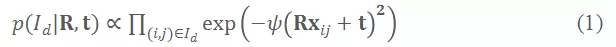
其中
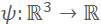
为当前的 TSDF 场,对于全局坐标系下的一个 3D 点
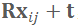
,其 TSDF 值越接近 0 则说明该点越靠近重建表面。采用极大似然估计的方法优化
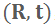
,取公式 (1) 的负对数,得到如下优化目标:
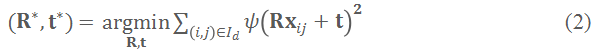
其中
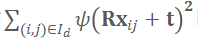
即为候选相机位姿
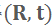
的适应性函数,它度量了当前深度图
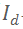
与当前 TSDF 场的符合性(conformality)。参见图 2 的直观示意图。这是一种纯几何(与 RGB 无关)的位姿适应性度量,且无需计算帧间的匹配和注册。
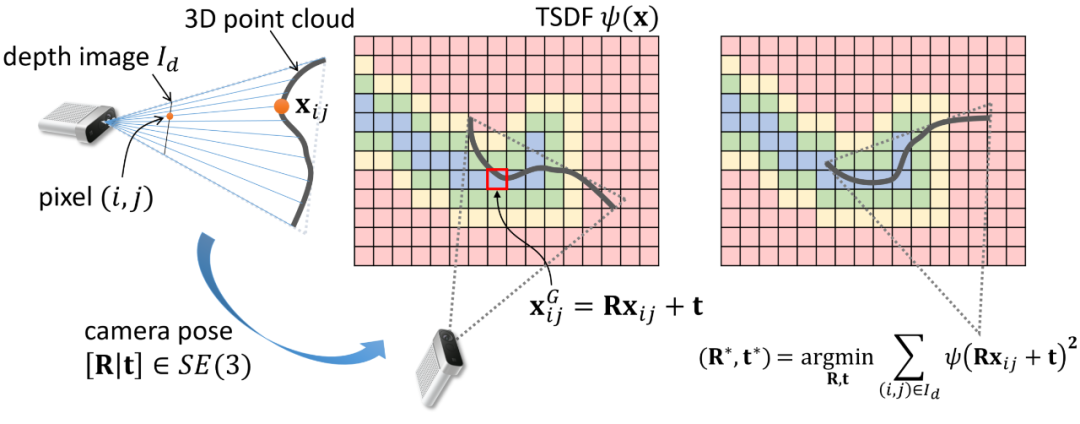
图 2:基于 depth-to-TSDF 的相机位姿适应性(最优性)计算:深度图对应的 3D 点云经过相机位姿变换后,在 TSDF 场中取值的总和。
3、基于随机优化的相机位姿跟踪
粒子滤波优化(Particle Filter Optimization, PFO)是近年来提出的基于粒子滤波思想设计的随机优化算法[3]。粒子滤波是非常著名的状态估计算法,它依据序列观察,通过重要性采样来最大化观察似然,以模拟状态的真实分布。早年的很多 SLAM 算法都基于滤波方法[4]。但需要指出的是,本文涉及的粒子滤波优化,是一个优化器,而非状态估计算法。直观上讲,在本文方法中,每一帧的相机位姿优化涉及若干次粒子重采样(滤波迭代步),而在传统基于粒子滤波的 SLAM 算法中,每一帧的姿态估计对应一次粒子重采样。如图 3 所示,在 ROSEFusion 中,SLAM 的每一帧(下标为 t)位姿优化涉及若干次粒子滤波优化迭代(下标为 k)。
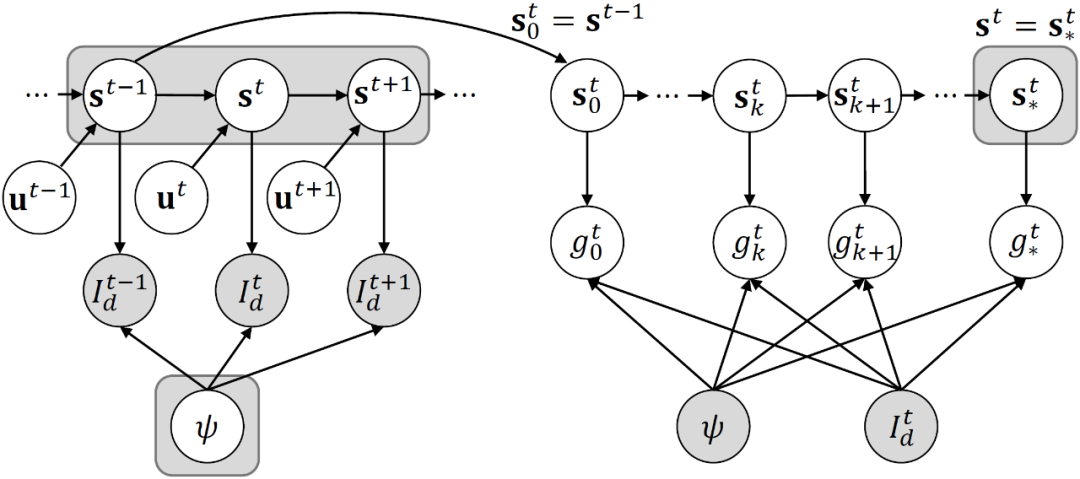
图 3:ROSEFusion 的概率图模型:左半部为 SLAM 的概率图模型,右半部为某一帧相机位姿的粒子滤波优化过程。基于粒子滤波的 SLAM 是面向连续帧的序列位姿估计,而 ROSEFusion 中的粒子滤波优化则是面向某一帧位姿的序列迭代优化。
粒子滤波优化的过程如下:以前一帧的相机位姿为中心,在 SE(3)空间中采样大量 6D 位姿作为粒子:

初始权重均为 1。每次迭代中,首先根据粒子的权重进行重采样,然后依据动力学模型
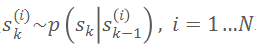
驱动粒子移动,再根据观察似然更新粒子权重:
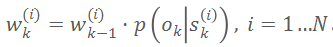
。重复上述步骤直至最优位姿被粒子群覆盖或达到最大迭代次数。上述似然函数
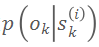
即为前述适用性函数。
然而,粒子滤波优化涉及到大量粒子的采样和权重更新,计算开销较高,难以满足在线重建的实时性要求。此外,如何设置一个好的动力学模型
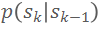
是提高优化效率的关键。为此,本文结合粒子群智(particle swarm intelligence)来改进滤波优化方法,充分利用粒子群中的当前最优解来引导粒子的移动,实现基于粒子群智的动力学模型。同时,为避免大量粒子采样与更新的计算开销,论文提出预采样的粒子群模板(Particle Swarm Template, PST):预先采样一个粒子集,以群智为引导,通过不断移动和缩放粒子集,来达到驱动粒子覆盖最优解的目的。图 4 和图 5 给出了预采样的粒子群模板及其移动、缩放的示意图。
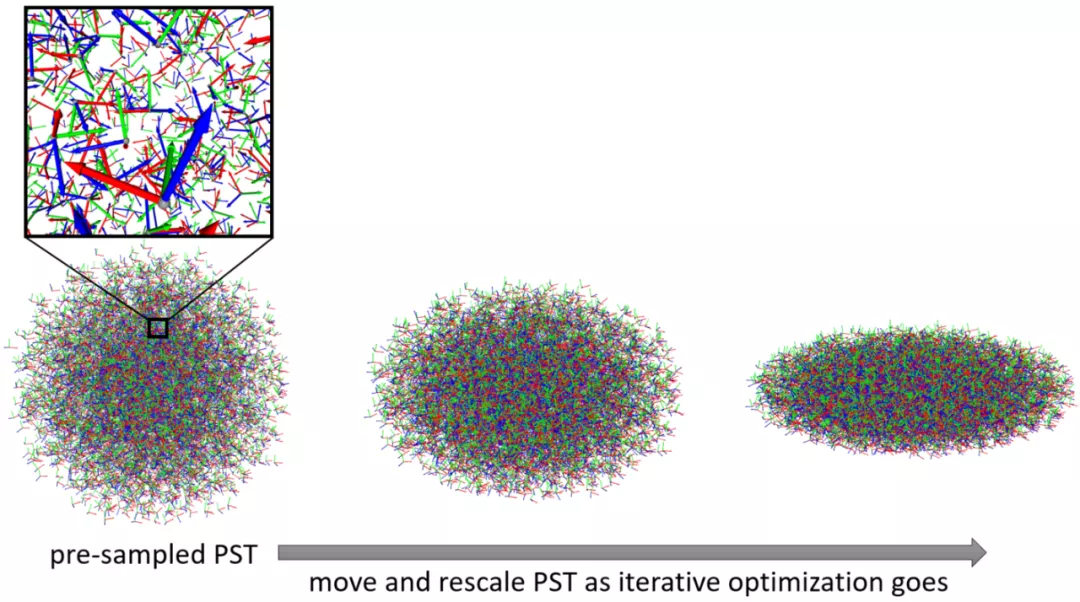
图 4:预采样的粒子群模板(PST)及其随迭优化代移动和缩放的示意图
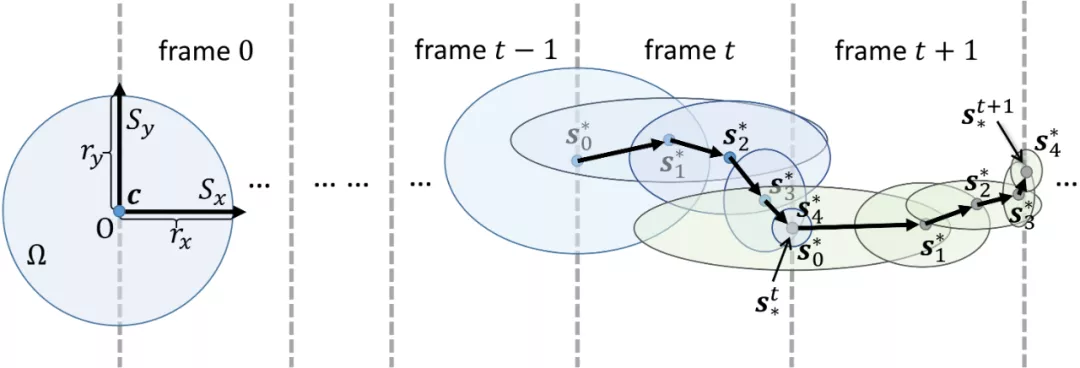
图 5:对于每一帧的相机位姿优化,粒子群模板都要经过若干次移动和缩放,直至收敛到覆盖最优解或达到最大迭代次数
在第k步迭代中,首先将 PST 整体移动到上一步适应性最高的粒子所在的位置,然后缩放 PST 椭球使其轴长
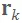
满足(见图 6):
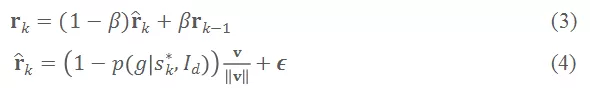

其中,
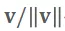
代表了 PST 椭球的各向异性程度,而
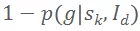
代表了 PST 椭球的尺度。直观上讲,v为相邻两步最优解之间的位移向量。因此,PST 椭球会沿着最优解出现的方向进行更大范围的搜索;并且这个搜索范围和上一步的最高适应性成反比,这使得算法越接近最优解则搜索范围越小,更容易收敛。公式 (3) 借鉴了随机梯度下降中的动量更新(momentum update)机制。
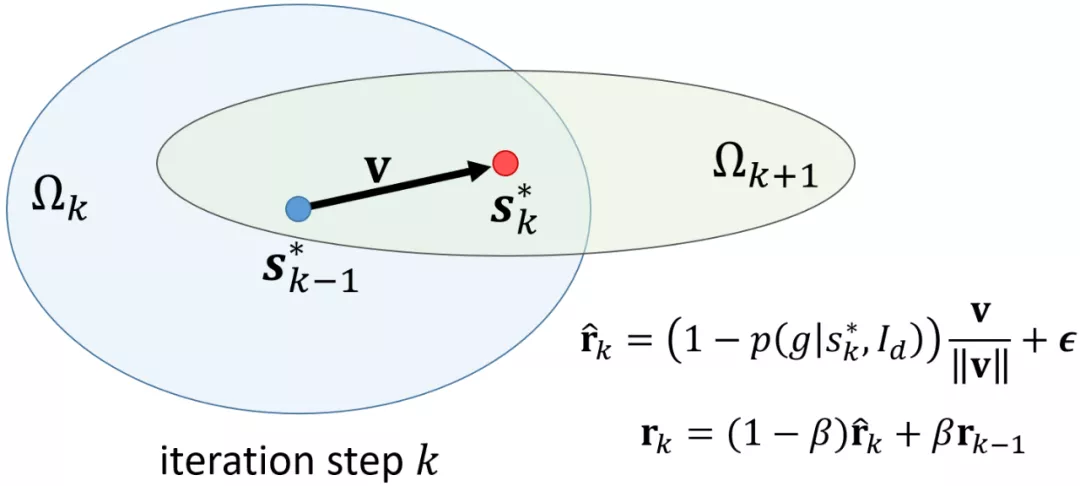
图 6:每一个迭代步的粒子群模板移动和缩放,其中缩放采用了动量更新机制
下面的视频给出了深度图位姿优化过程的可视化,包括目标函数的优化(右上角)和 PST 的更新(右下角)。该视频仅可视化了 PST 的各向异性程度(椭球的形状)和 PST 中位姿的朝向分布(椭球的颜色),PST 的尺度则体现在右上角圆的半径。从中可以看出,目标函数的非凸性严重,而 ROSEFusion 可以很鲁棒地收敛到最优位姿。
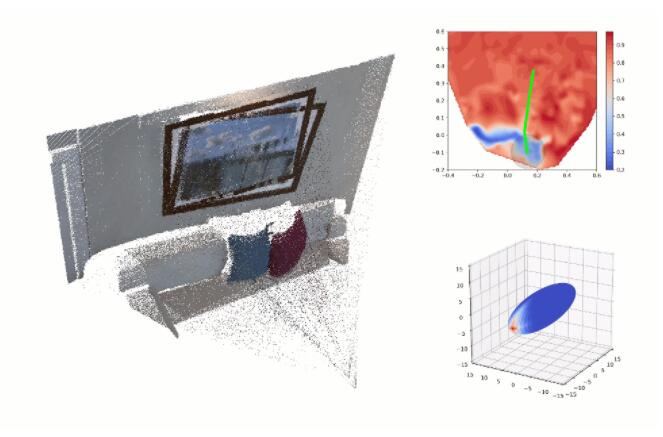
在实现中,PST 和 TSDF 都存储在 GPU 中,每个粒子的适应性计算在 GPU 中并行完成,计算效率很高,每次迭代的计算时间约为 1 ms,每帧大约需要 20~30 次迭代。而 CPU 仅负责 PST 的移动和缩放参数的计算。这也最小化了 CPU 与 GPU 之间的数据交换量。
4、实验结果与评测
现有的在线 RGB-D 重建公开数据集很少包含快速相机移动的 RGB-D 序列。因此,该文提出了首个面向快速相机运动的 RGB-D 序列数据集 FastCaMo。该数据集分为合成和真实两个部分:合成数据集 FastCaMo-Synth 基于 Facebook 开源的 Replica 室内场景数据集构建,作者合成了快速移动的相机轨迹,并渲染了 RGB 和深度图,同时对 RGB 图像添加了合成运动模糊,对深度图添加了合成噪声;真实数据集 FastCaMo-Real 包含了作者用 Kinect DK 扫描的 12 个不同场景的 24 个 RGB-D 序列,由于相机速度较快,难以获得高质量的相机轨迹作为真值,作者采用激光扫描仪获取了场景的完整三维重建,通过度量三维重建的完整性和准确性来评价相机跟踪的准确性。FastCaMo 数据集的相机速度最快达到了线速度 4.6 m/s、角速度 5.7 rad/s,远超以往任何公开数据集。
论文在 FastCaMo 上对比了两个重要的在线 RGB-D 重建方法 BundleFusion[5]和 ElasticFusion[6]。结果如图 7 和图 8 所示。可以看出,ROSEFusion 的轨迹精度、重建质量(包括完整性和准确性)都显著高于其它两个方法。值得注意的是,ROSEFusion 是在无全局位姿优化、无回环检测、不丢弃任何一帧的情况下达到这样的性能的。
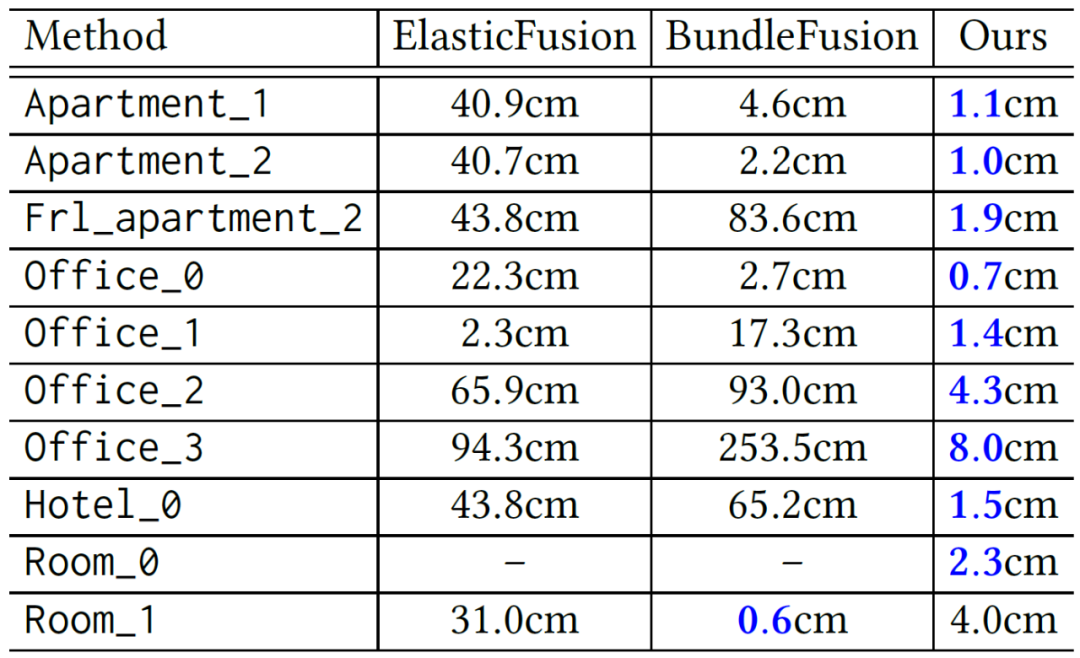
图 7:在 FastCaMo-Synth 快速序列上的相机轨迹精度(ATE)对比(蓝色为最佳)。
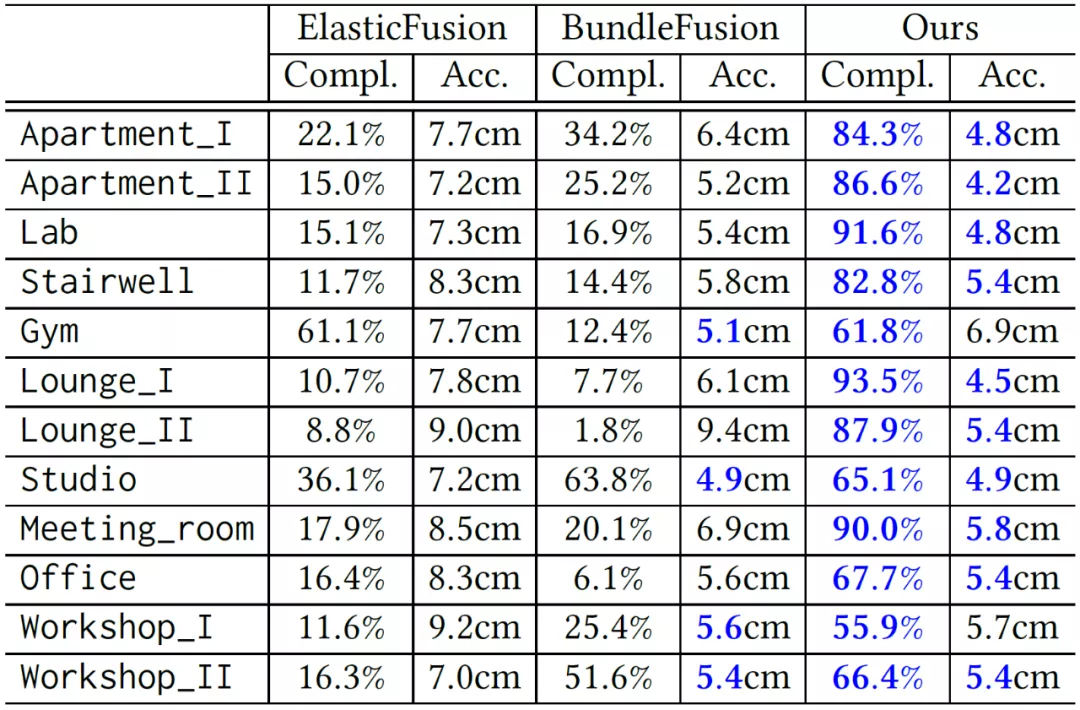
图 8:在 FastCaMo-Real 快速序列上的重建质量(完整性和准确性)对比(蓝色为最佳)。
公开数据集 ETH3D[7]包含了三个快速相机移动的 RGB-D 序列(camera_shake),图 9 给出了在这三个序列上的不同方法的对比,ROSEFusion 在全部序列上取得了最佳相机跟踪效果。
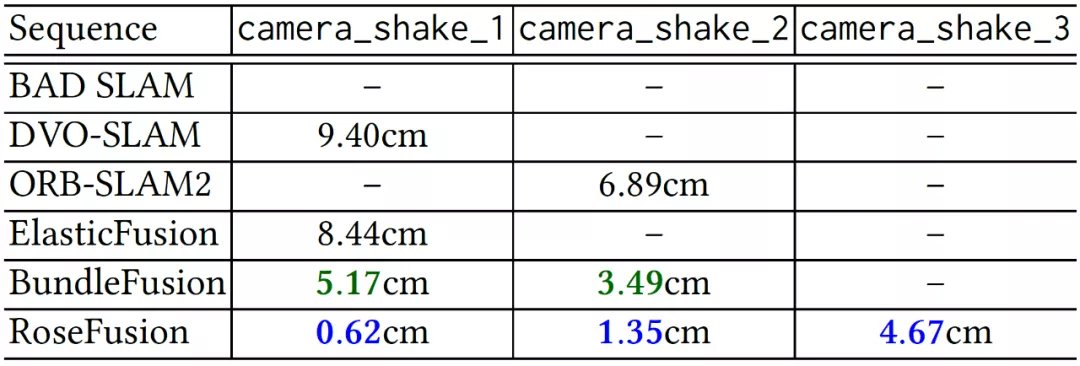
图 9:在 ETH3D 的 camera_shake 序列上的相机轨迹精度(ATE)对比(蓝色为最佳)。
图 10 为 camera_shake_3 序列的重建效果对比,以及相机轨迹精度曲线(不同位姿精度下的帧占比)。
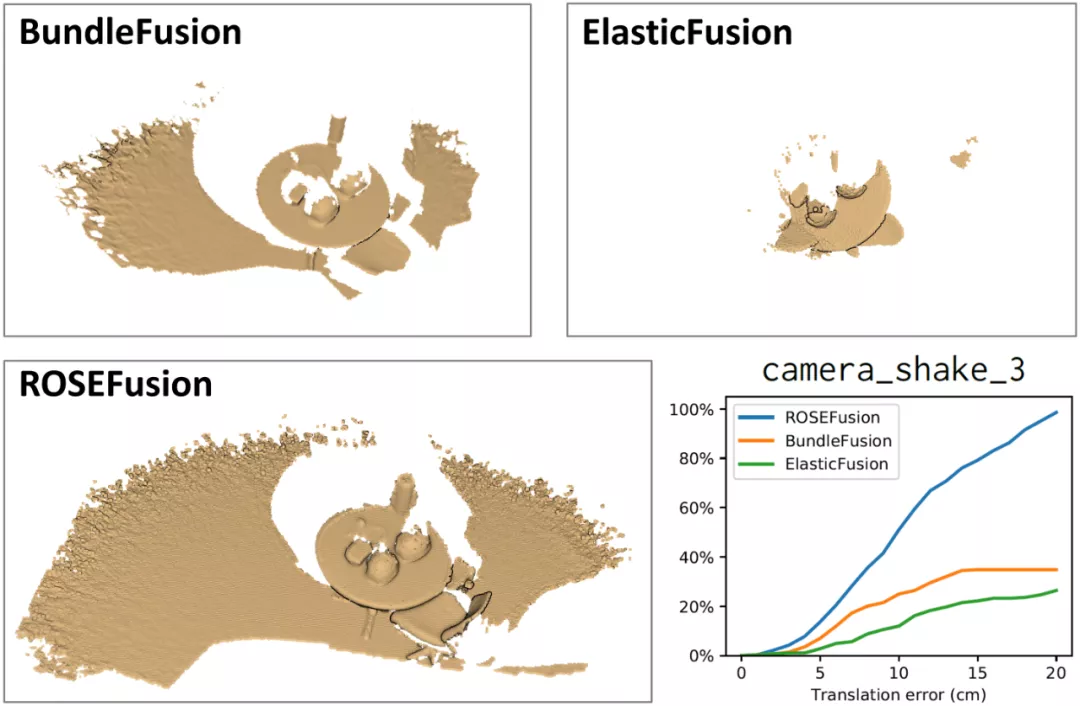
图 10:在 ETH3D camera_shake_3 序列上的重建效果和相机跟踪精度(ATE)对比。
在普通速度的 RGB-D 序列上,ROSEFusion 也能达到与当前最佳算法相当的相机跟踪精度(图 11)。SOTA 算法一般都包含了全局位姿优化,而 ROSEFusion 没有。
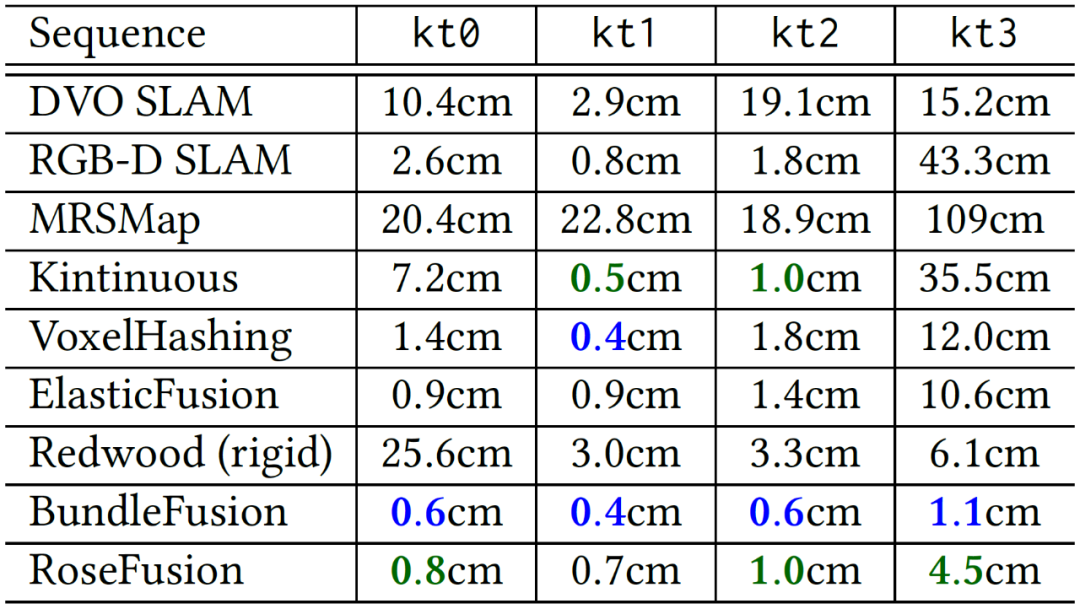
图 11:在 ICL-NUIM 数据集的普通速度序列上的相机轨迹精度(ATE)对比(蓝色为最佳,绿色次之)。
图 12 给出了位姿优化过程中 PST 的 2D 可视化,该图对比了基于 PST 的粒子滤波优化(本文方法)、粒子群优化算法(Particle Swarm Optimization, PSO)以及普通的粒子滤波优化(无 PST)的优化过程。可以看出,基于 PST 的粒子滤波优化在快速探索最优解的速度和收敛性方面具有明显优势。
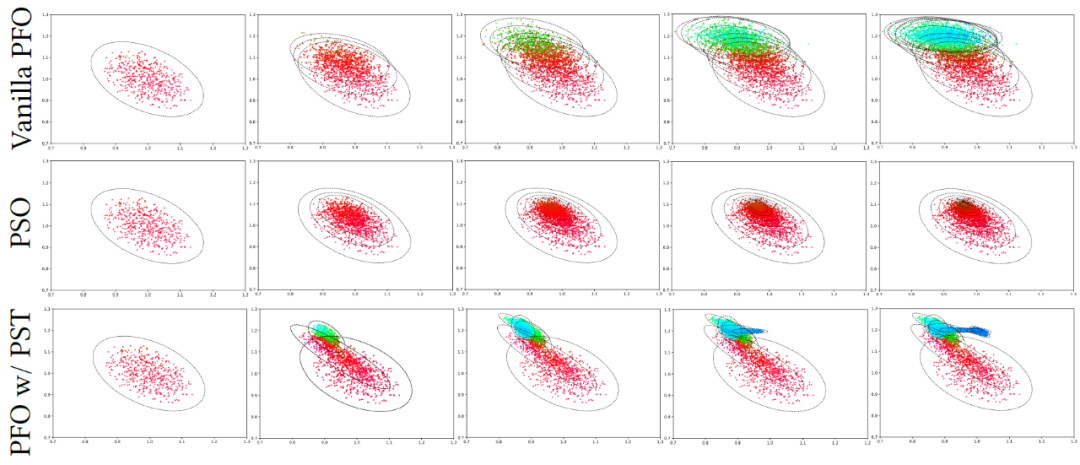
图 12:不同优化方法的 2D 可视化过程对比(蓝色为更优),基于 PST 的粒子滤波优化(第三行)可以快速收敛到更优的解。
如下视频展示了快速扫描一个完整室内场景的过程(视频未加速)。这个序列同样包含了大量快速运动。其中一段扫描过程中,屋子里的灯被部分关闭。由于 ROSEFusion 的优化方法是纯几何的,与 RGB 成像无关,因而可以很鲁棒的处理上述情况。
作者希望通过本文引起领域对面向快速相机移动的 SLAM / 在线重建问题的关注。现有方法一般基于 RGB 图像的特征或像素匹配,采用梯度下降法求解非线性优化问题。由于快速相机运动导致的 RGB 图像运动模糊,大角度旋转优化带来的高度非凸 / 非线性问题,以往方法难以有效实现相机位姿跟踪。ROSEFusion 采用随机优化的方法求解 SLAM 的视觉里程计问题,结合纯几何的适应性函数计算,实现了无 IMU 辅助的快速相机运动在线重建。ROSEFusion 当然可以结合全局位姿优化和回环检测,实现更高质量的三维重建。事实上,后者也很可能可以基于随机优化来实现。