本文转载自微信公众号「微医大前端技术」,作者杨广。转载本文请联系微医大前端技术公众号。
前言
医学检查影像显示里边,调窗是一个基础的常用操作:通过滑动鼠标来改变窗宽窗位的大小,窗宽(宽度)、窗位(中心点)其实就是一个像素数值的区间,图像的所有像素点的像素值在这个区间的就显示,不在区间的就不显示。
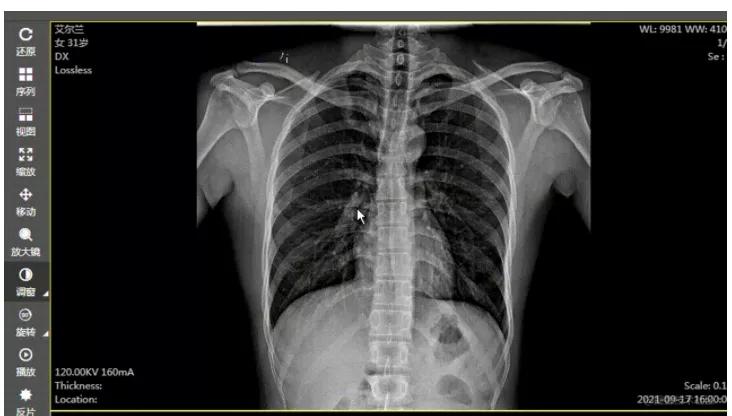
在 web 版阅片器(图像显示工具)的开发工程中发现,在对 dr、dx 这种大图(图像普遍是 2000px 左右宽高的图像,每个像素大小是 16 位或者 32 位的)进行调窗时,浏览器直接卡死,图像显示变化有很大延迟。后来查阅资料,使用 gpujs 来实现调窗时图像的处理,结果:调窗时图像显示变化变得比较线性,性能估计提升 5/6 倍,能满足业务需求。当然,图像的一些高级处理,都是可以用 gpujs 来实现,调窗只是一个点。
使用前效果:
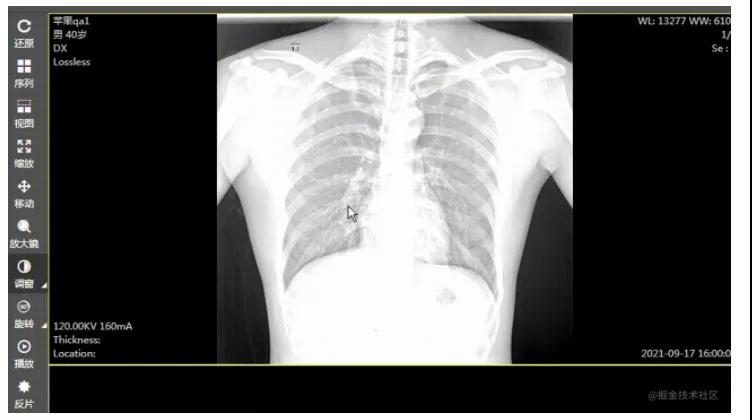
使用后效果:
什么是 GPU.js?
GPU.js 是用于 Web 和 Node.js 中的 GPGPU(GPU 上的通用计算)的 JavaScript 加速库。GPU.js 自动将简单的 JavaScript 函数转换为着色器语言并编译它们,以便它们在您的 GPU 上运行。使用 GPU 执行大规模并行 GPGPU 计算,当 GPU 不可用时,优雅的纯 JavaScript 回退。
GPU,全称 Graphics Processing Unit,即图像处理器,早期主要用于显示图像使用。因为图像处理主要偏简单的矩阵运算,逻辑判断等很少,因此 GPU 的设计跟 CPU 架构不一样,也因此做到一个 GPU 上可以有很多计算单元,可以进行大量并行计算。网上找到一个视频,应该是 Nvidia 某年的产品发布会,形象地演示了 CPU 跟 GPU 的区别。http://v.youku.com/vshow/idXNDcyNTc1MjQ4==.html 。知乎上也有对 CPU 和 GPU 的对比 https://www.zhihu.com/question/19903344
例如用 GPU.js 编写的矩阵乘法(对大小为 512 x 512 的 2 个矩阵执行矩阵乘法)。把计算 512 x 512 矩阵(2D 数组)的单个元素的 javascript 函数转换而来的 GPU 加速内核。内核函数在 GPU 上串联运行,通常会导致非常快速的计算!你可以在这里运行一个基准测试。通常,它的运行速度会快 1-15 倍,具体取决于您的硬件。
由于架构设计不一样,GPU 很适合做简单的并发计算,应用于图像处理、深度学习等领域能大大加快速度。当然直接用 gpu 去开发程序很难编写,一般都是由特殊编译器将代码编译成可以在 gpu 上执行的代码。本文提到的 gpu.js 就是在前端将 js 的一个子集编译成能在 webgl 上执行的一个编译器。更多使用场景 demo 请参照官网 https://gpu.rocks/#/examples。
在使用上遇到的坑
使用 npm 引入 gpu.js 包,发现项目运行不起来,可能和机器有关系,后来改成直接用 browser 方式引入 js 文件
我们是使用 canvas 方式来直接输出像素数据的,对不同大小的图像要使用不同大小的 canvas,使用同一个 canvas 会有些像素清不掉,试用了其他方法清除:没有起到效果
canvas 方式像素数据的原点位置,原点是在左下角
创建内核,内核里边的函数或者自定义函数,在打包过程中被压缩、简化处理后会出现问题:被转换后的某些运算符 gpu.js 不支持。所以 js 的压缩转化规则要做具体的设置
因为每个设备的 gpu 特性不一样,使用 gpujs 库可能有未知异常,总之加上 try { } catch () { 普通处理 cpu } 能解决大多数问题。
- # 在 index.html 中引入 gpu.js
- <script type="text/javascript" src="./static/gpu-browser.min.js"></script>
- # 开始使用
- var gpu = new GPU();
- gpu.addFunction(function1) # 添加自定义函数
- gpu.addFunction(function12) # 添加自定义函数
- # 创建 Kernel
- var kernel = gpu.createKernel(function(参数 1,参数 2,...) {
- # 调窗实现算法
- #
- #
- #
- },
- {
- graphical: true,
- output: outputsize
- })
- # 执行 Kernel
- kernel(入参数 1,入参数 2,...);
- var canvasRender = kernel.canvas;
- # 直接显示 canvasRender, ....
官方使用场景 demo
地址:https://gpu.rocks/#/examples
An example with the shiny new v2 of GPU.js, "Cosmic Jellyfish"

A simple example to load an image into GPU.js.

GPU Accelerated Heatmap using GPU.js
A simple example wherein colors slowly fade in and fade out.

Browser
- <script src="dist/gpu-browser.min.js"></script>
- <script>
- // GPU is a constructor and namespace for browser
- const gpu = new GPU();
- const multiplyMatrix = gpu.createKernel(function(a, b) {
- let sum = 0;
- for (let i = 0; i < 512; i++) {
- sum += a[this.thread.y][i] * b[i][this.thread.x];
- }
- return sum;
- }).setOutput([512, 512]);
- const c = multiplyMatrix(a, b);
- </script>
Node
- const { GPU } = require('gpu.js');
- const gpu = new GPU();
- const multiplyMatrix = gpu.createKernel(function(a, b) {
- let sum = 0;
- for (let i = 0; i < 512; i++) {
- sum += a[this.thread.y][i] * b[i][this.thread.x];
- }
- return sum;
- }).setOutput([512, 512]);
- const c = multiplyMatrix(a, b);
示例
在本例中,两个 512x512 矩阵(二维数组)相乘。计算是在 GPU 上并行完成的。
1.生成矩阵
- const generateMatrices = () => {
- const matrices = [[], []]
- for (let y = 0; y < 512; y++){
- matrices[0].push([])
- matrices[1].push([])
- for (let x = 0; x < 512; x++){
- matrices[0][y].push(Math.random())
- matrices[1][y].push(Math.random())
- }
- }
- return matrices
- }
2.创建“内核”
- const gpu = new GPU();
- const multiplyMatrix = gpu.createKernel(function(a, b) {
- let sum = 0;
- for (let i = 0; i < 512; i++) {
- sum += a[this.thread.y][i] * b[i][this.thread.x];
- }
- return sum;
- }).setOutput([512, 512])
3.以矩阵为参数调用内核
- const matrices = generateMatrices()
- const out = multiplyMatrix(matrices[0], matrices[1])
4.输出矩阵
console.log(out[y][x]) // Logs the element at the xth row and the yth column of the matrix
console.log(out[10][12]) // Logs the element at the 10th row and the 12th column of the output matri
小结
gpu.js 是在前端将 js 的一个子集编译成能在 webgl 上执行的一个编译器,简单、实用,能快速出结果,在对性能要求高、又耗时的运算可以考虑使用 gpu.js 来实现。
参考资料
官网 https://gpu.rocks/#/
github https://github.com/gpujs/gpu.js
更多例子 https://gpu.rocks/#/examples
杨广: 微医前端技术部前端工程师。有志成为一名全栈开发工程师甚至架构师,路漫漫,吾求索。生活中通过健身释放压力,思考问题。