













本文转载自微信公众号「运维开发故事」,作者没有文案的夏老师。转载本文请联系运维开发故事公众号。
问题描述
环境 :ubuntu18.04,自建集群k8s 1.18 ,容器运行时docker。
现象:某个Node频繁NotReady,kubectl describe该Node,出现“PLEG is not healthy: pleg was last seen active 3m46.752815514s ago; threshold is 3m0s”错误,频率在5-10分钟就会出现一次。
我们首先要明白PLEG是什么?
PLEG 全称叫 Pod Lifecycle Event Generator,即 Pod 生命周期事件生成器。实际上它只是 Kubelet 中的一个模块,主要职责就是通过每个匹配的 Pod 级别事件来调整容器运行时的状态,并将调整的结果写入缓存,使 Pod 的缓存保持最新状态。先来聊聊 PLEG 的出现背景。在 Kubernetes 中,每个节点上都运行着一个守护进程 Kubelet 来管理节点上的容器,调整容器的实际状态以匹配 spec 中定义的状态。具体来说,Kubelet 需要对两个地方的更改做出及时的回应:
- Pod spec 中定义的状态
- 容器运行时的状态
对于 Pod,Kubelet 会从多个数据来源 watch Pod spec 中的变化。对于容器,Kubelet 会定期(例如,10s)轮询容器运行时,以获取所有容器的最新状态。随着 Pod 和容器数量的增加,轮询会产生不可忽略的开销,并且会由于 Kubelet 的并行操作而加剧这种开销(为每个 Pod 分配一个 goruntine,用来获取容器的状态)。轮询带来的周期性大量并发请求会导致较高的 CPU 使用率峰值(即使 Pod 的定义和容器的状态没有发生改变),降低性能。最后容器运行时可能不堪重负,从而降低系统的可靠性,限制 Kubelet 的可扩展性。为了降低 Pod 的管理开销,提升 Kubelet 的性能和可扩展性,引入了 PLEG,改进了之前的工作方式:
- 减少空闲期间的不必要工作(例如 Pod 的定义和容器的状态没有发生更改)。
- 减少获取容器状态的并发请求数量。
所以我们看这一切都离不开kubelet与pod的容器运行时。
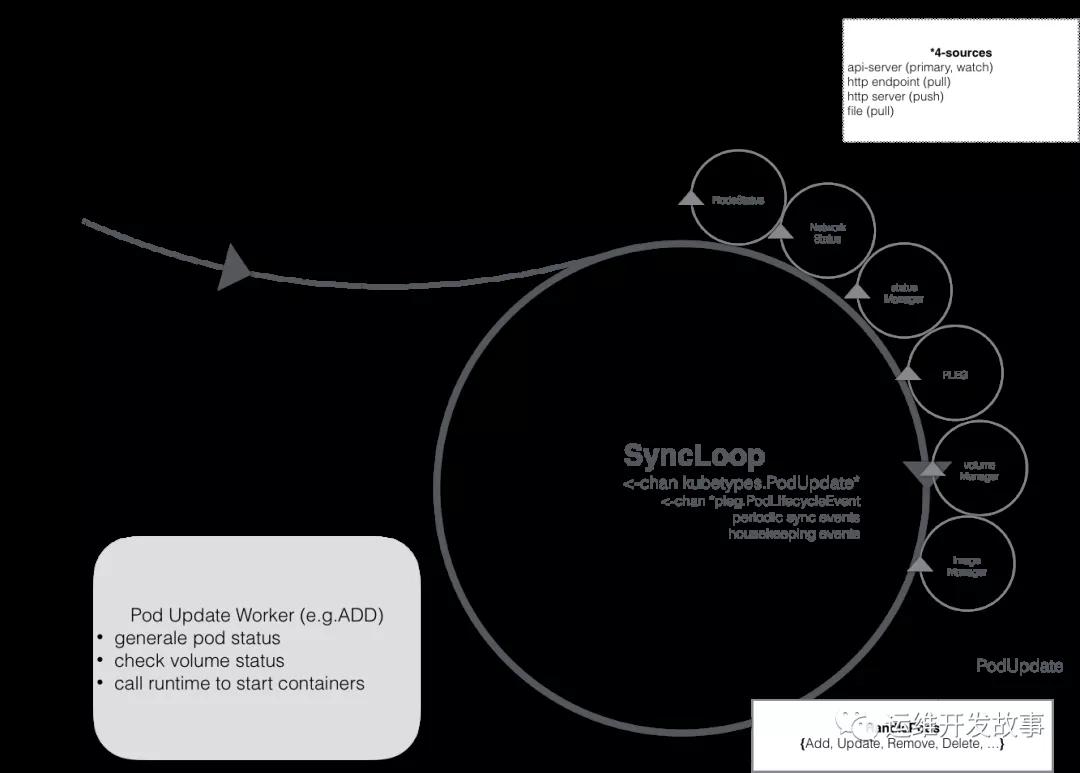
一方面,kubelet扮演的是集群控制器的角色,它定期从API Server获取Pod等相关资源的信息,并依照这些信息,控制运行在节点上Pod的执行;
另外一方面,kubelet作为节点状况的监视器,它获取节点信息,并以集群客户端的角色,把这些状况同步到API Server。在这个问题中,kubelet扮演的是第二种角色。Kubelet会使用上图中的NodeStatus机制,定期检查集群节点状况,并把节点状况同步到API Server。而NodeStatus判断节点就绪状况的一个主要依据,就是PLEG。
PLEG是Pod Lifecycle Events Generator的缩写,基本上它的执行逻辑,是定期检查节点上Pod运行情况,如果发现感兴趣的变化,PLEG就会把这种变化包装成Event发送给Kubelet的主同步机制syncLoop去处理。但是,在PLEG的Pod检查机制不能定期执行的时候,NodeStatus机制就会认为,这个节点的状况是不对的,从而把这种状况同步到API Server。
整体的工作流程如下图所示,虚线部分是 PLEG 的工作内容。
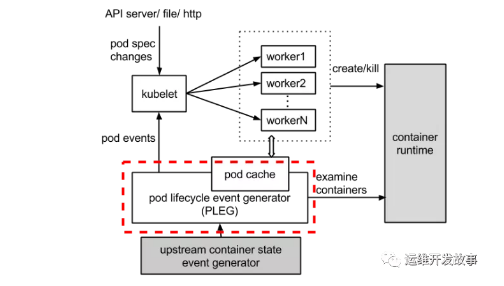
以node notready 这个场景为例,来讲解PLEG:
Kubelet中的NodeStatus机制会定期检查集群节点状况,并把节点状况同步到API Server。而NodeStatus判断节点就绪状况的一个主要依据,就是PLEG。
PLEG定期检查节点上Pod运行情况,并且会把pod 的变化包装成Event发送给Kubelet的主同步机制syncLoop去处理。但是,在PLEG的Pod检查机制不能定期执行的时候,NodeStatus机制就会认为这个节点的状况是不对的,从而把这种状况同步到API Server,我们就会看到 not ready 。
PLEG有两个关键的时间参数,一个是检查的执行间隔,另外一个是检查的超时时间。以默认情况为准,PLEG检查会间隔一秒,换句话说,每一次检查过程执行之后,PLEG会等待一秒钟,然后进行下一次检查;而每一次检查的超时时间是三分钟,如果一次PLEG检查操作不能在三分钟内完成,那么这个状况,会被NodeStatus机制当做集群节点NotReady的凭据,同步给API Server。
PLEG Start就是启动一个协程,每个relistPeriod(1s)就调用一次relist,根据最新的PodStatus生成PodLiftCycleEvent。relist是PLEG的核心,它从container runtime中查询属于kubelet管理containers/sandboxes的信息,并与自身维护的 pods cache 信息进行对比,生成对应的 PodLifecycleEvent,然后输出到 eventChannel 中,通过 eventChannel 发送到 kubelet syncLoop 进行消费,然后由 kubelet syncPod 来触发 pod 同步处理过程,最终达到用户的期望状态。
PLEG is not healthy的原因
这个报错清楚地告诉我们,容器 runtime 是不正常的,且 PLEG 是不健康的。这里容器 runtime 指的就是 docker daemon 。Kubelet 通过操作 docker daemon 来控制容器的生命周期。而这里的 PLEG,指的是 pod lifecycle event generator。PLEG 是 kubelet 用来检查 runtime 的健康检查机制。这件事情本来可以由 kubelet 使用 polling 的方式来做。但是 polling 有其高成本的缺陷,所以 PLEG 应用而生。PLEG 尝试以一种“中断”的形式,来实现对容器 runtime 的健康检查,虽然实际上,它同时用了 polling 和”中断”这样折中的方案。
从 Docker 1.11 版本开始,Docker 容器运行就不是简单通过 Docker Daemon 来启动了,而是通过集成 containerd、runc 等多个组件来完成的。虽然 Docker Daemon 守护进程模块在不停的重构,但是基本功能和定位没有太大的变化,一直都是 CS 架构,守护进程负责和 Docker Client 端交互,并管理 Docker 镜像和容器。现在的架构中组件 containerd 就会负责集群节点上容器的生命周期管理,并向上为 Docker Daemon 提供 gRPC 接口。
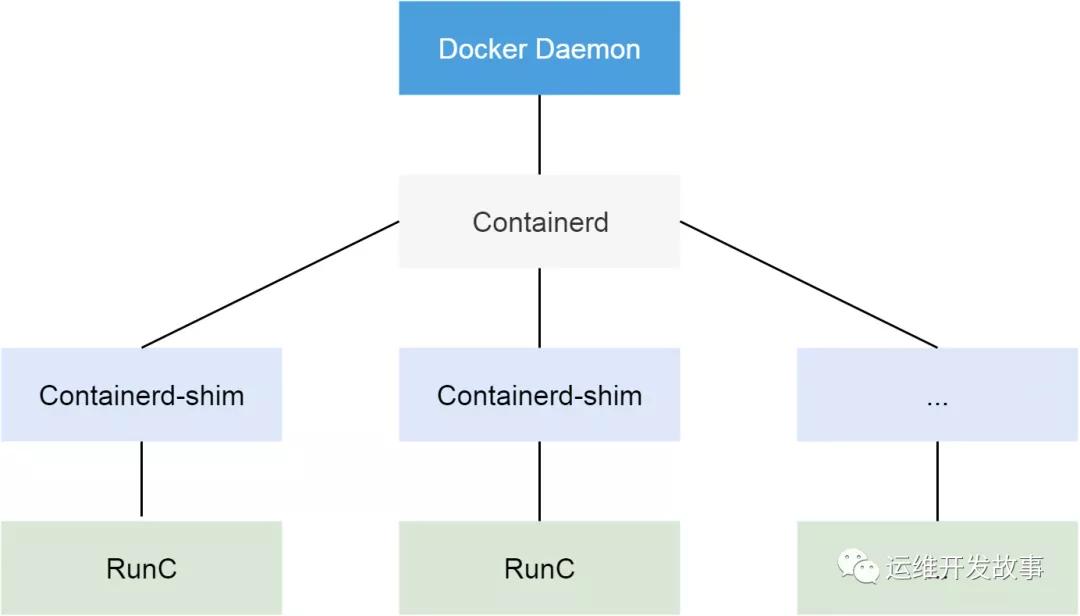
PLEG在每次迭代检查中会调用runc的 relist() 函数干的事情,是定期重新列出节点上的所有容器,并与上一次的容器列表进行对比,以此来判断容器状态的变换。相当于docker ps来获取所有容器,在通过docker Inspect来获取这些容器的详细信息。在有问题的节点上,通过 docker ps命令会没有响应,这说明上边的报错是准确的。
经常出现的场景
出现 pleg not healthy,一般有以下几种可能:
- 容器运行时无响应或响应超时,如 docker进程响应超时(比较常见)
- 该节点上容器数量过多,导致 relist 的过程无法在 3 分钟内完成
- relist 出现了死锁,该 bug 已在 Kubernetes 1.14 中修复。
- 网络
排查处理过程描述
1.我们在问题节点上执行top,发现有进程名为scope的进程cpu占用率一直是100%。通过翻阅资料得知 systemd.scope:范围(scope)单元并不通过单元文件进行配置, 而是仅能以编程的方式通过 systemd D-Bus 接口创建。范围单元的名称都以 ".scope" 作为后缀。与服务(service)单元不同,范围单元用于管理 一组外部创建的进程, 它自身并不派生(fork)任何进程。范围(scope)单元的主要目的在于以分组的方式管理系统服务的工作进程。2.在继续执行在有问题的节点上,通过 docker ps命令会没有响应。说明容器 runtime也是有问题的。那容器 runtime与systemd有不有关系呢?3.我们通过查阅到阿里的一篇文章,阿里巴巴 Kubernetes 集群问题排查思路和方法。找到了关系,有兴趣的可以根据文末提供的链接去细致了解。以下是在该文章中截取的部分内容。
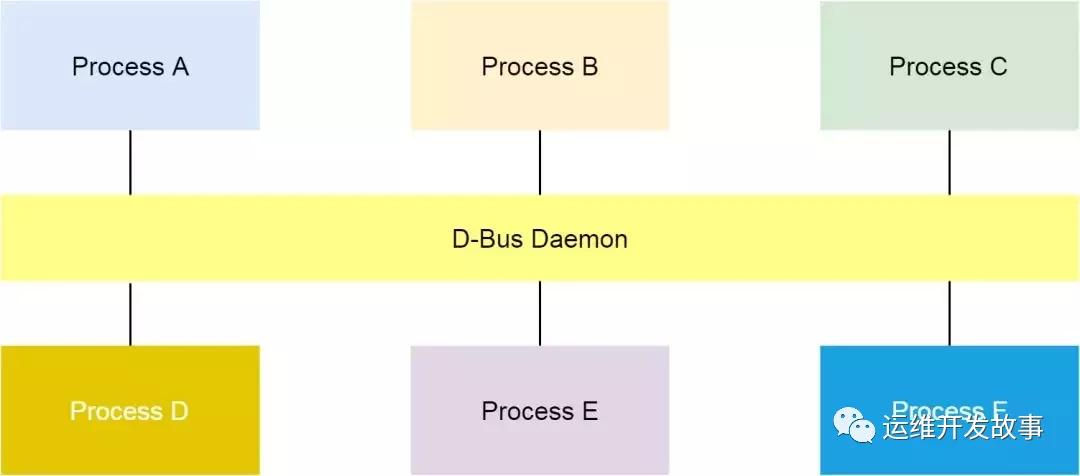
什么是D-Bus呢?
通过阿里巴巴 Kubernetes 集群问题排查思路和方法[1]中如下描述:在 Linux 上,dbus 是一种进程间进行消息通信的机制。
RunC 请求 D-Bus
容器 runtime 的 runC 命令,是 libcontainer 的一个简单的封装。这个工具可以用来管理单个容器,比如容器创建和容器删除。在上节的最后,我们发现 runC 不能完成创建容器的任务。我们可以把对应的进程杀掉,然后在命令行用同样的命令启动容器,同时用 strace 追踪整个过程。
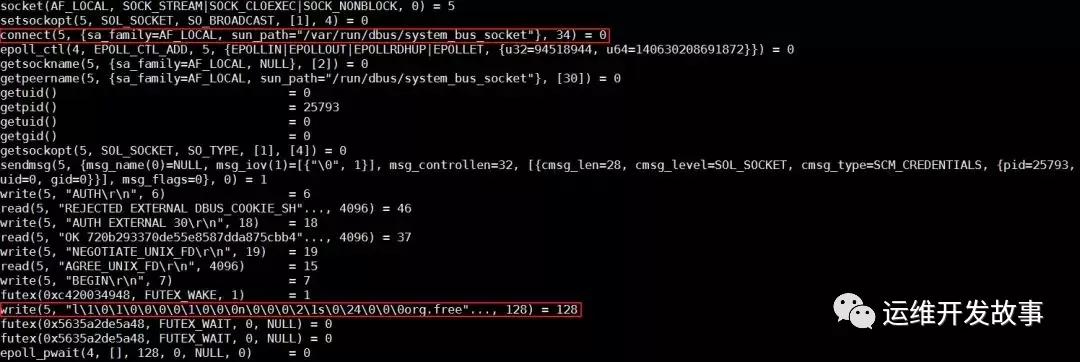
分析发现,runC 停在了向带有 org.free 字段的 dbus socket 写数据的地方。
解决问题
最后可以断定是systemd的问题,我们用 systemctl daemon-reexec 来重启 systemd,问题消失了。所以更加确定是systemd的问题。
具体原因大家可以参考:https://www.infoq.cn/article/t_ZQeWjJLGWGT8BmmiU4这篇文章。
根本上解决问题是:将systemd升级到 v242-rc2,升级后需要重启操作系统。(https://github.com/lnykryn/systemd-rhel/pull/322)
总结
PLEG is not healthy的问题居然是因为systemd导致的。最后通过将systemd升级到 v242-rc2,升级后需要重启操作系统。(https://github.com/lnykryn/systemd-rhel/pull/322) 参考资料
- Kubelet: Pod Lifecycle Event Generator (PLEG)
- Kubelet: Runtime Pod Cache
- relist() in kubernetes/pkg/kubelet/pleg/generic.go
- Past bug about CNI — PLEG is not healthy error, node marked NotReady
- https://www.infoq.cn/article/t_ZQeWjJLGWGT8BmmiU4
- https://cloud.tencent.com/developer/article/1550038


















