












本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
NLP的新秀prompt,最近着实有点火。

还跨界火到了VLM(Visual-Language model,视觉语言模型)。
像OpenAI的CLIP,和南洋理工大学的CoOp都用了这种思路。
现在,清华副教授刘知远团队最新发布的视觉语言模型论文中,也提出了一种基于prompt的新方法。

据论文表示,这也是首次将prompt用于cross-model和零样本/少样本学习视觉定位中。
从目前的NLP和VLM模型来看,不少基于prompt的模型效果都不错,让搞CV的同学们也有点心动——能不能给我们也整一个?
那么,prompt究竟好在哪,应用于图像端后是否也能收获不错的效果?
一起来看看。
与微调差别在哪?
最初,在NLP模型还不太大的时候,大家会采用“预训练+微调(fine-tune)”的方式设计针对特定任务的模型。
这种模式下,研究人员会预先训练出一个效果比较好的模型,再在保留大部分模型参数的情况下,根据特定任务(下游任务)调整部分参数,使得它在这一任务上达到最好的效果。
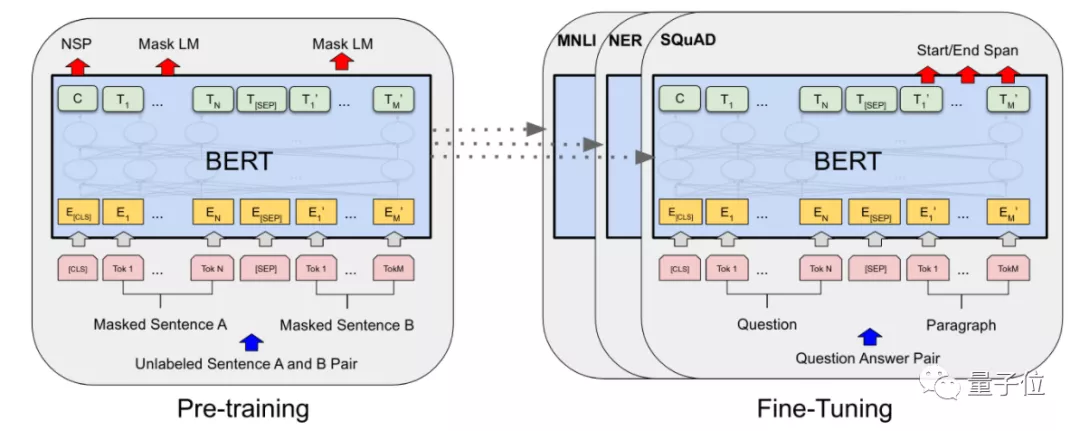
△例如以BERT作为预训练模型
然而,随着预训练模型变得越来越大,微调的代价(训练时间、需求的数据量等)也在增加,研究人员有点吃不消了,开始找更好的方法。
prompt就在这个时候出现了,只不过它这次是针对下游任务进行调整。
它有点像是一种输入模板,用来给预训练模型“做出提示”,预训练模型一“看到”它,就知道自己要完成什么任务。
例如,在情感分类任务中,希望预训练模型能体会到输入句子的情绪,并给出形容词来对它分类:
输入“I love this movie.”后,提前给定一个prompt“This movie is [mask]”,让预训练模型一看到它,就明白自己要输出“great/nice”等夸赞的形容词。
这样训练后,预训练模型就能在看到对应prompt时,选出正确的词汇类型,而不是“跑偏”去做别的事情。
由于prompt在NLP领域的应用效果挺好,因此在与NLP相关的VLM模型中,不少研究人员也开始尝试这种方法。
清华将它用到图像端
当然,最初应用prompt的VLM模型,大多也还仍然是将它应用在文本端。
据知乎@陀飞轮介绍,像OpenAI的CLIP、NTU的CoOp这两个VLM模型,prompt应用都与NLP中的PET模型有点像。
从它们的模型设计来看,都能很明显从文本端看出prompt的影子,像CLIP中的“A photo of a [mask]”:
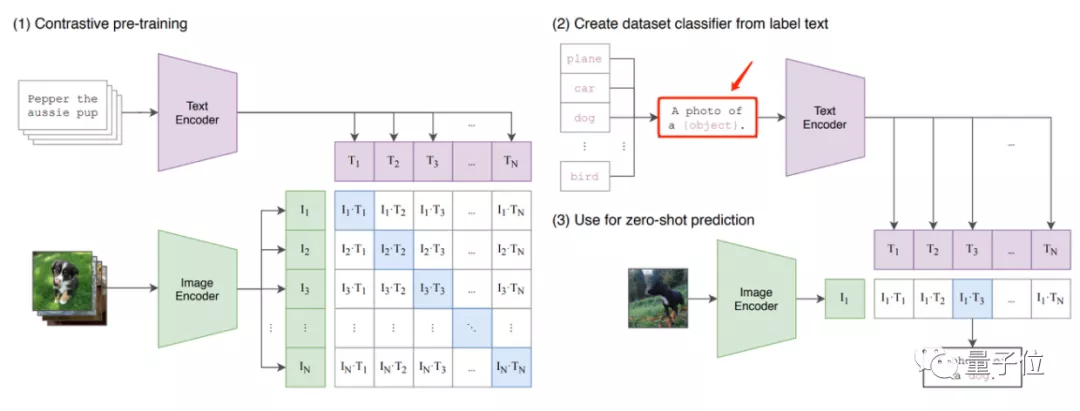
以及CoOp在CLIP上进一步改进的、在训练中能够自行优化的prompt:

这些prompt的应用,整体改进了VLM模型整体的输出效果。
不过,这也基本都是VLM在文本端的应用,prompt到底适不适合被用在图像端上?
最新来自清华刘知远团队的论文中,就尝试着在VLM的图像端中,以涂色的方式建立了一种visual sub-prompts。
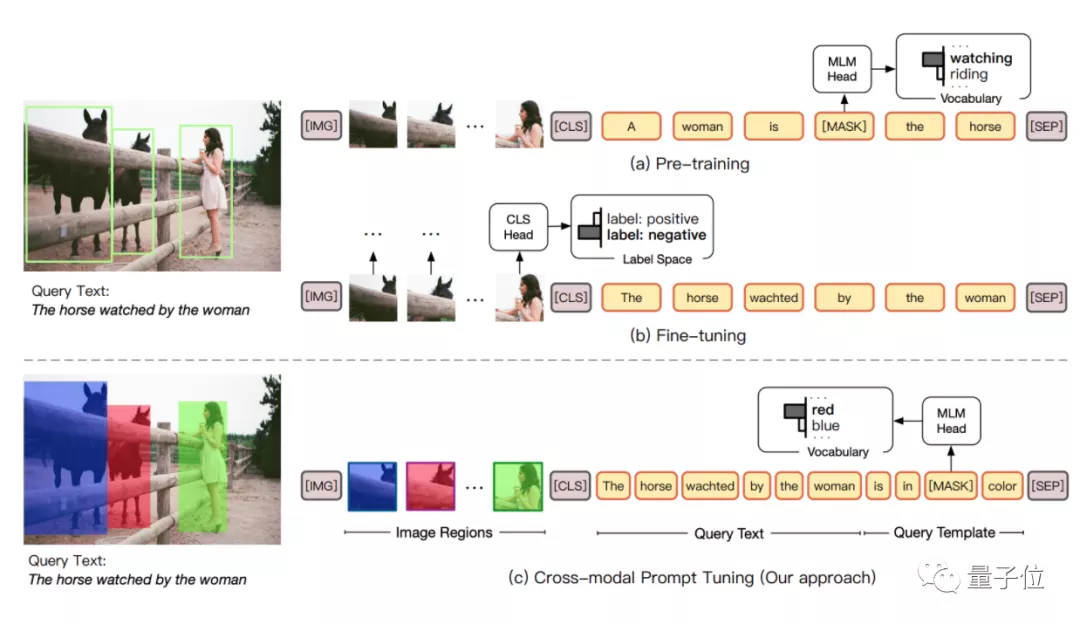
当然,文本端也对应用上了prompt,不过据刘知远老师介绍,prompt在文本端的应用,感觉不足以完全发挥prompt tuning的作用,因此这篇论文尝试了一种cross-modal prompt tuning的方法。
从论文的测试结果来看,这种方法在少样本学习(few-shot)的情况下,基本能取得比微调更好的效果。
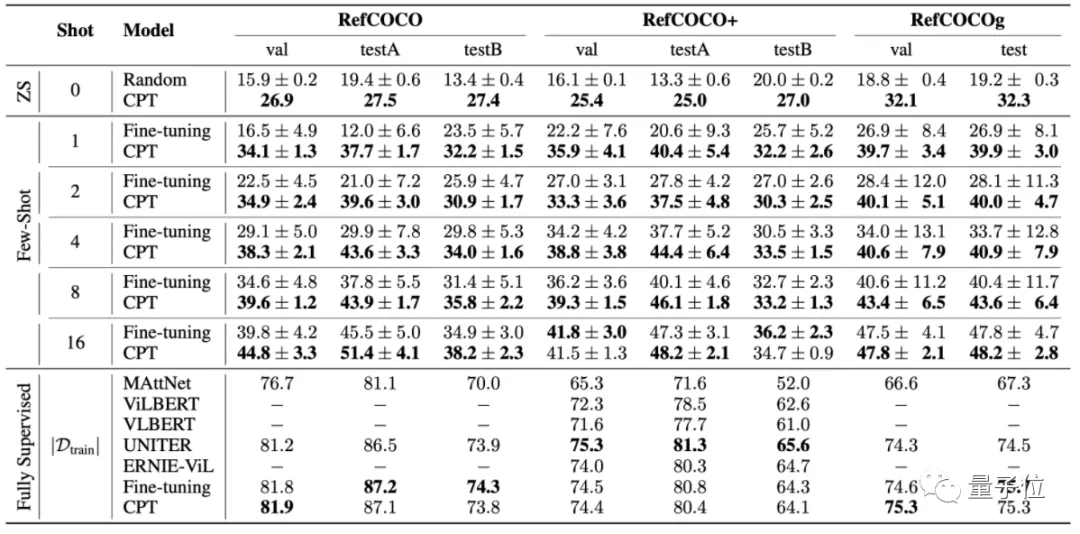
不过,这也还是prompt在VLM上的另一种尝试。
它究竟适不适合用来处理CV领域的图像问题?
CV领域能借鉴吗?
在知乎上,有不少博主给出了自己的看法。
知乎@陀飞轮从方法上给出了两条路径:
如果是纯CV方向的prompt,也就是类似于ViT将图片拆分patch,每个patch实际上可以看成一个字符,那么也可以设计patch的prompt对模型进行训练,这其中也可以分成生成式(类似ViT)和判别式(类似self-supervised)两种方法。
知乎@yearn则认为,就目前来看,continuous prompt是最有可能transfer到CV领域的一系列工作。最近transformer准备大一统CV,NLP,将image输入转化为patch的形式,也让研究人员更方便借鉴NLP的方法学习prompt。
当然,@yearn也表示,要想真正将prompt应用到CV领域,还存在两个需要解决的难题:
1、CV还不存在BERT,GPT这样具有统治力的预训练模型,因此近期内可能很难将prompt 做few-shot learning这一套搬过来。
2、CV的downstream task更加复杂,感觉检测,分割这类任务要把prompt调work是一个非常大的工作量。
但也有匿名用户直接认为,图像上只能用非常别扭的方法做一些任务。当然,视频反而可能应用得更好。

那么,你认为prompt能应用在CV领域吗?
刘知远团队最新论文:
https://arxiv.org/abs/2109.11797
知乎回答(已授权):
@陀飞轮:https://www.zhihu.com/question/487096135/answer/2127127513
@yearn:https://www.zhihu.com/question/487096135/answer/2124603834




















